







十、 二叉堆之Java的实现
1) 概要
前面分别通过C和C++实现了二叉堆,本章给出二叉堆的Java版本。还是那句话,它们的原理一样,择其一了解即可。
目录
1. 二叉堆的介绍
2. 二叉堆的图文解析
3. 二叉堆的Java实现(完整源码)
4. 二叉堆的Java测试程序
2) 二叉堆的介绍
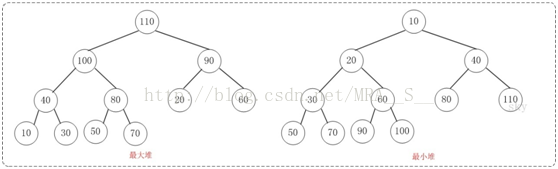
二叉堆是完全二元树或者是近似完全二元树,按照数据的排列方式可以分为两种:最大堆和最小堆。
最大堆:父结点的键值总是大于或等于任何一个子节点的键值;最小堆:父结点的键值总是小于或等于任何一个子节点的键值。
二叉堆一般都通过"数组"来实现,下面是数组实现的最大堆和最小堆的示意图:
3) 二叉堆的图文解析
图文解析是以"最大堆"来进行介绍的。
最大堆的核心内容是"添加"和"删除",理解这两个算法,二叉堆也就基本掌握了。下面对它们进行介绍,其它内容请参考后面的完整源码。
1. 添加
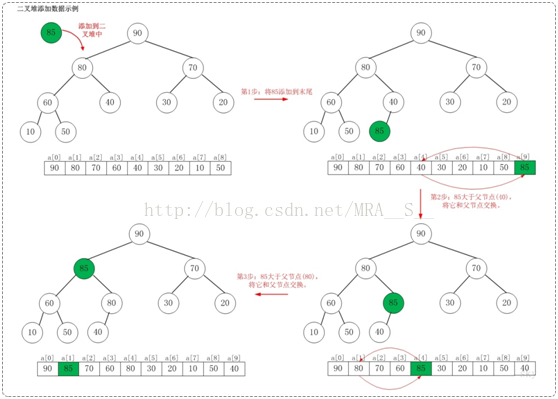
假设在最大堆[90,80,70,60,40,30,20,10,50]种添加85,需要执行的步骤如下:
如上图所示,当向最大堆中添加数据时:先将数据加入到最大堆的最后,然后尽可能把这个元素往上挪,直到挪不动为止!
将85添加到[90,80,70,60,40,30,20,10,50]中后,最大堆变成了[90,85,70,60,80,30,20,10,50,40]。
最大堆的插入代码(Java语言)
/*
* 最大堆的向上调整算法(从start开始向上直到0,调整堆)
*
* 注:数组实现的堆中,第N个节点的左孩子的索引值是(2N+1),右孩子的索引是(2N+2)。
*
* 参数说明:
* start -- 被上调节点的起始位置(一般为数组中最后一个元素的索引)
*/
protected void filterup(int start) {
int c = start; // 当前节点(current)的位置
int p = (c-1)/2; // 父(parent)结点的位置
T tmp = mHeap.get(c); // 当前节点(current)的大小
while(c > 0) {
int cmp = mHeap.get(p).compareTo(tmp);
if(cmp >= 0)
break;
else {
mHeap.set(c, mHeap.get(p));
c = p;
p = (p-1)/2;
}
}
mHeap.set(c, tmp);
}
/*
* 将data插入到二叉堆中
*/
public void insert(T data) {
int size = mHeap.size();
mHeap.add(data); // 将"数组"插在表尾
filterup(size); // 向上调整堆
}
insert(data)的作用:将数据data添加到最大堆中。mHeap是动态数组ArrayList对象。
当堆已满的时候,添加失败;否则data添加到最大堆的末尾。然后通过上调算法重新调整数组,使之重新成为最大堆。
2. 删除
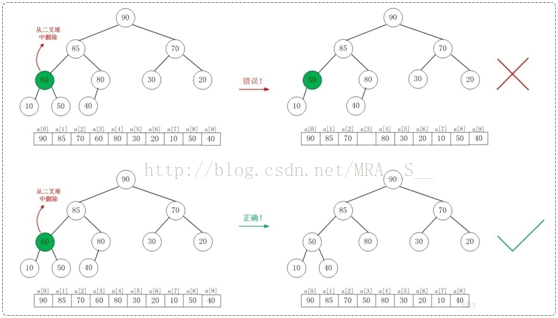
假设从最大堆[90,85,70,60,80,30,20,10,50,40]中删除90,需要执行的步骤如下:
如上图所示,当从最大堆中删除数据时:先删除该数据,然后用最大堆中最后一个的元素插入这个空位;接着,把这个“空位”尽量往上挪,直到剩余的数据变成一个最大堆。
从[90,85,70,60,80,30,20,10,50,40]删除90之后,最大堆变成了[85,80,70,60,40,30,20,10,50]。
注意:考虑从最大堆[90,85,70,60,80,30,20,10,50,40]中删除60,执行的步骤不能单纯的用它的字节点来替换;而必须考虑到"替换后的树仍然要是最大堆"!
二叉堆的删除代码(Java语言)
/*
* 最大堆的向下调整算法
*
* 注:数组实现的堆中,第N个节点的左孩子的索引值是(2N+1),右孩子的索引是(2N+2)。
*
* 参数说明:
* start -- 被下调节点的起始位置(一般为0,表示从第1个开始)
* end -- 截至范围(一般为数组中最后一个元素的索引)
*/
protected void filterdown(int start, int end) {
int c = start; // 当前(current)节点的位置
int l = 2*c + 1; // 左(left)孩子的位置
T tmp = mHeap.get(c); // 当前(current)节点的大小
while(l <= end) {
int cmp = mHeap.get(l).compareTo(mHeap.get(l+1));
// "l"是左孩子,"l+1"是右孩子
if(l < end && cmp<0)
l++; // 左右两孩子中选择较大者,即mHeap[l+1]
cmp = tmp.compareTo(mHeap.get(l));
if(cmp >= 0)
break; //调整结束
else {
mHeap.set(c, mHeap.get(l));
c = l;
l = 2*l + 1;
}
}
mHeap.set(c, tmp);
}
/*
* 删除最大堆中的data
*
* 返回值:
* 0,成功
* -1,失败
*/
public int remove(T data) {
// 如果"堆"已空,则返回-1
if(mHeap.isEmpty() == true)
return -1;
// 获取data在数组中的索引
int index = mHeap.indexOf(data);
if (index==-1)
return -1;
int size = mHeap.size();
mHeap.set(index, mHeap.get(size-1));// 用最后元素填补
mHeap.remove(size - 1); // 删除最后的元素
if (mHeap.size() > 1)
filterdown(index, mHeap.size()-1); // 从index号位置开始自上向下调整为最小堆
return 0;
}
4) 二叉堆的Java实现(完整源码)
二叉堆的实现同时包含了"最大堆"和"最小堆"。
二叉堆(最大堆)的实现文件(MaxHeap.java)
/**
* 二叉堆(最大堆)
*
* @author skywang
* @date 2014/03/07
*/
import java.util.ArrayList;
import java.util.List;
public class MaxHeap<T extends Comparable<T>> {
private List<T> mHeap; // 队列(实际上是动态数组ArrayList的实例)
public MaxHeap() {
this.mHeap = new ArrayList<T>();
}
/*
* 最大堆的向下调整算法
*
* 注:数组实现的堆中,第N个节点的左孩子的索引值是(2N+1),右孩子的索引是(2N+2)。
*
* 参数说明:
* start -- 被下调节点的起始位置(一般为0,表示从第1个开始)
* end -- 截至范围(一般为数组中最后一个元素的索引)
*/
protected void filterdown(int start, int end) {
int c = start; // 当前(current)节点的位置
int l = 2*c + 1; // 左(left)孩子的位置
T tmp = mHeap.get(c); // 当前(current)节点的大小
while(l <= end) {
int cmp = mHeap.get(l).compareTo(mHeap.get(l+1));
// "l"是左孩子,"l+1"是右孩子
if(l < end && cmp<0)
l++; // 左右两孩子中选择较大者,即mHeap[l+1]
cmp = tmp.compareTo(mHeap.get(l));
if(cmp >= 0)
break; //调整结束
else {
mHeap.set(c, mHeap.get(l));
c = l;
l = 2*l + 1;
}
}
mHeap.set(c, tmp);
}
/*
* 删除最大堆中的data
*
* 返回值:
* 0,成功
* -1,失败
*/
public int remove(T data) {
// 如果"堆"已空,则返回-1
if(mHeap.isEmpty() == true)
return -1;
// 获取data在数组中的索引
int index = mHeap.indexOf(data);
if (index==-1)
return -1;
int size = mHeap.size();
mHeap.set(index, mHeap.get(size-1));// 用最后元素填补
mHeap.remove(size - 1); // 删除最后的元素
if (mHeap.size() > 1)
filterdown(index, mHeap.size()-1); // 从index号位置开始自上向下调整为最小堆
return 0;
}
/*
* 最大堆的向上调整算法(从start开始向上直到0,调整堆)
*
* 注:数组实现的堆中,第N个节点的左孩子的索引值是(2N+1),右孩子的索引是(2N+2)。
*
* 参数说明:
* start -- 被上调节点的起始位置(一般为数组中最后一个元素的索引)
*/
protected void filterup(int start) {
int c = start; // 当前节点(current)的位置
int p = (c-1)/2; // 父(parent)结点的位置
T tmp = mHeap.get(c); // 当前节点(current)的大小
while(c > 0) {
int cmp = mHeap.get(p).compareTo(tmp);
if(cmp >= 0)
break;
else {
mHeap.set(c, mHeap.get(p));
c = p;
p = (p-1)/2;
}
}
mHeap.set(c, tmp);
}
/*
* 将data插入到二叉堆中
*/
public void insert(T data) {
int size = mHeap.size();
mHeap.add(data); // 将"数组"插在表尾
filterup(size); // 向上调整堆
}
@Override
public String toString() {
StringBuilder sb = new StringBuilder();
for (int i=0; i<mHeap.size(); i++)
sb.append(mHeap.get(i) +" ");
return sb.toString();
}
public static void main(String[] args) {
int i;
int a[] = {10, 40, 30, 60, 90, 70, 20, 50, 80};
MaxHeap<Integer> tree=new MaxHeap<Integer>();
System.out.printf("== 依次添加: ");
for(i=0; i<a.length; i++) {
System.out.printf("%d ", a[i]);
tree.insert(a[i]);
}
System.out.printf("\n== 最 大 堆: %s", tree);
i=85;
tree.insert(i);
System.out.printf("\n== 添加元素: %d", i);
System.out.printf("\n== 最 大 堆: %s", tree);
i=90;
tree.remove(i);
System.out.printf("\n== 删除元素: %d", i);
System.out.printf("\n== 最 大 堆: %s", tree);
System.out.printf("\n");
}
}
二叉堆(最小堆)的实现文件(MinHeap.java)
/**
* 二叉堆(最小堆)
*
* @author skywang
* @date 2014/03/07
*/
import java.util.ArrayList;
import java.util.List;
public class MinHeap<T extends Comparable<T>> {
private List<T> mHeap; // 存放堆的数组
public MinHeap() {
this.mHeap = new ArrayList<T>();
}
/*
* 最小堆的向下调整算法
*
* 注:数组实现的堆中,第N个节点的左孩子的索引值是(2N+1),右孩子的索引是(2N+2)。
*
* 参数说明:
* start -- 被下调节点的起始位置(一般为0,表示从第1个开始)
* end -- 截至范围(一般为数组中最后一个元素的索引)
*/
protected void filterdown(int start, int end) {
int c = start; // 当前(current)节点的位置
int l = 2*c + 1; // 左(left)孩子的位置
T tmp = mHeap.get(c); // 当前(current)节点的大小
while(l <= end) {
int cmp = mHeap.get(l).compareTo(mHeap.get(l+1));
// "l"是左孩子,"l+1"是右孩子
if(l < end && cmp>0)
l++; // 左右两孩子中选择较小者,即mHeap[l+1]
cmp = tmp.compareTo(mHeap.get(l));
if(cmp <= 0)
break; //调整结束
else {
mHeap.set(c, mHeap.get(l));
c = l;
l = 2*l + 1;
}
}
mHeap.set(c, tmp);
}
/*
* 最小堆的删除
*
* 返回值:
* 成功,返回被删除的值
* 失败,返回null
*/
public int remove(T data) {
// 如果"堆"已空,则返回-1
if(mHeap.isEmpty() == true)
return -1;
// 获取data在数组中的索引
int index = mHeap.indexOf(data);
if (index==-1)
return -1;
int size = mHeap.size();
mHeap.set(index, mHeap.get(size-1));// 用最后元素填补
mHeap.remove(size - 1); // 删除最后的元素
if (mHeap.size() > 1)
filterdown(index, mHeap.size()-1); // 从index号位置开始自上向下调整为最小堆
return 0;
}
/*
* 最小堆的向上调整算法(从start开始向上直到0,调整堆)
*
* 注:数组实现的堆中,第N个节点的左孩子的索引值是(2N+1),右孩子的索引是(2N+2)。
*
* 参数说明:
* start -- 被上调节点的起始位置(一般为数组中最后一个元素的索引)
*/
protected void filterup(int start) {
int c = start; // 当前节点(current)的位置
int p = (c-1)/2; // 父(parent)结点的位置
T tmp = mHeap.get(c); // 当前节点(current)的大小
while(c > 0) {
int cmp = mHeap.get(p).compareTo(tmp);
if(cmp <= 0)
break;
else {
mHeap.set(c, mHeap.get(p));
c = p;
p = (p-1)/2;
}
}
mHeap.set(c, tmp);
}
/*
* 将data插入到二叉堆中
*/
public void insert(T data) {
int size = mHeap.size();
mHeap.add(data); // 将"数组"插在表尾
filterup(size); // 向上调整堆
}
public String toString() {
StringBuilder sb = new StringBuilder();
for (int i=0; i<mHeap.size(); i++)
sb.append(mHeap.get(i) +" ");
return sb.toString();
}
public static void main(String[] args) {
int i;
int a[] = {80, 40, 30, 60, 90, 70, 10, 50, 20};
MinHeap<Integer> tree=new MinHeap<Integer>();
System.out.printf("== 依次添加: ");
for(i=0; i<a.length; i++) {
System.out.printf("%d ", a[i]);
tree.insert(a[i]);
}
System.out.printf("\n== 最 小 堆: %s", tree);
i=15;
tree.insert(i);
System.out.printf("\n== 添加元素: %d", i);
System.out.printf("\n== 最 小 堆: %s", tree);
i=10;
tree.remove(i);
System.out.printf("\n== 删除元素: %d", i);
System.out.printf("\n== 最 小 堆: %s", tree);
System.out.printf("\n");
}
}
5) 二叉堆的Java测试程序
测试程序已经包含在相应的实现文件中了,这里只说明运行结果。
最大堆(MaxHeap.java)的运行结果:
== 依次添加: 10 40 30 60 90 70 20 50 80
== 最 大 堆: 90 80 70 60 40 30 20 10 50
== 添加元素: 85
== 最 大 堆: 90 85 70 60 80 30 20 10 50 40
== 删除元素: 90
== 最 大 堆: 85 80 70 60 40 30 20 10 50
最小堆(MinHeap.java)的运行结果:
== 最 小 堆: 10 20 30 50 90 70 40 80 60
== 添加元素: 15
== 最 小 堆: 10 15 30 50 20 70 40 80 60 90
== 删除元素: 10
== 最 小 堆: 15 20 30 50 90 70 40 80 60
PS. 二叉堆是"堆排序"的理论基石。以后讲解算法时会讲解到"堆排序",理解了"二叉堆"之后,"堆排序"就很简单了。
十一、 左倾堆之Java的实现
1) 概要
前面分别通过C和C++实现了左倾堆,本章给出左倾堆的Java版本。还是那句老话,三种实现的原理一样,择其一了解即可。
目录
1. 左倾堆的介绍
2. 左倾堆的图文解析
3. 左倾堆的Java实现(完整源码)
4. 左倾堆的Java测试程序
2) 左倾堆的介绍
左倾堆(leftist tree 或 leftist heap),又被成为左偏树、左偏堆,最左堆等。
它和二叉堆一样,都是优先队列实现方式。当优先队列中涉及到"对两个优先队列进行合并"的问题时,二叉堆的效率就无法令人满意了,而本文介绍的左倾堆,则可以很好地解决这类问题。
3) 左倾堆的定义
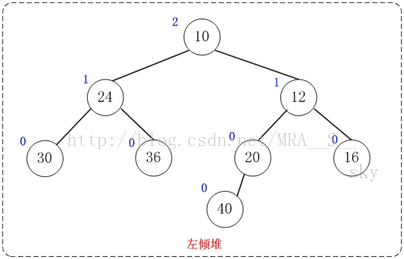
上图是一颗左倾树,它的节点除了和二叉树的节点一样具有左右子树指针外,还有两个属性:键值和零距离。
(01) 键值的作用是来比较节点的大小,从而对节点进行排序。
(02) 零距离(英文名NPL,即Null Path Length)则是从一个节点到一个"最近的不满节点"的路径长度。不满节点是指该该节点的左右孩子至少有有一个为NULL。叶节点的NPL为0,NULL节点的NPL为-1。
左倾堆有以下几个基本性质:
[性质1] 节点的键值小于或等于它的左右子节点的键值。
[性质2] 节点的左孩子的NPL >= 右孩子的NPL。
[性质3] 节点的NPL = 它的右孩子的NPL + 1。
4) 左倾堆的图文解析
合并操作是左倾堆的重点。合并两个左倾堆的基本思想如下:
(01) 如果一个空左倾堆与一个非空左倾堆合并,返回非空左倾堆。
(02) 如果两个左倾堆都非空,那么比较两个根节点,取较小堆的根节点为新的根节点。将"较小堆的根节点的右孩子"和"较大堆"进行合并。
(03) 如果新堆的右孩子的NPL > 左孩子的NPL,则交换左右孩子。
(04) 设置新堆的根节点的NPL = 右子堆NPL + 1
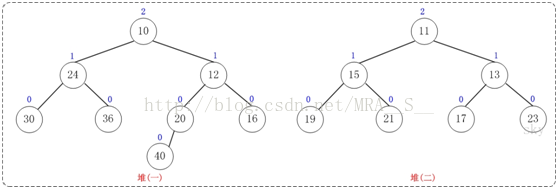
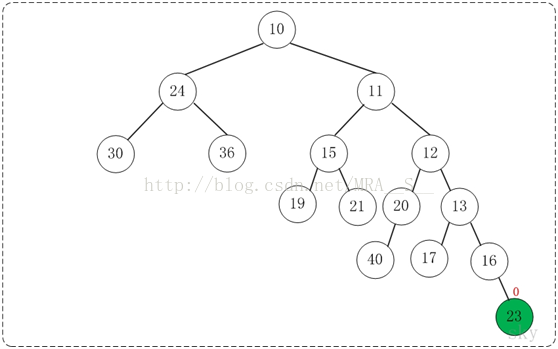
下面通过图文演示合并以下两个堆的过程。
提示:这两个堆的合并过程和测试程序相对应!
第1步:将"较小堆(根为10)的右孩子"和"较大堆(根为11)"进行合并。
合并的结果,相当于将"较大堆"设置"较小堆"的右孩子,如下图所示:
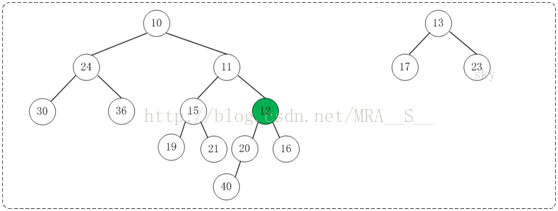
第2步:将上一步得到的"根11的右子树"和"根为12的树"进行合并,得到的结果如下:
第3步:将上一步得到的"根12的右子树"和"根为13的树"进行合并,得到的结果如下:
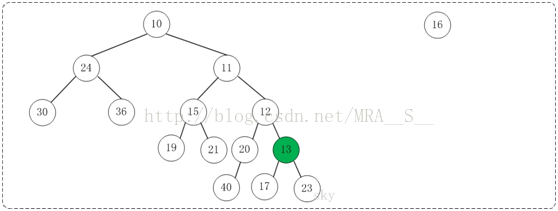
第4步:将上一步得到的"根13的右子树"和"根为16的树"进行合并,得到的结果如下:
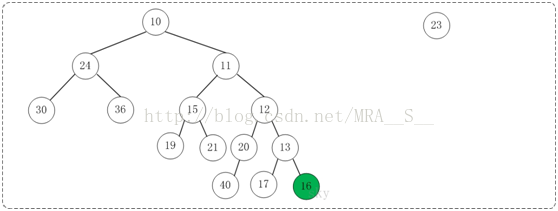
第5步:将上一步得到的"根16的右子树"和"根为23的树"进行合并,得到的结果如下:
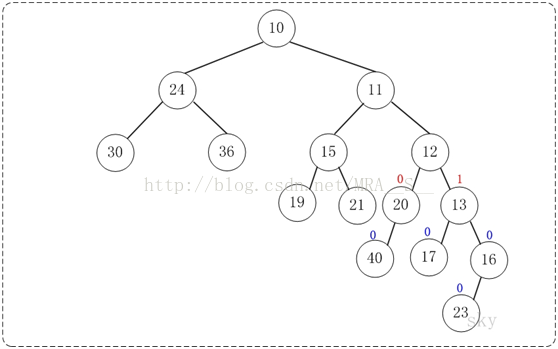
至此,已经成功的将两棵树合并成为一棵树了。接下来,对新生成的树进行调节。
第6步:上一步得到的"树16的右孩子的NPL > 左孩子的NPL",因此交换左右孩子。得到的结果如下:
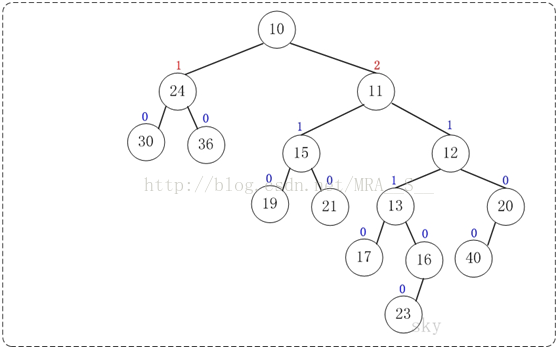
第7步:上一步得到的"树12的右孩子的NPL > 左孩子的NPL",因此交换左右孩子。得到的结果如下:
第8步:上一步得到的"树10的右孩子的NPL > 左孩子的NPL",因此交换左右孩子。得到的结果如下:
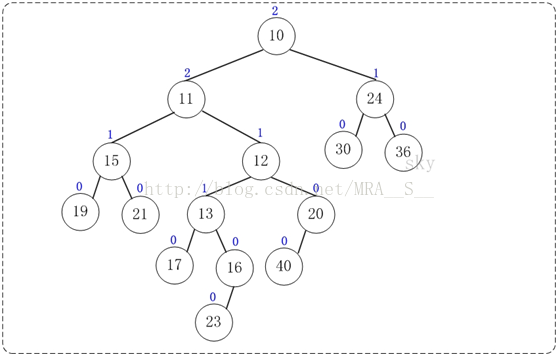
至此,合并完毕。上面就是合并得到的左倾堆!
下面看看左倾堆的基本操作的代码
1. 基本定义
public class LeftistHeap<T extends Comparable<T>> {
private LeftistNode<T> mRoot; // 根结点
private class LeftistNode<T extends Comparable<T>> {
T key; // 关键字(键值)
int npl; // 零路经长度(Null Path Length)
LeftistNode<T> left; // 左孩子
LeftistNode<T> right; // 右孩子
public LeftistNode(T key, LeftistNode<T> left, LeftistNode<T> right) {
this.key = key;
this.npl = 0;
this.left = left;
this.right = right;
}
public String toString() {
return "key:"+key;
}
}
...
}
LeftistNode是左倾堆对应的节点类。
LeftistHeap是左倾堆类,它包含了左倾堆的根节点,以及左倾堆的操作。
2. 合并
/*
* 合并"左倾堆x"和"左倾堆y"
*/
private LeftistNode<T> merge(LeftistNode<T> x, LeftistNode<T> y) {
if(x == null) return y;
if(y == null) return x;
// 合并x和y时,将x作为合并后的树的根;
// 这里的操作是保证: x的key < y的key
if(x.key.compareTo(y.key) > 0) {
LeftistNode<T> tmp = x;
x = y;
y = tmp;
}
// 将x的右孩子和y合并,"合并后的树的根"是x的右孩子。
x.right = merge(x.right, y);
// 如果"x的左孩子为空" 或者 "x的左孩子的npl<右孩子的npl"
// 则,交换x和y
if (x.left == null || x.left.npl < x.right.npl) {
LeftistNode<T> tmp = x.left;
x.left = x.right;
x.right = tmp;
}
if (x.right == null || x.left == null)
x.npl = 0;
else
x.npl = (x.left.npl > x.right.npl) ? (x.right.npl + 1) : (x.left.npl + 1);
return x;
}
public void merge(LeftistHeap<T> other) {
this.mRoot = merge(this.mRoot, other.mRoot);
}
merge(x, y)是内部接口,作用是合并x和y这两个左倾堆,并返回得到的新堆的根节点。
merge(other)是外部接口,作用是将other合并到当前堆中。
3. 添加
/*
* 新建结点(key),并将其插入到左倾堆中
*
* 参数说明:
* key 插入结点的键值
*/
public void insert(T key) {
LeftistNode<T> node = new LeftistNode<T>(key,null,null);
// 如果新建结点失败,则返回。
if (node != null)
this.mRoot = merge(this.mRoot, node);
}
insert(key)的作用是新建键值为key的节点,并将其加入到当前左倾堆中。
4. 删除
/*
* 删除根结点
*
* 返回值:
* 返回被删除的节点的键值
*/
public T remove() {
if (this.mRoot == null)
return null;
T key = this.mRoot.key;
LeftistNode<T> l = this.mRoot.left;
LeftistNode<T> r = this.mRoot.right;
this.mRoot = null; // 删除根节点
this.mRoot = merge(l, r); // 合并左右子树
return key;
}
remove()的作用是删除左倾堆的最小节点。
注意:关于左倾堆的"前序遍历"、"中序遍历"、"后序遍历"、"打印"、"销毁"等接口就不再单独介绍了。后文的源码中有给出它们的实现代码,Please RTFSC(Read The Fucking Source Code)!
5) 左倾堆的Java实现(完整源码)
左倾堆的实现文件(LeftistHeap.java)
/**
* Java 语言: 左倾堆
*
* @author skywang
* @date 2014/03/31
*/
public class LeftistHeap<T extends Comparable<T>> {
private LeftistNode<T> mRoot; // 根结点
private class LeftistNode<T extends Comparable<T>> {
T key; // 关键字(键值)
int npl; // 零路经长度(Null Path Length)
LeftistNode<T> left; // 左孩子
LeftistNode<T> right; // 右孩子
public LeftistNode(T key, LeftistNode<T> left, LeftistNode<T> right) {
this.key = key;
this.npl = 0;
this.left = left;
this.right = right;
}
public String toString() {
return "key:"+key;
}
}
public LeftistHeap() {
mRoot = null;
}
/*
* 前序遍历"左倾堆"
*/
private void preOrder(LeftistNode<T> heap) {
if(heap != null) {
System.out.print(heap.key+" ");
preOrder(heap.left);
preOrder(heap.right);
}
}
public void preOrder() {
preOrder(mRoot);
}
/*
* 中序遍历"左倾堆"
*/
private void inOrder(LeftistNode<T> heap) {
if(heap != null) {
inOrder(heap.left);
System.out.print(heap.key+" ");
inOrder(heap.right);
}
}
public void inOrder() {
inOrder(mRoot);
}
/*
* 后序遍历"左倾堆"
*/
private void postOrder(LeftistNode<T> heap) {
if(heap != null)
{
postOrder(heap.left);
postOrder(heap.right);
System.out.print(heap.key+" ");
}
}
public void postOrder() {
postOrder(mRoot);
}
/*
* 合并"左倾堆x"和"左倾堆y"
*/
private LeftistNode<T> merge(LeftistNode<T> x, LeftistNode<T> y) {
if(x == null) return y;
if(y == null) return x;
// 合并x和y时,将x作为合并后的树的根;
// 这里的操作是保证: x的key < y的key
if(x.key.compareTo(y.key) > 0) {
LeftistNode<T> tmp = x;
x = y;
y = tmp;
}
// 将x的右孩子和y合并,"合并后的树的根"是x的右孩子。
x.right = merge(x.right, y);
// 如果"x的左孩子为空" 或者 "x的左孩子的npl<右孩子的npl"
// 则,交换x和y
if (x.left == null || x.left.npl < x.right.npl) {
LeftistNode<T> tmp = x.left;
x.left = x.right;
x.right = tmp;
}
if (x.right == null || x.left == null)
x.npl = 0;
else
x.npl = (x.left.npl > x.right.npl) ? (x.right.npl + 1) : (x.left.npl + 1);
return x;
}
public void merge(LeftistHeap<T> other) {
this.mRoot = merge(this.mRoot, other.mRoot);
}
/*
* 新建结点(key),并将其插入到左倾堆中
*
* 参数说明:
* key 插入结点的键值
*/
public void insert(T key) {
LeftistNode<T> node = new LeftistNode<T>(key,null,null);
// 如果新建结点失败,则返回。
if (node != null)
this.mRoot = merge(this.mRoot, node);
}
/*
* 删除根结点
*
* 返回值:
* 返回被删除的节点的键值
*/
public T remove() {
if (this.mRoot == null)
return null;
T key = this.mRoot.key;
LeftistNode<T> l = this.mRoot.left;
LeftistNode<T> r = this.mRoot.right;
this.mRoot = null; // 删除根节点
this.mRoot = merge(l, r); // 合并左右子树
return key;
}
/*
* 销毁左倾堆
*/
private void destroy(LeftistNode<T> heap) {
if (heap==null)
return ;
if (heap.left != null)
destroy(heap.left);
if (heap.right != null)
destroy(heap.right);
heap=null;
}
public void clear() {
destroy(mRoot);
mRoot = null;
}
/*
* 打印"左倾堆"
*
* key -- 节点的键值
* direction -- 0,表示该节点是根节点;
* -1,表示该节点是它的父结点的左孩子;
* 1,表示该节点是它的父结点的右孩子。
*/
private void print(LeftistNode<T> heap, T key, int direction) {
if(heap != null) {
if(direction==0) // heap是根节点
System.out.printf("%2d(%d) is root\n", heap.key, heap.npl);
else // heap是分支节点
System.out.printf("%2d(%d) is %2d's %6s child\n", heap.key, heap.npl, key, direction==1?"right" : "left");
print(heap.left, heap.key, -1);
print(heap.right,heap.key, 1);
}
}
public void print() {
if (mRoot != null)
print(mRoot, mRoot.key, 0);
}
}
左倾堆的测试程序(LeftistHeapTest.java)
/**
* Java 语言: 左倾堆
*
* @author skywang
* @date 2014/03/31
*/
public class LeftistHeapTest {
public static void main(String[] args) {
int a[]= {10,40,24,30,36,20,12,16};
int b[]= {17,13,11,15,19,21,23};
LeftistHeap<Integer> ha=new LeftistHeap<Integer>();
LeftistHeap<Integer> hb=new LeftistHeap<Integer>();
System.out.printf("== 左倾堆(ha)中依次添加: ");
for(int i=0; i<a.length; i++) {
System.out.printf("%d ", a[i]);
ha.insert(a[i]);
}
System.out.printf("\n== 左倾堆(ha)的详细信息: \n");
ha.print();
System.out.printf("\n== 左倾堆(hb)中依次添加: ");
for(int i=0; i<b.length; i++) {
System.out.printf("%d ", b[i]);
hb.insert(b[i]);
}
System.out.printf("\n== 左倾堆(hb)的详细信息: \n");
hb.print();
// 将"左倾堆hb"合并到"左倾堆ha"中。
ha.merge(hb);
System.out.printf("\n== 合并ha和hb后的详细信息: \n");
ha.print();
}
}
6) 左倾堆的Java测试程序
左倾堆的测试程序已经包含在它的实现文件(LeftistHeapTest.java)中了,这里仅给出它的运行结果:
== 左倾堆(ha)中依次添加: 10 40 24 30 36 20 12 16
== 左倾堆(ha)的详细信息:
10(2) is root
24(1) is 10's left child
30(0) is 24's left child
36(0) is 24's right child
12(1) is 10's right child
20(0) is 12's left child
40(0) is 20's left child
16(0) is 12's right child
== 左倾堆(hb)中依次添加: 17 13 11 15 19 21 23
== 左倾堆(hb)的详细信息:
11(2) is root
15(1) is 11's left child
19(0) is 15's left child
21(0) is 15's right child
13(1) is 11's right child
17(0) is 13's left child
23(0) is 13's right child
== 合并ha和hb后的详细信息:
10(2) is root
11(2) is 10's left child
15(1) is 11's left child
19(0) is 15's left child
21(0) is 15's right child
12(1) is 11's right child
13(1) is 12's left child
17(0) is 13's left child
16(0) is 13's right child
23(0) is 16's left child
20(0) is 12's right child
40(0) is 20's left child
24(1) is 10's right child
30(0) is 24's left child
36(0) is 24's right child
十二、 斜堆之Java的实现
1) 概要
前面分别通过C和C++实现了斜堆,本章给出斜堆的Java版本。还是那句老话,三种实现的原理一样,择其一了解即可。
目录
1. 斜堆的介绍
2. 斜堆的基本操作
3. 斜堆的Java实现(完整源码)
4. 斜堆的Java测试程序
2) 斜堆的介绍
斜堆(Skew heap)也叫自适应堆(self-adjusting heap),它是左倾堆的一个变种。和左倾堆一样,它通常也用于实现优先队列;作为一种自适应的左倾堆,它的合并操作的时间复杂度也是O(lg n)。
它与左倾堆的差别是:
(01) 斜堆的节点没有"零距离"这个属性,而左倾堆则有。
(02) 斜堆的合并操作和左倾堆的合并操作算法不同。
3) 斜堆的合并操作
(01) 如果一个空斜堆与一个非空斜堆合并,返回非空斜堆。
(02) 如果两个斜堆都非空,那么比较两个根节点,取较小堆的根节点为新的根节点。将"较小堆的根节点的右孩子"和"较大堆"进行合并。
(03) 合并后,交换新堆根节点的左孩子和右孩子。
第(03)步是斜堆和左倾堆的合并操作差别的关键所在,如果是左倾堆,则合并后要比较左右孩子的零距离大小,若右孩子的零距离 > 左孩子的零距离,则交换左右孩子;最后,在设置根的零距离。
斜堆的基本操作
1. 基本定义
public class SkewHeap<T extends Comparable<T>> {
private SkewNode<T> mRoot; // 根结点
private class SkewNode<T extends Comparable<T>> {
T key; // 关键字(键值)
SkewNode<T> left; // 左孩子
SkewNode<T> right; // 右孩子
public SkewNode(T key, SkewNode<T> left, SkewNode<T> right) {
this.key = key;
this.left = left;
this.right = right;
}
public String toString() {
return "key:"+key;
}
}
...
}
SkewNode是斜堆对应的节点类。
SkewHeap是斜堆类,它包含了斜堆的根节点,以及斜堆的操作。
2. 合并
/*
* 合并"斜堆x"和"斜堆y"
*/
private SkewNode<T> merge(SkewNode<T> x, SkewNode<T> y) {
if(x == null) return y;
if(y == null) return x;
// 合并x和y时,将x作为合并后的树的根;
// 这里的操作是保证: x的key < y的key
if(x.key.compareTo(y.key) > 0) {
SkewNode<T> tmp = x;
x = y;
y = tmp;
}
// 将x的右孩子和y合并,
// 合并后直接交换x的左右孩子,而不需要像左倾堆一样考虑它们的npl。
SkewNode<T> tmp = merge(x.right, y);
x.right = x.left;
x.left = tmp;
return x;
}
public void merge(SkewHeap<T> other) {
this.mRoot = merge(this.mRoot, other.mRoot);
}
merge(x, y)是内部接口,作用是合并x和y这两个斜堆,并返回得到的新堆的根节点。
merge(other)是外部接口,作用是将other合并到当前堆中。
3. 添加
/*
* 新建结点(key),并将其插入到斜堆中
*
* 参数说明:
* key 插入结点的键值
*/
public void insert(T key) {
SkewNode<T> node = new SkewNode<T>(key,null,null);
// 如果新建结点失败,则返回。
if (node != null)
this.mRoot = merge(this.mRoot, node);
}
insert(key)的作用是新建键值为key的节点,并将其加入到当前斜堆中。
4. 删除
/*
* 删除根结点
*
* 返回值:
* 返回被删除的节点的键值
*/
public T remove() {
if (this.mRoot == null)
return null;
T key = this.mRoot.key;
SkewNode<T> l = this.mRoot.left;
SkewNode<T> r = this.mRoot.right;
this.mRoot = null; // 删除根节点
this.mRoot = merge(l, r); // 合并左右子树
return key;
}
remove()的作用是删除斜堆的最小节点。
注意:关于斜堆的"前序遍历"、"中序遍历"、"后序遍历"、"打印"、"销毁"等接口就不再单独介绍了。后文的源码中有给出它们的实现代码,Please RTFSC(Read The Fucking Source Code)!
4) 斜堆的Java实现(完整源码)
斜堆的实现文件(SkewHeap.java)
/**
* Java 语言: 斜堆
*
* @author skywang
* @date 2014/03/31
*/
public class SkewHeap<T extends Comparable<T>> {
private SkewNode<T> mRoot; // 根结点
private class SkewNode<T extends Comparable<T>> {
T key; // 关键字(键值)
SkewNode<T> left; // 左孩子
SkewNode<T> right; // 右孩子
public SkewNode(T key, SkewNode<T> left, SkewNode<T> right) {
this.key = key;
this.left = left;
this.right = right;
}
public String toString() {
return "key:"+key;
}
}
public SkewHeap() {
mRoot = null;
}
/*
* 前序遍历"斜堆"
*/
private void preOrder(SkewNode<T> heap) {
if(heap != null) {
System.out.print(heap.key+" ");
preOrder(heap.left);
preOrder(heap.right);
}
}
public void preOrder() {
preOrder(mRoot);
}
/*
* 中序遍历"斜堆"
*/
private void inOrder(SkewNode<T> heap) {
if(heap != null) {
inOrder(heap.left);
System.out.print(heap.key+" ");
inOrder(heap.right);
}
}
public void inOrder() {
inOrder(mRoot);
}
/*
* 后序遍历"斜堆"
*/
private void postOrder(SkewNode<T> heap) {
if(heap != null)
{
postOrder(heap.left);
postOrder(heap.right);
System.out.print(heap.key+" ");
}
}
public void postOrder() {
postOrder(mRoot);
}
/*
* 合并"斜堆x"和"斜堆y"
*/
private SkewNode<T> merge(SkewNode<T> x, SkewNode<T> y) {
if(x == null) return y;
if(y == null) return x;
// 合并x和y时,将x作为合并后的树的根;
// 这里的操作是保证: x的key < y的key
if(x.key.compareTo(y.key) > 0) {
SkewNode<T> tmp = x;
x = y;
y = tmp;
}
// 将x的右孩子和y合并,
// 合并后直接交换x的左右孩子,而不需要像左倾堆一样考虑它们的npl。
SkewNode<T> tmp = merge(x.right, y);
x.right = x.left;
x.left = tmp;
return x;
}
public void merge(SkewHeap<T> other) {
this.mRoot = merge(this.mRoot, other.mRoot);
}
/*
* 新建结点(key),并将其插入到斜堆中
*
* 参数说明:
* key 插入结点的键值
*/
public void insert(T key) {
SkewNode<T> node = new SkewNode<T>(key,null,null);
// 如果新建结点失败,则返回。
if (node != null)
this.mRoot = merge(this.mRoot, node);
}
/*
* 删除根结点
*
* 返回值:
* 返回被删除的节点的键值
*/
public T remove() {
if (this.mRoot == null)
return null;
T key = this.mRoot.key;
SkewNode<T> l = this.mRoot.left;
SkewNode<T> r = this.mRoot.right;
this.mRoot = null; // 删除根节点
this.mRoot = merge(l, r); // 合并左右子树
return key;
}
/*
* 销毁斜堆
*/
private void destroy(SkewNode<T> heap) {
if (heap==null)
return ;
if (heap.left != null)
destroy(heap.left);
if (heap.right != null)
destroy(heap.right);
heap=null;
}
public void clear() {
destroy(mRoot);
mRoot = null;
}
/*
* 打印"斜堆"
*
* key -- 节点的键值
* direction -- 0,表示该节点是根节点;
* -1,表示该节点是它的父结点的左孩子;
* 1,表示该节点是它的父结点的右孩子。
*/
private void print(SkewNode<T> heap, T key, int direction) {
if(heap != null) {
if(direction==0) // heap是根节点
System.out.printf("%2d is root\n", heap.key);
else // heap是分支节点
System.out.printf("%2d is %2d's %6s child\n", heap.key, key, direction==1?"right" : "left");
print(heap.left, heap.key, -1);
print(heap.right,heap.key, 1);
}
}
public void print() {
if (mRoot != null)
print(mRoot, mRoot.key, 0);
}
}
斜堆的测试程序(SkewHeapTest.java)
/**
* Java 语言: 斜堆
*
* @author skywang
* @date 2014/03/31
*/
public class SkewHeapTest {
public static void main(String[] args) {
int a[]= {10,40,24,30,36,20,12,16};
int b[]= {17,13,11,15,19,21,23};
SkewHeap<Integer> ha=new SkewHeap<Integer>();
SkewHeap<Integer> hb=new SkewHeap<Integer>();
System.out.printf("== 斜堆(ha)中依次添加: ");
for(int i=0; i<a.length; i++) {
System.out.printf("%d ", a[i]);
ha.insert(a[i]);
}
System.out.printf("\n== 斜堆(ha)的详细信息: \n");
ha.print();
System.out.printf("\n== 斜堆(hb)中依次添加: ");
for(int i=0; i<b.length; i++) {
System.out.printf("%d ", b[i]);
hb.insert(b[i]);
}
System.out.printf("\n== 斜堆(hb)的详细信息: \n");
hb.print();
// 将"斜堆hb"合并到"斜堆ha"中。
ha.merge(hb);
System.out.printf("\n== 合并ha和hb后的详细信息: \n");
ha.print();
}
}
5) 斜堆的Java测试程序
斜堆的测试程序已经包含在它的实现文件(SkewHeapTest.java)中了,这里仅给出它的运行结果:
== 斜堆(ha)中依次添加: 10 40 24 30 36 20 12 16
== 斜堆(ha)的详细信息:
10 is root
16 is 10's left child
20 is 16's left child
30 is 20's left child
40 is 30's left child
12 is 10's right child
24 is 12's left child
36 is 24's left child
== 斜堆(hb)中依次添加: 17 13 11 15 19 21 23
== 斜堆(hb)的详细信息:
11 is root
13 is 11's left child
17 is 13's left child
23 is 17's left child
19 is 13's right child
15 is 11's right child
21 is 15's left child
== 合并ha和hb后的详细信息:
10 is root
11 is 10's left child
12 is 11's left child
15 is 12's left child
21 is 15's left child
24 is 12's right child
36 is 24's left child
13 is 11's right child
17 is 13's left child
23 is 17's left child
19 is 13's right child
16 is 10's right child
20 is 16's left child
30 is 20's left child
40 is 30's left child
十三、 二项堆之Java的实现
1) 概要
前面分别通过C和C++实现了二项堆,本章给出二项堆的Java版本。还是那句老话,三种实现的原理一样,择其一了解即可。
目录
1. 二项树的介绍
2. 二项堆的概述
3. 二项堆的基本操作
4. 二项堆的Java实现(完整源码)
5. 二项堆的Java测试程序
2) 二项树的介绍
二项树的定义
二项堆是二项树的集合。在了解二项堆之前,先对二项树进行介绍。
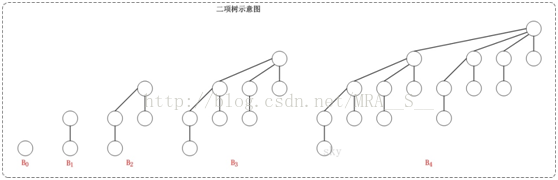
二项树是一种递归定义的有序树。它的递归定义如下:
(01) 二项树B0只有一个结点;
(02) 二项树Bk由两棵二项树B(k-1)组成的,其中一棵树是另一棵树根的最左孩子。
如下图所示:
上图的B0、B1、B2、B3、B4都是二项树。对比前面提到的二项树的定义:B0只有一个节点,B1由两个B0所组成,B2由两个B1所组成,B3由两个B2所组成,B4由两个B3所组成;而且,当两颗相同的二项树组成另一棵树时,其中一棵树是另一棵树的最左孩子。
二项树的性质
二项树有以下性质:
[性质一] Bk共有2k个节点。
如上图所示,B0有20=1节点,B1有21=2个节点,B2有22=4个节点,...
[性质二] Bk的高度为k。
如上图所示,B0的高度为0,B1的高度为1,B2的高度为2,...
[性质三] Bk在深度i处恰好有C(k,i)个节点,其中i=0,1,2,...,k。
C(k,i)是高中数学中阶乘元素,例如,C(10,3)=(10*9*8) / (3*2*1)=240
B4中深度为0的节点C(4,0)=1
B4中深度为1的节点C(4,1)= 4 / 1 = 4
B4中深度为2的节点C(4,2)= (4*3) / (2*1) = 6
B4中深度为3的节点C(4,3)= (4*3*2) / (3*2*1) = 4
B4中深度为4的节点C(4,4)= (4*3*2*1) / (4*3*2*1) = 1
合计得到B4的节点分布是(1,4,6,4,1)。
[性质四] 根的度数为k,它大于任何其它节点的度数。
节点的度数是该结点拥有的子树的数目。
注意:树的高度和深度是相同的。关于树的高度的概念,《算法导论》中只有一个节点的树的高度是0,而"维基百科"中只有一个节点的树的高度是1。本文使用了《算法导论中》"树的高度和深度"的概念。
3) 二项堆的概述
二项堆和之前所讲的堆(二叉堆、左倾堆、斜堆)一样,也是用于实现优先队列的。二项堆是指满足以下性质的二项树的集合:
(01) 每棵二项树都满足最小堆性质。即,父节点的关键字 <= 它的孩子的关键字。
(02) 不能有两棵或以上的二项树具有相同的度数(包括度数为0)。换句话说,具有度数k的二项树有0个或1个。
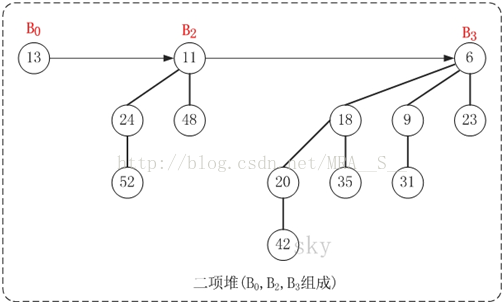
上图就是一棵二项堆,它由二项树B0、B2和B3组成。对比二项堆的定义:(01)二项树B0、B2、B3都是最小堆;(02)二项堆不包含相同度数的二项树。
二项堆的第(01)个性质保证了二项堆的最小节点就是某个二项树的根节点,第(02)个性质则说明结点数为n的二项堆最多只有log{n} + 1棵二项树。实际上,将包含n个节点的二项堆,表示成若干个2的指数和(或者转换成二进制),则每一个2个指数都对应一棵二项树。例如,13(二进制是1101)的2个指数和为13=23 + 22+ 20, 因此具有13个节点的二项堆由度数为3, 2, 0的三棵二项树组成。
4) 二项堆的基本操作
二项堆是可合并堆,它的合并操作的复杂度是O(log n)。
5) 1. 基本定义
public class BinomialHeap<T extends Comparable<T>> {
private BinomialNode<T> mRoot; // 根结点
private class BinomialNode<T extends Comparable<T>> {
T key; // 关键字(键值)
int degree; // 度数
BinomialNode<T> child; // 左孩子
BinomialNode<T> parent; // 父节点
BinomialNode<T> next; // 兄弟节点
public BinomialNode(T key) {
this.key = key;
this.degree = 0;
this.child = null;
this.parent = null;
this.next = null;
}
public String toString() {
return "key:"+key;
}
}
...
}
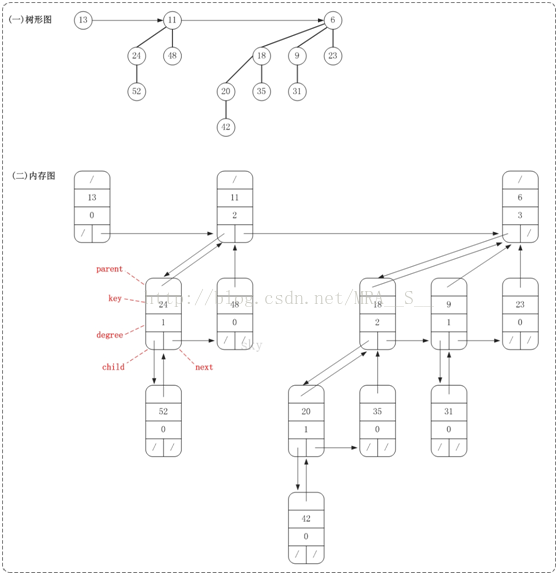
BinomialNode是二项堆的节点。它包括了关键字(key),用于比较节点大小;度数(degree),用来表示当前节点的度数;左孩子(child)、父节点(parent)以及兄弟节点(next)。
BinomialHeap是二项堆对应的类,它包括了二项堆的根节点mRoot以及二项堆的基本操作的定义。
下面是一棵二项堆的树形图和它对应的内存结构关系图。
6) 2. 合并操作
合并操作是二项堆的重点,它的添加操作也是基于合并操作来实现的。合并两个二项堆,需要的步骤概括起来如下:
(01) 将两个二项堆的根链表合并成一个链表。合并后的新链表按照"节点的度数"单调递增排列。
(02) 将新链表中"根节点度数相同的二项树"连接起来,直到所有根节点度数都不相同。
下面,先看看合并操作的代码;然后再通过示意图对合并操作进行说明。
merge()代码(Java)
/*
* 将h1, h2中的根表合并成一个按度数递增的链表,返回合并后的根节点
*/
private BinomialNode<T> merge(BinomialNode<T> h1, BinomialNode<T> h2) {
if (h1 == null) return h2;
if (h2 == null) return h1;
// root是新堆的根,h3用来遍历h1和h3的。
BinomialNode<T> pre_h3, h3, root=null;
pre_h3 = null;
//整个while,h1, h2, pre_h3, h3都在往后顺移
while ((h1!=null) && (h2!=null)) {
if (h1.degree <= h2.degree) {
h3 = h1;
h1 = h1.next;
} else {
h3 = h2;
h2 = h2.next;
}
if (pre_h3 == null) {
pre_h3 = h3;
root = h3;
} else {
pre_h3.next = h3;
pre_h3 = h3;
}
if (h1 != null) {
h3.next = h1;
} else {
h3.next = h2;
}
}
return root;
}
link()代码(Java)
/*
* 合并两个二项堆:将child合并到root中
*/
private void link(BinomialNode<T> child, BinomialNode<T> root) {
child.parent = root;
child.next = root.child;
root.child = child;
root.degree++;
}
合并操作代码(Java)
/*
* 合并二项堆:将h1, h2合并成一个堆,并返回合并后的堆
*/
private BinomialNode<T> union(BinomialNode<T> h1, BinomialNode<T> h2) {
BinomialNode<T> root;
// 将h1, h2中的根表合并成一个按度数递增的链表root
root = merge(h1, h2);
if (root == null)
return null;
BinomialNode<T> prev_x = null;
BinomialNode<T> x = root;
BinomialNode<T> next_x = x.next;
while (next_x != null) {
if ( (x.degree != next_x.degree)
|| ((next_x.next != null) && (next_x.degree == next_x.next.degree))) {
// Case 1: x.degree != next_x.degree
// Case 2: x.degree == next_x.degree == next_x.next.degree
prev_x = x;
x = next_x;
} else if (x.key.compareTo(next_x.key) <= 0) {
// Case 3: x.degree == next_x.degree != next_x.next.degree
// && x.key <= next_x.key
x.next = next_x.next;
link(next_x, x);
} else {
// Case 4: x.degree == next_x.degree != next_x.next.degree
// && x.key > next_x.key
if (prev_x == null) {
root = next_x;
} else {
prev_x.next = next_x;
}
link(x, next_x);
x = next_x;
}
next_x = x.next;
}
return root;
}
/*
* 将二项堆other合并到当前堆中
*/
public void union(BinomialHeap<T> other) {
if (other!=null && other.mRoot!=null)
mRoot = union(mRoot, other.mRoot);
}
合并函数combine(h1, h2)的作用是将h1和h2合并,并返回合并后的二项堆。在combine(h1, h2)中,涉及到了两个函数merge(h1, h2)和link(child, root)。
merge(h1, h2)就是我们前面所说的"两个二项堆的根链表合并成一个链表,合并后的新链表按照'节点的度数'单调递增排序"。
link(child, root)则是为了合并操作的辅助函数,它的作用是将"二项堆child的根节点"设为"二项堆root的左孩子",从而将child整合到root中去。
在combine(h1, h2)中对h1和h2进行合并时;首先通过 merge(h1, h2) 将h1和h2的根链表合并成一个"按节点的度数单调递增"的链表;然后进入while循环,对合并得到的新链表进行遍历,将新链表中"根节点度数相同的二项树"连接起来,直到所有根节点度数都不相同为止。在将新联表中"根节点度数相同的二项树"连接起来时,可以将被连接的情况概括为4种。
x是根链表的当前节点,next_x是x的下一个(兄弟)节点。
Case 1: x->degree != next_x->degree
即,"当前节点的度数"与"下一个节点的度数"相等时。此时,不需要执行任何操作,继续查看后面的节点。
Case 2: x->degree == next_x->degree == next_x->next->degree
即,"当前节点的度数"、"下一个节点的度数"和"下下一个节点的度数"都相等时。此时,暂时不执行任何操作,还是继续查看后面的节点。实际上,这里是将"下一个节点"和"下下一个节点"等到后面再进行整合连接。
Case 3: x->degree == next_x->degree != next_x->next->degree
&& x->key <= next_x->key
即,"当前节点的度数"与"下一个节点的度数"相等,并且"当前节点的键值"<="下一个节点的度数"。此时,将"下一个节点(对应的二项树)"作为"当前节点(对应的二项树)的左孩子"。
Case 4: x->degree == next_x->degree != next_x->next->degree
&& x->key > next_x->key
即,"当前节点的度数"与"下一个节点的度数"相等,并且"当前节点的键值">"下一个节点的度数"。此时,将"当前节点(对应的二项树)"作为"下一个节点(对应的二项树)的左孩子"。
下面通过示意图来对合并操作进行说明。
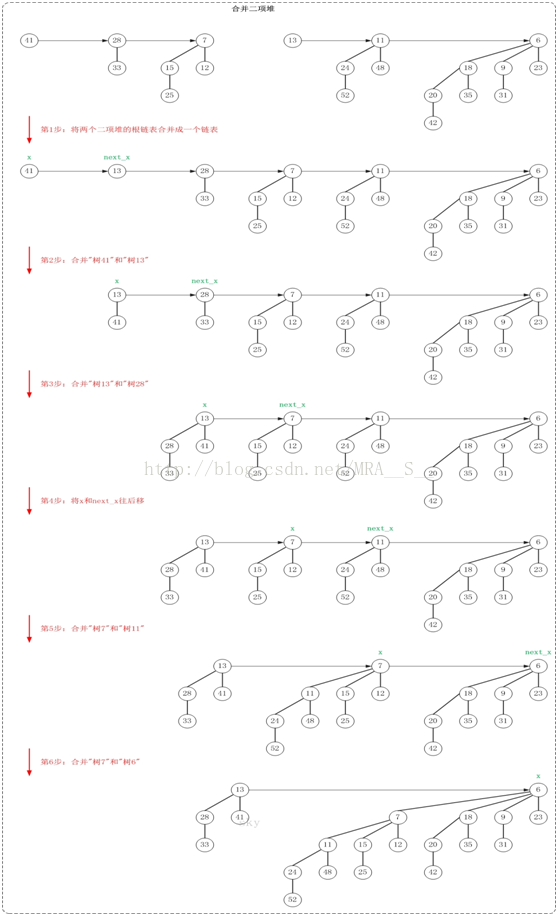
第1步:将两个二项堆的根链表合并成一个链表
执行完第1步之后,得到的新链表中有许多度数相同的二项树。实际上,此时得到的是对应"Case 4"的情况,"树41"(根节点为41的二项树)和"树13"的度数相同,且"树41"的键值 > "树13"的键值。此时,将"树41"作为"树13"的左孩子。
第2步:合并"树41"和"树13"
执行完第2步之后,得到的是对应"Case 3"的情况,"树13"和"树28"的度数相同,且"树13"的键值 < "树28"的键值。此时,将"树28"作为"树13"的左孩子。
第3步:合并"树13"和"树28"
执行完第3步之后,得到的是对应"Case 2"的情况,"树13"、"树28"和"树7"这3棵树的度数都相同。此时,将x设为下一个节点。
第4步:将x和next_x往后移
执行完第4步之后,得到的是对应"Case 3"的情况,"树7"和"树11"的度数相同,且"树7"的键值 < "树11"的键值。此时,将"树11"作为"树7"的左孩子。
第5步:合并"树7"和"树11"
执行完第5步之后,得到的是对应"Case 4"的情况,"树7"和"树6"的度数相同,且"树7"的键值 > "树6"的键值。此时,将"树7"作为"树6"的左孩子。
第6步:合并"树7"和"树6"
此时,合并操作完成!
PS. 合并操作的图文解析过程与"测试程序(Main.java)中的testUnion()函数"是对应的!
7) 3. 插入操作
理解了"合并"操作之后,插入操作就相当简单了。插入操作可以看作是将"要插入的节点"和当前已有的堆进行合并。
插入操作代码(Java)
/*
* 新建key对应的节点,并将其插入到二项堆中。
*/
public void insert(T key) {
BinomialNode<T> node;
// 禁止插入相同的键值
if (contains(key)==true) {
System.out.printf("insert failed: the key(%s) is existed already!\n", key);
return ;
}
node = new BinomialNode<T>(key);
if (node==null)
return ;
mRoot = union(mRoot, node);
}
在插入时,首先通过contains(key)查找键值为key的节点。存在的话,则直接返回;不存在的话,则新建BinomialNode对象node,然后将node和heap进行合并。
注意:我这里实现的二项堆是"进制插入相同节点的"!若你想允许插入相同键值的节点,则屏蔽掉插入操作中的contains(key)部分代码即可。
8) 4. 删除操作
删除二项堆中的某个节点,需要的步骤概括起来如下:
(01) 将"该节点"交换到"它所在二项树"的根节点位置。方法是,从"该节点"不断向上(即向树根方向)"遍历,不断交换父节点和子节点的数据,直到被删除的键值到达树根位置。
(02) 将"该节点所在的二项树"从二项堆中移除;将该二项堆记为heap。
(03) 将"该节点所在的二项树"进行反转。反转的意思,就是将根的所有孩子独立出来,并将这些孩子整合成二项堆,将该二项堆记为child。
(04) 将child和heap进行合并操作。
下面,先看看删除操作的代码;再进行图文说明。
删除操作代码(Java)
/*
* 删除节点:删除键值为key的节点
*/
private BinomialNode<T> remove(BinomialNode<T> root, T key) {
if (root==null)
return root;
BinomialNode<T> node;
// 查找键值为key的节点
if ((node = search(root, key)) == null)
return root;
// 将被删除的节点的数据数据上移到它所在的二项树的根节点
BinomialNode<T> parent = node.parent;
while (parent != null) {
// 交换数据
T tmp = node.key;
node.key = parent.key;
parent.key = tmp;
// 下一个父节点
node = parent;
parent = node.parent;
}
// 找到node的前一个根节点(prev)
BinomialNode<T> prev = null;
BinomialNode<T> pos = root;
while (pos != node) {
prev = pos;
pos = pos.next;
}
// 移除node节点
if (prev!=null)
prev.next = node.next;
else
root = node.next;
root = union(root, reverse(node.child));
// help GC
node = null;
return root;
}
public void remove(T key) {
mRoot = remove(mRoot, key);
}
remove(key)的作用是删除二项堆中键值为key的节点,并返回删除节点后的二项堆。
下面通过示意图来对删除操作进行说明(删除二项堆中的节点20)。
总的思想,就是将被"删除节点"从它所在的二项树中孤立出来,然后再对二项树进行相应的处理。
PS. 删除操作的图文解析过程与"测试程序(Main.java)中的testDelete()函数"是对应的!
9) 5. 更新操作
更新二项堆中的某个节点,就是修改节点的值,它包括两部分分:"减少节点的值" 和 "增加节点的值" 。
更新操作代码(Java)
/*
* 更新二项堆的节点node的键值为key
*/
private void updateKey(BinomialNode<T> node, T key) {
if (node == null)
return ;
int cmp = key.compareTo(node.key);
if(cmp < 0) // key < node.key
decreaseKey(node, key);
else if(cmp > 0) // key > node.key
increaseKey(node, key);
else
System.out.println("No need to update!!!");
}
/*
* 将二项堆中键值oldkey更新为newkey
*/
public void update(T oldkey, T newkey) {
BinomialNode<T> node;
node = search(mRoot, oldkey);
if (node != null)
updateKey(node, newkey);
}
5.1 减少节点的值
减少节点值的操作很简单:该节点一定位于一棵二项树中,减小"二项树"中某个节点的值后要保证"该二项树仍然是一个最小堆";因此,就需要我们不断的将该节点上调。
减少操作代码(Java)
/*
* 减少关键字的值:将二项堆中的节点node的键值减小为key。
*/
private void decreaseKey(BinomialNode<T> node, T key) {
if(key.compareTo(node.key)>=0 || contains(key)==true) {
System.out.println("decrease failed: the new key("+key+") is existed already, or is no smaller than current key("+node.key+")");
return ;
}
node.key = key;
BinomialNode<T> child, parent;
child = node;
parent = node.parent;
while(parent != null && child.key.compareTo(parent.key)<0) {
// 交换parent和child的数据
T tmp = parent.key;
parent.key = child.key;
child.key = tmp;
child = parent;
parent = child.parent;
}
}
下面是减少操作的示意图(20->2)
减少操作的思想很简单,就是"保持被减节点所在二项树的最小堆性质"。
PS. 减少操作的图文解析过程与"测试程序(Main.java)中的testDecrease()函数"是对应的!
5.2 增加节点的值
增加节点值的操作也很简单。上面说过减少要将被减少的节点不断上调,从而保证"被减少节点所在的二项树"的最小堆性质;而增加操作则是将被增加节点不断的下调,从而保证"被增加节点所在的二项树"的最小堆性质。
增加操作代码(Java)
/*
* 增加关键字的值:将二项堆中的节点node的键值增加为key。
*/
private void increaseKey(BinomialNode<T> node, T key) {
if(key.compareTo(node.key)<=0 || contains(key)==true) {
System.out.println("increase failed: the new key("+key+") is existed already, or is no greater than current key("+node.key+")");
return ;
}
node.key = key;
BinomialNode<T> cur = node;
BinomialNode<T> child = cur.child;
while (child != null) {
if(cur.key.compareTo(child.key) > 0) {
// 如果"当前节点" < "它的左孩子",
// 则在"它的孩子中(左孩子 和 左孩子的兄弟)"中,找出最小的节点;
// 然后将"最小节点的值" 和 "当前节点的值"进行互换
BinomialNode<T> least = child; // least是child和它的兄弟中的最小节点
while(child.next != null) {
if (least.key.compareTo(child.next.key) > 0)
least = child.next;
child = child.next;
}
// 交换最小节点和当前节点的值
T tmp = least.key;
least.key = cur.key;
cur.key = tmp;
// 交换数据之后,再对"原最小节点"进行调整,使它满足最小堆的性质:父节点 <= 子节点
cur = least;
child = cur.child;
} else {
child = child.next;
}
}
}
下面是增加操作的示意图(6->60)
增加操作的思想很简单,"保持被增加点所在二项树的最小堆性质"。
PS. 增加操作的图文解析过程与"测试程序(Main.java)中的testIncrease()函数"是对应的!
注意:关于二项堆的"查找"、"更新"、"打印"等接口就不再单独介绍了,后文的源码中有给出它们的实现代码。有兴趣的话,Please RTFSC(Read The Fucking Source Code)!
10) 二项堆的Java实现(完整源码)
二项堆的实现文件(BinomialHeap.java)
/**
* Java 语言: 二项堆
*
* @author skywang
* @date 2014/04/03
*/
public class BinomialHeap<T extends Comparable<T>> {
private BinomialNode<T> mRoot; // 根结点
private class BinomialNode<T extends Comparable<T>> {
T key; // 关键字(键值)
int degree; // 度数
BinomialNode<T> child; // 左孩子
BinomialNode<T> parent; // 父节点
BinomialNode<T> next; // 兄弟节点
public BinomialNode(T key) {
this.key = key;
this.degree = 0;
this.child = null;
this.parent = null;
this.next = null;
}
public String toString() {
return "key:"+key;
}
}
public BinomialHeap() {
mRoot = null;
}
/*
* 获取二项堆中的最小节点的键值
*/
public T minimum() {
if (mRoot==null)
return null;
BinomialNode<T> x, prev_x; // x是用来遍历的当前节点
BinomialNode<T> y, prev_y; // y是最小节点
prev_x = mRoot;
x = mRoot.next;
prev_y = null;
y = mRoot;
// 找到最小节点
while (x != null) {
if (x.key.compareTo(y.key) < 0) {
y = x;
prev_y = prev_x;
}
prev_x = x;
x = x.next;
}
return y.key;
}
/*
* 合并两个二项堆:将child合并到root中
*/
private void link(BinomialNode<T> child, BinomialNode<T> root) {
child.parent = root;
child.next = root.child;
root.child = child;
root.degree++;
}
/*
* 将h1, h2中的根表合并成一个按度数递增的链表,返回合并后的根节点
*/
private BinomialNode<T> merge(BinomialNode<T> h1, BinomialNode<T> h2) {
if (h1 == null) return h2;
if (h2 == null) return h1;
// root是新堆的根,h3用来遍历h1和h3的。
BinomialNode<T> pre_h3, h3, root=null;
pre_h3 = null;
//整个while,h1, h2, pre_h3, h3都在往后顺移
while ((h1!=null) && (h2!=null)) {
if (h1.degree <= h2.degree) {
h3 = h1;
h1 = h1.next;
} else {
h3 = h2;
h2 = h2.next;
}
if (pre_h3 == null) {
pre_h3 = h3;
root = h3;
} else {
pre_h3.next = h3;
pre_h3 = h3;
}
if (h1 != null) {
h3.next = h1;
} else {
h3.next = h2;
}
}
return root;
}
/*
* 合并二项堆:将h1, h2合并成一个堆,并返回合并后的堆
*/
private BinomialNode<T> union(BinomialNode<T> h1, BinomialNode<T> h2) {
BinomialNode<T> root;
// 将h1, h2中的根表合并成一个按度数递增的链表root
root = merge(h1, h2);
if (root == null)
return null;
BinomialNode<T> prev_x = null;
BinomialNode<T> x = root;
BinomialNode<T> next_x = x.next;
while (next_x != null) {
if ( (x.degree != next_x.degree)
|| ((next_x.next != null) && (next_x.degree == next_x.next.degree))) {
// Case 1: x.degree != next_x.degree
// Case 2: x.degree == next_x.degree == next_x.next.degree
prev_x = x;
x = next_x;
} else if (x.key.compareTo(next_x.key) <= 0) {
// Case 3: x.degree == next_x.degree != next_x.next.degree
// && x.key <= next_x.key
x.next = next_x.next;
link(next_x, x);
} else {
// Case 4: x.degree == next_x.degree != next_x.next.degree
// && x.key > next_x.key
if (prev_x == null) {
root = next_x;
} else {
prev_x.next = next_x;
}
link(x, next_x);
x = next_x;
}
next_x = x.next;
}
return root;
}
/*
* 将二项堆other合并到当前堆中
*/
public void union(BinomialHeap<T> other) {
if (other!=null && other.mRoot!=null)
mRoot = union(mRoot, other.mRoot);
}
/*
* 新建key对应的节点,并将其插入到二项堆中。
*/
public void insert(T key) {
BinomialNode<T> node;
// 禁止插入相同的键值
if (contains(key)==true) {
System.out.printf("insert failed: the key(%s) is existed already!\n", key);
return ;
}
node = new BinomialNode<T>(key);
if (node==null)
return ;
mRoot = union(mRoot, node);
}
/*
* 反转二项堆root,并返回反转后的根节点
*/
private BinomialNode<T> reverse(BinomialNode<T> root) {
BinomialNode<T> next;
BinomialNode<T> tail = null;
if (root==null)
return root;
root.parent = null;
while (root.next!=null) {
next = root.next;
root.next = tail;
tail = root;
root = next;
root.parent = null;
}
root.next = tail;
return root;
}
/*
* 移除二项堆root中的最小节点,并返回删除节点后的二项树
*/
private BinomialNode<T> extractMinimum(BinomialNode<T> root) {
if (root==null)
return root;
BinomialNode<T> x, prev_x; // x是用来遍历的当前节点
BinomialNode<T> y, prev_y; // y是最小节点
prev_x = root;
x = root.next;
prev_y = null;
y = root;
// 找到最小节点
while (x != null) {
if (x.key.compareTo(y.key) < 0) {
y = x;
prev_y = prev_x;
}
prev_x = x;
x = x.next;
}
if (prev_y == null) // root的根节点就是最小根节点
root = root.next;
else // root的根节点不是最小根节点
prev_y.next = y.next;
// 反转最小节点的左孩子,得到最小堆child;
// 这样,就使得最小节点所在二项树的孩子们都脱离出来成为一棵独立的二项树(不包括最小节点)
BinomialNode<T> child = reverse(y.child);
// 将"删除最小节点的二项堆child"和"root"进行合并。
root = union(root, child);
// help GC
y = null;
return root;
}
public void extractMinimum() {
mRoot = extractMinimum(mRoot);
}
/*
* 减少关键字的值:将二项堆中的节点node的键值减小为key。
*/
private void decreaseKey(BinomialNode<T> node, T key) {
if(key.compareTo(node.key)>=0 || contains(key)==true) {
System.out.println("decrease failed: the new key("+key+") is existed already, or is no smaller than current key("+node.key+")");
return ;
}
node.key = key;
BinomialNode<T> child, parent;
child = node;
parent = node.parent;
while(parent != null && child.key.compareTo(parent.key)<0) {
// 交换parent和child的数据
T tmp = parent.key;
parent.key = child.key;
child.key = tmp;
child = parent;
parent = child.parent;
}
}
/*
* 增加关键字的值:将二项堆中的节点node的键值增加为key。
*/
private void increaseKey(BinomialNode<T> node, T key) {
if(key.compareTo(node.key)<=0 || contains(key)==true) {
System.out.println("increase failed: the new key("+key+") is existed already, or is no greater than current key("+node.key+")");
return ;
}
node.key = key;
BinomialNode<T> cur = node;
BinomialNode<T> child = cur.child;
while (child != null) {
if(cur.key.compareTo(child.key) > 0) {
// 如果"当前节点" < "它的左孩子",
// 则在"它的孩子中(左孩子 和 左孩子的兄弟)"中,找出最小的节点;
// 然后将"最小节点的值" 和 "当前节点的值"进行互换
BinomialNode<T> least = child; // least是child和它的兄弟中的最小节点
while(child.next != null) {
if (least.key.compareTo(child.next.key) > 0)
least = child.next;
child = child.next;
}
// 交换最小节点和当前节点的值
T tmp = least.key;
least.key = cur.key;
cur.key = tmp;
// 交换数据之后,再对"原最小节点"进行调整,使它满足最小堆的性质:父节点 <= 子节点
cur = least;
child = cur.child;
} else {
child = child.next;
}
}
}
/*
* 更新二项堆的节点node的键值为key
*/
private void updateKey(BinomialNode<T> node, T key) {
if (node == null)
return ;
int cmp = key.compareTo(node.key);
if(cmp < 0) // key < node.key
decreaseKey(node, key);
else if(cmp > 0) // key > node.key
increaseKey(node, key);
else
System.out.println("No need to update!!!");
}
/*
* 将二项堆中键值oldkey更新为newkey
*/
public void update(T oldkey, T newkey) {
BinomialNode<T> node;
node = search(mRoot, oldkey);
if (node != null)
updateKey(node, newkey);
}
/*
* 查找:在二项堆中查找键值为key的节点
*/
private BinomialNode<T> search(BinomialNode<T> root, T key) {
BinomialNode<T> child;
BinomialNode<T> parent = root;
parent = root;
while (parent != null) {
if (parent.key.compareTo(key) == 0)
return parent;
else {
if((child = search(parent.child, key)) != null)
return child;
parent = parent.next;
}
}
return null;
}
/*
* 二项堆中是否包含键值key
*/
public boolean contains(T key) {
return search(mRoot, key)!=null ? true : false;
}
/*
* 删除节点:删除键值为key的节点
*/
private BinomialNode<T> remove(BinomialNode<T> root, T key) {
if (root==null)
return root;
BinomialNode<T> node;
// 查找键值为key的节点
if ((node = search(root, key)) == null)
return root;
// 将被删除的节点的数据数据上移到它所在的二项树的根节点
BinomialNode<T> parent = node.parent;
while (parent != null) {
// 交换数据
T tmp = node.key;
node.key = parent.key;
parent.key = tmp;
// 下一个父节点
node = parent;
parent = node.parent;
}
// 找到node的前一个根节点(prev)
BinomialNode<T> prev = null;
BinomialNode<T> pos = root;
while (pos != node) {
prev = pos;
pos = pos.next;
}
// 移除node节点
if (prev!=null)
prev.next = node.next;
else
root = node.next;
root = union(root, reverse(node.child));
// help GC
node = null;
return root;
}
public void remove(T key) {
mRoot = remove(mRoot, key);
}
/*
* 打印"二项堆"
*
* 参数说明:
* node -- 当前节点
* prev -- 当前节点的前一个节点(父节点or兄弟节点)
* direction -- 1,表示当前节点是一个左孩子;
* 2,表示当前节点是一个兄弟节点。
*/
private void print(BinomialNode<T> node, BinomialNode<T> prev, int direction) {
while(node != null)
{
if(direction==1) // node是根节点
System.out.printf("\t%2d(%d) is %2d's child\n", node.key, node.degree, prev.key);
else // node是分支节点
System.out.printf("\t%2d(%d) is %2d's next\n", node.key, node.degree, prev.key);
if (node.child != null)
print(node.child, node, 1);
// 兄弟节点
prev = node;
node = node.next;
direction = 2;
}
}
public void print() {
if (mRoot == null)
return ;
BinomialNode<T> p = mRoot;
System.out.printf("== 二项堆( ");
while (p != null) {
System.out.printf("B%d ", p.degree);
p = p.next;
}
System.out.printf(")的详细信息:\n");
int i=0;
p = mRoot;
while (p != null) {
i++;
System.out.printf("%d. 二项树B%d: \n", i, p.degree);
System.out.printf("\t%2d(%d) is root\n", p.key, p.degree);
print(p.child, p, 1);
p = p.next;
}
System.out.printf("\n");
}
}
二项堆的测试程序(Main.java)
/**
* Java 语言: 二项堆
*
* @author skywang
* @date 2014/03/31
*/
public class Main {
private static final boolean DEBUG = false;
// 共7个 = 1+2+4
private static int a[] = {12, 7, 25, 15, 28, 33, 41};
// 共13个 = 1+4+8
private static int b[] = {18, 35, 20, 42, 9,
31, 23, 6, 48, 11,
24, 52, 13 };
// 验证"二项堆的插入操作"
public static void testInsert() {
BinomialHeap<Integer> ha=new BinomialHeap<Integer>();
// 二项堆ha
System.out.printf("== 二项堆(ha)中依次添加: ");
for(int i=0; i<a.length; i++) {
System.out.printf("%d ", a[i]);
ha.insert(a[i]);
}
System.out.printf("\n");
System.out.printf("== 二项堆(ha)的详细信息: \n");
ha.print();
}
// 验证"二项堆的合并操作"
public static void testUnion() {
BinomialHeap<Integer> ha=new BinomialHeap<Integer>();
BinomialHeap<Integer> hb=new BinomialHeap<Integer>();
// 二项堆ha
System.out.printf("== 二项堆(ha)中依次添加: ");
for(int i=0; i<a.length; i++) {
System.out.printf("%d ", a[i]);
ha.insert(a[i]);
}
System.out.printf("\n");
System.out.printf("== 二项堆(ha)的详细信息: \n");
ha.print();
// 二项堆hb
System.out.printf("== 二项堆(hb)中依次添加: ");
for(int i=0; i<b.length; i++) {
System.out.printf("%d ", b[i]);
hb.insert(b[i]);
}
System.out.printf("\n");
// 打印二项堆hb
System.out.printf("== 二项堆(hb)的详细信息: \n");
hb.print();
// 将"二项堆hb"合并到"二项堆ha"中。
ha.union(hb);
// 打印二项堆ha的详细信息
System.out.printf("== 合并ha和hb后的详细信息:\n");
ha.print();
}
// 验证"二项堆的删除操作"
public static void testDelete() {
BinomialHeap<Integer> hb=new BinomialHeap<Integer>();
// 二项堆hb
System.out.printf("== 二项堆(hb)中依次添加: ");
for(int i=0; i<b.length; i++) {
System.out.printf("%d ", b[i]);
hb.insert(b[i]);
}
System.out.printf("\n");
// 打印二项堆hb
System.out.printf("== 二项堆(hb)的详细信息: \n");
hb.print();
// 将"二项堆hb"合并到"二项堆ha"中。
hb.remove(20);
System.out.printf("== 删除节点20后的详细信息: \n");
hb.print();
}
// 验证"二项堆的更新(减少)操作"
public static void testDecrease() {
BinomialHeap<Integer> hb=new BinomialHeap<Integer>();
// 二项堆hb
System.out.printf("== 二项堆(hb)中依次添加: ");
for(int i=0; i<b.length; i++) {
System.out.printf("%d ", b[i]);
hb.insert(b[i]);
}
System.out.printf("\n");
// 打印二项堆hb
System.out.printf("== 二项堆(hb)的详细信息: \n");
hb.print();
// 将节点20更新为2
hb.update(20, 2);
System.out.printf("== 更新节点20->2后的详细信息: \n");
hb.print();
}
// 验证"二项堆的更新(减少)操作"
public static void testIncrease() {
BinomialHeap<Integer> hb=new BinomialHeap<Integer>();
// 二项堆hb
System.out.printf("== 二项堆(hb)中依次添加: ");
for(int i=0; i<b.length; i++) {
System.out.printf("%d ", b[i]);
hb.insert(b[i]);
}
System.out.printf("\n");
// 打印二项堆hb
System.out.printf("== 二项堆(hb)的详细信息: \n");
hb.print();
// 将节点6更新为60
hb.update(6, 60);
System.out.printf("== 更新节点6->60后的详细信息: \n");
hb.print();
}
public static void main(String[] args) {
// 1. 验证"二项堆的插入操作"
testInsert();
// 2. 验证"二项堆的合并操作"
//testUnion();
// 3. 验证"二项堆的删除操作"
//testDelete();
// 4. 验证"二项堆的更新(减少)操作"
//testDecrease();
// 5. 验证"二项堆的更新(增加)操作"
//testIncrease();
}
}
11) 二项堆的Java测试程序
二项堆的测试程序包括了五部分,分别是"插入"、"删除"、"增加"、"减少"、"合并"这5种功能的测试代码。默认是运行的"插入"功能代码,你可以根据自己的需要来对相应的功能进行验证!
下面是插入功能运行结果:
== 二项堆(ha)中依次添加: 12 7 25 15 28 33 41
== 二项堆(ha)的详细信息:
== 二项堆( B0 B1 B2 )的详细信息:
1. 二项树B0:
41(0) is root
2. 二项树B1:
28(1) is root
33(0) is 28's child
3. 二项树B2:
7(2) is root
15(1) is 7's child
25(0) is 15's child
12(0) is 15's next
十四、 斐波那契堆之Java的实现
1) 概要
前面分别通过C和C++实现了斐波那契堆,本章给出斐波那契堆的Java版本。还是那句老话,三种实现的原理一样,择其一了解即可。
目录
1. 斐波那契堆的介绍
2. 斐波那契堆的基本操作
3. 斐波那契堆的Java实现(完整源码)
4. 斐波那契堆的Java测试程序
2) 斐波那契堆的介绍
斐波那契堆(Fibonacci heap)是一种可合并堆,可用于实现合并优先队列。它比二项堆具有更好的平摊分析性能,它的合并操作的时间复杂度是O(1)。
与二项堆一样,它也是由一组堆最小有序树组成,并且是一种可合并堆。
与二项堆不同的是,斐波那契堆中的树不一定是二项树;而且二项堆中的树是有序排列的,但是斐波那契堆中的树都是有根而无序的。
斐波那契堆的基本操作
3) 1. 基本定义
public class FibHeap {
private int keyNum; // 堆中节点的总数
private FibNode min; // 最小节点(某个最小堆的根节点)
private class FibNode {
int key; // 关键字(键值)
int degree; // 度数
FibNode left; // 左兄弟
FibNode right; // 右兄弟
FibNode child; // 第一个孩子节点
FibNode parent; // 父节点
boolean marked; // 是否被删除第一个孩子
public FibNode(int key) {
this.key = key;
this.degree = 0;
this.marked = false;
this.left = this;
this.right = this;
this.parent = null;
this.child = null;
}
}
...
}
FibNode是斐波那契堆的节点类,它包含的信息较多。key是用于比较节点大小的,degree是记录节点的度,left和right分别是指向节点的左右兄弟,child是节点的第一个孩子,parent是节点的父节点,marked是记录该节点是否被删除第1个孩子(marked在删除节点时有用)。
FibHeap是斐波那契堆对应的类。min是保存当前堆的最小节点,keyNum用于记录堆中节点的总数,maxDegree用于记录堆中最大度,而cons在删除节点时来暂时保存堆数据的临时空间。
上面是斐波那契堆的两种不同结构图的对比。从中可以看出,斐波那契堆是由一组最小堆组成,这些最小堆的根节点组成了双向链表(后文称为"根链表");斐波那契堆中的最小节点就是"根链表中的最小节点"!
PS. 上面这幅图的结构和测试代码中的"基本信息"测试函数的结果是一致的;你可以通过测试程序来亲自验证!
4) 2. 插入操作
插入操作非常简单:插入一个节点到堆中,直接将该节点插入到"根链表的min节点"之前即可;若被插入节点比"min节点"小,则更新"min节点"为被插入节点。
上面是插入操作的示意图。
斐波那契堆的根链表是"双向链表",这里将min节点看作双向联表的表头(后文也是如此)。在插入节点时,每次都是"将节点插入到min节点之前(即插入到双链表末尾)"。此外,对于根链表中最小堆都只有一个节点的情况,插入操作就很演化成双向链表的插入操作。
此外,插入操作示意图与测试程序中的"插入操作"相对应,感兴趣的可以亲自验证。
插入操作代码
/*
* 将node堆结点加入root结点之前(循环链表中)
* a …… root
* a …… node …… root
*/
private void addNode(FibNode node, FibNode root) {
node.left = root.left;
root.left.right = node;
node.right = root;
root.left = node;
}
/*
* 将节点node插入到斐波那契堆中
*/
private void insert(FibNode node) {
if (keyNum == 0)
min = node;
else {
addNode(node, min);
if (node.key < min.key)
min = node;
}
keyNum++;
}
/*
* 新建键值为key的节点,并将其插入到斐波那契堆中
*/
public void insert(int key) {
FibNode node;
node = new FibNode(key);
if (node == null)
return ;
insert(node);
}
5) 3. 合并操作
合并操作和插入操作的原理非常类似:将一个堆的根链表插入到另一个堆的根链表上即可。简单来说,就是将两个双链表拼接成一个双向链表。
上面是合并操作的示意图。该操作示意图与测试程序中的"合并操作"相对应!
合并操作代码
/*
* 将双向链表b链接到双向链表a的后面
*/
private void catList(FibNode a, FibNode b) {
FibNode tmp;
tmp = a.right;
a.right = b.right;
b.right.left = a;
b.right = tmp;
tmp.left = b;
}
/*
* 将other合并到当前堆中
*/
public void union(FibHeap other) {
if (other==null)
return ;
if((this.min) == null) { // this无"最小节点"
this.min = other.min;
this.keyNum = other.keyNum;
other = null;
} else if((other.min) == null) { // this有"最小节点" && other无"最小节点"
other = null;
} else { // this有"最小节点" && other有"最小节点"
// 将"other中根链表"添加到"this"中
catList(this.min, other.min) ;
if (this.min.key > other.min.key)
this.min = other.min;
this.keyNum += other.keyNum;
other = null;;
}
}
6) 4. 取出最小节点
抽取最小结点的操作是斐波那契堆中较复杂的操作。
(1)将要抽取最小结点的子树都直接串联在根表中;









(2)合并所有degree相等的树,直到没有相等的degree的树。

上面是取出最小节点的示意图。图中应该写的非常明白了,若有疑问,看代码。
此外,该操作示意图与测试程序中的"删除最小节点"相对应!有兴趣的可以亲自验证。
取出最小节点代码
/*
* 将node链接到root根结点
*/
private void link(FibNode node, FibNode root) {
// 将node从双链表中移除
removeNode(node);
// 将node设为root的孩子
if (root.child == null)
root.child = node;
else
addNode(node, root.child);
node.parent = root;
root.degree++;
node.marked = false;
}
/*
* 合并斐波那契堆的根链表中左右相同度数的树
*/
private void consolidate() {
// 计算log2(keyNum),floor意味着向上取整!
// ex. log2(13) = 3,向上取整为4。
int maxDegree = (int) Math.floor(Math.log(keyNum) / Math.log(2.0));
int D = maxDegree + 1;
FibNode[] cons = new FibNode[D+1];
for (int i = 0; i < D; i++)
cons[i] = null;
// 合并相同度的根节点,使每个度数的树唯一
while (min != null) {
FibNode x = extractMin(); // 取出堆中的最小树(最小节点所在的树)
int d = x.degree; // 获取最小树的度数
// cons[d] != null,意味着有两棵树(x和y)的"度数"相同。
while (cons[d] != null) {
FibNode y = cons[d]; // y是"与x的度数相同的树"
if (x.key > y.key) { // 保证x的键值比y小
FibNode tmp = x;
x = y;
y = tmp;
}
link(y, x); // 将y链接到x中
cons[d] = null;
d++;
}
cons[d] = x;
}
min = null;
// 将cons中的结点重新加到根表中
for (int i=0; i<D; i++) {
if (cons[i] != null) {
if (min == null)
min = cons[i];
else {
addNode(cons[i], min);
if ((cons[i]).key < min.key)
min = cons[i];
}
}
}
}
/*
* 移除最小节点
*/
public void removeMin() {
if (min==null)
return ;
FibNode m = min;
// 将min每一个儿子(儿子和儿子的兄弟)都添加到"斐波那契堆的根链表"中
while (m.child != null) {
FibNode child = m.child;
removeNode(child);
if (child.right == child)
m.child = null;
else
m.child = child.right;
addNode(child, min);
child.parent = null;
}
// 将m从根链表中移除
removeNode(m);
// 若m是堆中唯一节点,则设置堆的最小节点为null;
// 否则,设置堆的最小节点为一个非空节点(m.right),然后再进行调节。
if (m.right == m)
min = null;
else {
min = m.right;
consolidate();
}
keyNum--;
m = null;
}
7) 5. 减小节点值
减少斐波那契堆中的节点的键值,这个操作的难点是:如果减少节点后破坏了"最小堆"性质,如何去维护呢?下面对一般性情况进行分析。
(1) 首先,将"被减小节点"从"它所在的最小堆"剥离出来;然后将"该节点"关联到"根链表"中。 倘若被减小的节点不是单独一个节点,而是包含子树的树根。则是将以"被减小节点"为根的子树从"最小堆"中剥离出来,然后将该树关联到根链表中。
(2) 接着,对"被减少节点"的原父节点进行"级联剪切"。所谓"级联剪切",就是在被减小节点破坏了最小堆性质,并被切下来之后;再从"它的父节点"进行递归级联剪切操作。
而级联操作的具体动作则是:若父节点(被减小节点的父节点)的marked标记为false,则将其设为true,然后退出。
否则,将父节点从最小堆中切下来(方式和"切被减小节点的方式"一样);然后递归对祖父节点进行"级联剪切"。
marked标记的作用就是用来标记"该节点的子节点是否有被删除过",它的作用是来实现级联剪切。而级联剪切的真正目的是为了防止"最小堆"由二叉树演化成链表。
(3) 最后,别忘了对根链表的最小节点进行更新。
上面是减小节点值的示意图。该操作示意图与测试程序中的"减小节点"相对应!
减小节点值的代码
/*
* 修改度数
*/
private void renewDegree(FibNode parent, int degree) {
parent.degree -= degree;
if (parent. parent != null)
renewDegree(parent.parent, degree);
}
/*
* 将node从父节点parent的子链接中剥离出来,
* 并使node成为"堆的根链表"中的一员。
*/
private void cut(FibNode node, FibNode parent) {
removeNode(node);
renewDegree(parent, node.degree);
// node没有兄弟
if (node == node.right)
parent.child = null;
else
parent.child = node.right;
node.parent = null;
node.left = node.right = node;
node.marked = false;
// 将"node所在树"添加到"根链表"中
addNode(node, min);
}
/*
* 对节点node进行"级联剪切"
*
* 级联剪切:如果减小后的结点破坏了最小堆性质,
* 则把它切下来(即从所在双向链表中删除,并将
* 其插入到由最小树根节点形成的双向链表中),
* 然后再从"被切节点的父节点"到所在树根节点递归执行级联剪枝
*/
private void cascadingCut(FibNode node) {
FibNode parent = node.parent;
if (parent != null) {
if (node.marked == false)
node.marked = true;
else {
cut(node, parent);
cascadingCut(parent);
}
}
}
/*
* 将斐波那契堆中节点node的值减少为key
*/
private void decrease(FibNode node, int key) {
if (min==null ||node==null)
return ;
if (key > node.key) {
System.out.printf("decrease failed: the new key(%d) is no smaller than current key(%d)\n", key, node.key);
return ;
}
FibNode parent = node.parent;
node.key = key;
if (parent!=null && (node.key < parent.key)) {
// 将node从父节点parent中剥离出来,并将node添加到根链表中
cut(node, parent);
cascadingCut(parent);
}
// 更新最小节点
if (node.key < min.key)
min = node;
}
8) 6. 增加节点值
增加节点值和减少节点值类似,这个操作的难点也是如何维护"最小堆"性质。思路如下:
(1) 将"被增加节点"的"左孩子和左孩子的所有兄弟"都链接到根链表中。
(2) 接下来,把"被增加节点"添加到根链表;但是别忘了对其进行级联剪切。
上面是增加节点值的示意图。该操作示意图与测试程序中的"增大节点"相对应!
增加节点值的代码
/*
* 将斐波那契堆中节点node的值增加为key
*/
private void increase(FibNode node, int key) {
if (min==null ||node==null)
return ;
if ( key <= node.key) {
System.out.printf("increase failed: the new key(%d) is no greater than current key(%d)\n", key, node.key);
return ;
}
// 将node每一个儿子(不包括孙子,重孙,...)都添加到"斐波那契堆的根链表"中
while (node.child != null) {
FibNode child = node.child;
removeNode(child); // 将child从node的子链表中删除
if (child.right == child)
node.child = null;
else
node.child = child.right;
addNode(child, min); // 将child添加到根链表中
child.parent = null;
}
node.degree = 0;
node.key = key;
// 如果node不在根链表中,
// 则将node从父节点parent的子链接中剥离出来,
// 并使node成为"堆的根链表"中的一员,
// 然后进行"级联剪切"
// 否则,则判断是否需要更新堆的最小节点
FibNode parent = node.parent;
if(parent != null) {
cut(node, parent);
cascadingCut(parent);
} else if(min == node) {
FibNode right = node.right;
while(right != node) {
if(node.key > right.key)
min = right;
right = right.right;
}
}
}
9) 7. 删除节点
删除节点,本文采用了操作是:"取出最小节点"和"减小节点值"的组合。
(1) 先将被删除节点的键值减少。减少后的值要比"原最小节点的值"即可。
(2) 接着,取出最小节点即可。
删除节点值的代码
/*
* 删除结点node
*/
private void remove(FibNode node) {
int m = min.key;
decrease(node, m-1);
removeMin();
}
注意:关于斐波那契堆的"更新"、"打印"、"销毁"等接口就不再单独介绍了。后文的源码中有给出它们的实现代码,Please RTFSC(Read The Fucking Source Code)!
10) 斐波那契堆的Java实现(完整源码)
斐波那契堆的实现文件(FibHeap.java)
/**
* Java 语言: 斐波那契堆
*
* @author skywang
* @date 2014/04/07
*/
public class FibHeap {
private int keyNum; // 堆中节点的总数
private FibNode min; // 最小节点(某个最小堆的根节点)
private class FibNode {
int key; // 关键字(键值)
int degree; // 度数
FibNode left; // 左兄弟
FibNode right; // 右兄弟
FibNode child; // 第一个孩子节点
FibNode parent; // 父节点
boolean marked; // 是否被删除第一个孩子
public FibNode(int key) {
this.key = key;
this.degree = 0;
this.marked = false;
this.left = this;
this.right = this;
this.parent = null;
this.child = null;
}
}
public FibHeap() {
this.keyNum = 0;
this.min = null;
}
/*
* 将node从双链表移除
*/
private void removeNode(FibNode node) {
node.left.right = node.right;
node.right.left = node.left;
}
/*
* 将node堆结点加入root结点之前(循环链表中)
* a …… root
* a …… node …… root
*/
private void addNode(FibNode node, FibNode root) {
node.left = root.left;
root.left.right = node;
node.right = root;
root.left = node;
}
/*
* 将节点node插入到斐波那契堆中
*/
private void insert(FibNode node) {
if (keyNum == 0)
min = node;
else {
addNode(node, min);
if (node.key < min.key)
min = node;
}
keyNum++;
}
/*
* 新建键值为key的节点,并将其插入到斐波那契堆中
*/
public void insert(int key) {
FibNode node;
node = new FibNode(key);
if (node == null)
return ;
insert(node);
}
/*
* 将双向链表b链接到双向链表a的后面
*/
private void catList(FibNode a, FibNode b) {
FibNode tmp;
tmp = a.right;
a.right = b.right;
b.right.left = a;
b.right = tmp;
tmp.left = b;
}
/*
* 将other合并到当前堆中
*/
public void union(FibHeap other) {
if (other==null)
return ;
if((this.min) == null) { // this无"最小节点"
this.min = other.min;
this.keyNum = other.keyNum;
other = null;
} else if((other.min) == null) { // this有"最小节点" && other无"最小节点"
other = null;
} else { // this有"最小节点" && other有"最小节点"
// 将"other中根链表"添加到"this"中
catList(this.min, other.min) ;
if (this.min.key > other.min.key)
this.min = other.min;
this.keyNum += other.keyNum;
other = null;;
}
}
/*
* 将"堆的最小结点"从根链表中移除,
* 这意味着"将最小节点所属的树"从堆中移除!
*/
private FibNode extractMin() {
FibNode p = min;
if (p == p.right)
min = null;
else {
removeNode(p);
min = p.right;
}
p.left = p.right = p;
return p;
}
/*
* 将node链接到root根结点
*/
private void link(FibNode node, FibNode root) {
// 将node从双链表中移除
removeNode(node);
// 将node设为root的孩子
if (root.child == null)
root.child = node;
else
addNode(node, root.child);
node.parent = root;
root.degree++;
node.marked = false;
}
/*
* 合并斐波那契堆的根链表中左右相同度数的树
*/
private void consolidate() {
// 计算log2(keyNum),floor意味着向上取整!
// ex. log2(13) = 3,向上取整为4。
int maxDegree = (int) Math.floor(Math.log(keyNum) / Math.log(2.0));
int D = maxDegree + 1;
FibNode[] cons = new FibNode[D+1];
for (int i = 0; i < D; i++)
cons[i] = null;
// 合并相同度的根节点,使每个度数的树唯一
while (min != null) {
FibNode x = extractMin(); // 取出堆中的最小树(最小节点所在的树)
int d = x.degree; // 获取最小树的度数
// cons[d] != null,意味着有两棵树(x和y)的"度数"相同。
while (cons[d] != null) {
FibNode y = cons[d]; // y是"与x的度数相同的树"
if (x.key > y.key) { // 保证x的键值比y小
FibNode tmp = x;
x = y;
y = tmp;
}
link(y, x); // 将y链接到x中
cons[d] = null;
d++;
}
cons[d] = x;
}
min = null;
// 将cons中的结点重新加到根表中
for (int i=0; i<D; i++) {
if (cons[i] != null) {
if (min == null)
min = cons[i];
else {
addNode(cons[i], min);
if ((cons[i]).key < min.key)
min = cons[i];
}
}
}
}
/*
* 移除最小节点
*/
public void removeMin() {
if (min==null)
return ;
FibNode m = min;
// 将min每一个儿子(儿子和儿子的兄弟)都添加到"斐波那契堆的根链表"中
while (m.child != null) {
FibNode child = m.child;
removeNode(child);
if (child.right == child)
m.child = null;
else
m.child = child.right;
addNode(child, min);
child.parent = null;
}
// 将m从根链表中移除
removeNode(m);
// 若m是堆中唯一节点,则设置堆的最小节点为null;
// 否则,设置堆的最小节点为一个非空节点(m.right),然后再进行调节。
if (m.right == m)
min = null;
else {
min = m.right;
consolidate();
}
keyNum--;
m = null;
}
/*
* 获取斐波那契堆中最小键值;失败返回-1
*/
public int minimum() {
if (min==null)
return -1;
return min.key;
}
/*
* 修改度数
*/
private void renewDegree(FibNode parent, int degree) {
parent.degree -= degree;
if (parent. parent != null)
renewDegree(parent.parent, degree);
}
/*
* 将node从父节点parent的子链接中剥离出来,
* 并使node成为"堆的根链表"中的一员。
*/
private void cut(FibNode node, FibNode parent) {
removeNode(node);
renewDegree(parent, node.degree);
// node没有兄弟
if (node == node.right)
parent.child = null;
else
parent.child = node.right;
node.parent = null;
node.left = node.right = node;
node.marked = false;
// 将"node所在树"添加到"根链表"中
addNode(node, min);
}
/*
* 对节点node进行"级联剪切"
*
* 级联剪切:如果减小后的结点破坏了最小堆性质,
* 则把它切下来(即从所在双向链表中删除,并将
* 其插入到由最小树根节点形成的双向链表中),
* 然后再从"被切节点的父节点"到所在树根节点递归执行级联剪枝
*/
private void cascadingCut(FibNode node) {
FibNode parent = node.parent;
if (parent != null) {
if (node.marked == false)
node.marked = true;
else {
cut(node, parent);
cascadingCut(parent);
}
}
}
/*
* 将斐波那契堆中节点node的值减少为key
*/
private void decrease(FibNode node, int key) {
if (min==null ||node==null)
return ;
if (key > node.key) {
System.out.printf("decrease failed: the new key(%d) is no smaller than current key(%d)\n", key, node.key);
return ;
}
FibNode parent = node.parent;
node.key = key;
if (parent!=null && (node.key < parent.key)) {
// 将node从父节点parent中剥离出来,并将node添加到根链表中
cut(node, parent);
cascadingCut(parent);
}
// 更新最小节点
if (node.key < min.key)
min = node;
}
/*
* 将斐波那契堆中节点node的值增加为key
*/
private void increase(FibNode node, int key) {
if (min==null ||node==null)
return ;
if ( key <= node.key) {
System.out.printf("increase failed: the new key(%d) is no greater than current key(%d)\n", key, node.key);
return ;
}
// 将node每一个儿子(不包括孙子,重孙,...)都添加到"斐波那契堆的根链表"中
while (node.child != null) {
FibNode child = node.child;
removeNode(child); // 将child从node的子链表中删除
if (child.right == child)
node.child = null;
else
node.child = child.right;
addNode(child, min); // 将child添加到根链表中
child.parent = null;
}
node.degree = 0;
node.key = key;
// 如果node不在根链表中,
// 则将node从父节点parent的子链接中剥离出来,
// 并使node成为"堆的根链表"中的一员,
// 然后进行"级联剪切"
// 否则,则判断是否需要更新堆的最小节点
FibNode parent = node.parent;
if(parent != null) {
cut(node, parent);
cascadingCut(parent);
} else if(min == node) {
FibNode right = node.right;
while(right != node) {
if(node.key > right.key)
min = right;
right = right.right;
}
}
}
/*
* 更新斐波那契堆的节点node的键值为key
*/
private void update(FibNode node, int key) {
if(key < node.key)
decrease(node, key);
else if(key > node.key)
increase(node, key);
else
System.out.printf("No need to update!!!\n");
}
public void update(int oldkey, int newkey) {
FibNode node;
node = search(oldkey);
if (node!=null)
update(node, newkey);
}
/*
* 在最小堆root中查找键值为key的节点
*/
private FibNode search(FibNode root, int key) {
FibNode t = root; // 临时节点
FibNode p = null; // 要查找的节点
if (root==null)
return root;
do {
if (t.key == key) {
p = t;
break;
} else {
if ((p = search(t.child, key)) != null)
break;
}
t = t.right;
} while (t != root);
return p;
}
/*
* 在斐波那契堆中查找键值为key的节点
*/
private FibNode search(int key) {
if (min==null)
return null;
return search(min, key);
}
/*
* 在斐波那契堆中是否存在键值为key的节点。
* 存在返回true,否则返回false。
*/
public boolean contains(int key) {
return search(key)!=null ? true: false;
}
/*
* 删除结点node
*/
private void remove(FibNode node) {
int m = min.key;
decrease(node, m-1);
removeMin();
}
public void remove(int key) {
if (min==null)
return ;
FibNode node = search(key);
if (node==null)
return ;
remove(node);
}
/*
* 销毁斐波那契堆
*/
private void destroyNode(FibNode node) {
if(node == null)
return;
FibNode start = node;
do {
destroyNode(node.child);
// 销毁node,并将node指向下一个
node = node.right;
node.left = null;
} while(node != start);
}
public void destroy() {
destroyNode(min);
}
/*
* 打印"斐波那契堆"
*
* 参数说明:
* node -- 当前节点
* prev -- 当前节点的前一个节点(父节点or兄弟节点)
* direction -- 1,表示当前节点是一个左孩子;
* 2,表示当前节点是一个兄弟节点。
*/
private void print(FibNode node, FibNode prev, int direction) {
FibNode start=node;
if (node==null)
return ;
do {
if (direction == 1)
System.out.printf("%8d(%d) is %2d's child\n", node.key, node.degree, prev.key);
else
System.out.printf("%8d(%d) is %2d's next\n", node.key, node.degree, prev.key);
if (node.child != null)
print(node.child, node, 1);
// 兄弟节点
prev = node;
node = node.right;
direction = 2;
} while(node != start);
}
public void print() {
if (min==null)
return ;
int i=0;
FibNode p = min;
System.out.printf("== 斐波那契堆的详细信息: ==\n");
do {
i++;
System.out.printf("%2d. %4d(%d) is root\n", i, p.key, p.degree);
print(p.child, p, 1);
p = p.right;
} while (p != min);
System.out.printf("\n");
}
}
斐波那契堆的测试程序(Main.java)
/**
* Java 语言: 斐波那契堆
*
* @author skywang
* @date 2014/04/07
*/
public class Main {
private static final boolean DEBUG = false;
// 共8个
private static int a[] = {12, 7, 25, 15, 28, 33, 41, 1};
// 共14个
private static int b[] = {18, 35, 20, 42, 9,
31, 23, 6, 48, 11,
24, 52, 13, 2 };
// 验证"基本信息(斐波那契堆的结构)"
public static void testBasic() {
FibHeap hb=new FibHeap();
// 斐波那契堆hb
System.out.printf("== 斐波那契堆(hb)中依次添加: ");
for(int i=0; i<b.length; i++) {
System.out.printf("%d ", b[i]);
hb.insert(b[i]);
}
System.out.printf("\n");
System.out.printf("== 斐波那契堆(hb)删除最小节点\n");
hb.removeMin();
hb.print(); // 打印斐波那契堆hb
}
// 验证"插入操作"
public static void testInsert() {
FibHeap ha=new FibHeap();
// 斐波那契堆ha
System.out.printf("== 斐波那契堆(ha)中依次添加: ");
for(int i=0; i<a.length; i++) {
System.out.printf("%d ", a[i]);
ha.insert(a[i]);
}
System.out.printf("\n");
System.out.printf("== 斐波那契堆(ha)删除最小节点\n");
ha.removeMin();
ha.print(); // 打印斐波那契堆ha
System.out.printf("== 插入50\n");
ha.insert(50);
ha.print();
}
// 验证"合并操作"
public static void testUnion() {
FibHeap ha=new FibHeap();
FibHeap hb=new FibHeap();
// 斐波那契堆ha
System.out.printf("== 斐波那契堆(ha)中依次添加: ");
for(int i=0; i<a.length; i++) {
System.out.printf("%d ", a[i]);
ha.insert(a[i]);
}
System.out.printf("\n");
System.out.printf("== 斐波那契堆(ha)删除最小节点\n");
ha.removeMin();
ha.print(); // 打印斐波那契堆ha
// 斐波那契堆hb
System.out.printf("== 斐波那契堆(hb)中依次添加: ");
for(int i=0; i<b.length; i++) {
System.out.printf("%d ", b[i]);
hb.insert(b[i]);
}
System.out.printf("\n");
System.out.printf("== 斐波那契堆(hb)删除最小节点\n");
hb.removeMin();
hb.print(); // 打印斐波那契堆hb
// 将"斐波那契堆hb"合并到"斐波那契堆ha"中。
System.out.printf("== 合并ha和hb\n");
ha.union(hb);
ha.print();
}
// 验证"删除最小节点"
public static void testRemoveMin() {
FibHeap ha=new FibHeap();
FibHeap hb=new FibHeap();
// 斐波那契堆ha
System.out.printf("== 斐波那契堆(ha)中依次添加: ");
for(int i=0; i<a.length; i++) {
System.out.printf("%d ", a[i]);
ha.insert(a[i]);
}
System.out.printf("\n");
System.out.printf("== 斐波那契堆(ha)删除最小节点\n");
ha.removeMin();
//ha.print(); // 打印斐波那契堆ha
// 斐波那契堆hb
System.out.printf("== 斐波那契堆(hb)中依次添加: ");
for(int i=0; i<b.length; i++) {
System.out.printf("%d ", b[i]);
hb.insert(b[i]);
}
System.out.printf("\n");
System.out.printf("== 斐波那契堆(hb)删除最小节点\n");
hb.removeMin();
//hb.print(); // 打印斐波那契堆hb
// 将"斐波那契堆hb"合并到"斐波那契堆ha"中。
System.out.printf("== 合并ha和hb\n");
ha.union(hb);
ha.print();
System.out.printf("== 删除最小节点\n");
ha.removeMin();
ha.print();
}
// 验证"减小节点"
public static void testDecrease() {
FibHeap hb=new FibHeap();
// 斐波那契堆hb
System.out.printf("== 斐波那契堆(hb)中依次添加: ");
for(int i=0; i<b.length; i++) {
System.out.printf("%d ", b[i]);
hb.insert(b[i]);
}
System.out.printf("\n");
System.out.printf("== 斐波那契堆(hb)删除最小节点\n");
hb.removeMin();
hb.print(); // 打印斐波那契堆hb
System.out.printf("== 将20减小为2\n");
hb.update(20, 2);
hb.print();
}
// 验证"增大节点"
public static void testIncrease() {
FibHeap hb=new FibHeap();
// 斐波那契堆hb
System.out.printf("== 斐波那契堆(hb)中依次添加: ");
for(int i=0; i<b.length; i++) {
System.out.printf("%d ", b[i]);
hb.insert(b[i]);
}
System.out.printf("\n");
System.out.printf("== 斐波那契堆(hb)删除最小节点\n");
hb.removeMin();
hb.print(); // 打印斐波那契堆hb
System.out.printf("== 将20增加为60\n");
hb.update(20, 60);
hb.print();
}
// 验证"删除节点"
public static void testDelete() {
FibHeap hb=new FibHeap();
// 斐波那契堆hb
System.out.printf("== 斐波那契堆(hb)中依次添加: ");
for(int i=0; i<b.length; i++) {
System.out.printf("%d ", b[i]);
hb.insert(b[i]);
}
System.out.printf("\n");
System.out.printf("== 斐波那契堆(hb)删除最小节点\n");
hb.removeMin();
hb.print(); // 打印斐波那契堆hb
System.out.printf("== 删除节点20\n");
hb.remove(20);
hb.print();
}
public static void main(String[] args) {
// 验证"基本信息(斐波那契堆的结构)"
testBasic();
// 验证"插入操作"
//testInsert();
// 验证"合并操作"
//testUnion();
// 验证"删除最小节点"
//testRemoveMin();
// 验证"减小节点"
//testDecrease();
// 验证"增大节点"
//testIncrease();
// 验证"删除节点"
//testDelete();
}
}
11) 斐波那契堆的Java测试程序
斐波那契堆的测试程序包括了"插入"、"合并"、"增大"、"减小"、"删除"、"基本信息"等几种功能的测试代码。默认是运行的"基本信息(验证斐波那契堆的结构)"测试代码,你可以根据自己的需要来对相应的功能进行验证!
下面是基本信息测试代码的运行结果:
== 斐波那契堆(hb)中依次添加: 18 35 20 42 9 31 23 6 48 11 24 52 13 2
== 斐波那契堆(hb)删除最小节点
== 斐波那契堆的详细信息: ==
1. 6(3) is root
9(0) is 6's child
18(1) is 9's next
35(0) is 18's child
20(2) is 18's next
42(0) is 20's child
23(1) is 42's next
31(0) is 23's child
2. 11(2) is root
48(0) is 11's child
24(1) is 48's next
52(0) is 24's child


3. 13(0) is root
仅供个人学习,如有抄袭请包容.....















 85
85

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









