







用GBDT和graphlab实现kaggle比赛 租车量预测
这里我用的是graphlab包,而不是sklearn。借鉴上面的例子,完成仓库优化,但是可能由于库的原因,与上面的例子有一定的出入!!!
数据准备
导入数据
import graphlab
data_day=graphlab.SFrame("nv_cai01_day.csv")
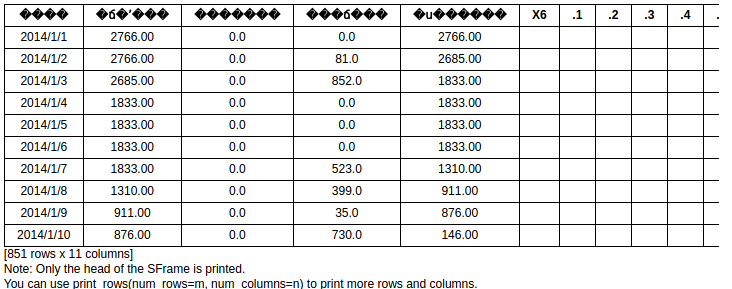
整理数据
a=data_day.column_names()
a=a[0:5]
data_day_2=data_day[a]
print data_day_2.column_names()
# 发现结果是['\xc8\xd5\xc6\xda','\xc8\xd5\xb3\xf5\xca\xbc\xbf\xe2\xb4\xe6','\xb5\xb1\xc8\xd5\xc8\xeb\xbf\xe2','\xb5\xb1\xc8\xd5\xb3\xf6\xbf\xe2','\xc8\xd5\xbd\xe1\xca\xf8\xbf\xe2\xb4\xe6']说明中文显示有误,下面进行修改
data_day_2.rename({'\xc8\xd5\xc6\xda':'data',
'\xc8\xd5\xb3\xf5\xca\xbc\xbf\xe2\xb4\xe6':'Daily initial inventory',
'\xb5\xb1\xc8\xd5\xc8\xeb\xbf\xe2':'input',
'\xb5\xb1\xc8\xd5\xb3\xf6\xbf\xe2':'output',
data_day_2.dtype()# 结果为[str, str, float, float, str]
于是下面把str转化为int
new1=data_day_2['Daily initial inventory']
new4=data_day_2['End of day inventory']
def str_to_float(data):
li=[];
a='';
for i in data:
if i[0]=='(':
a=i.split('.00')[0].split('(')[1]
a=int(a)
li.append(a)
else:
a=i.split('.00')[0]
a=int(a)
li.append(a)
return li
day1=str_to_float(new1)
day4=str_to_float(new4)
data_day_2.remove_columns(column_names=['Daily initial inventory','End of day inventory'])
data_day_2.add_column(graphlab.SArray(day1),name='Daily initial inventory').add_column(graphlab.SArray(day4),name='End of day inventory')结果为
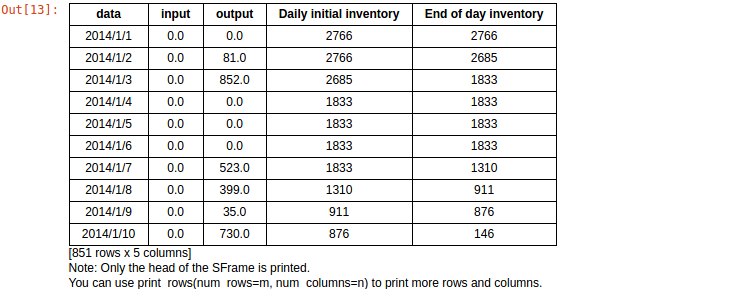
data_day_2.show()训练模型
最基本模型
train_data,test_data=data_day_2.random_split(0.8,seed=0)
features=['data','input','Daily initial inventory']
m=graphlab.boosted_trees_regression.create(train_data,target='output',features=features,max_iterations=100)
m.evaluate(test_data)结果为{'max_error': 1484.4045238494873, 'rmse': 250.960051855327}
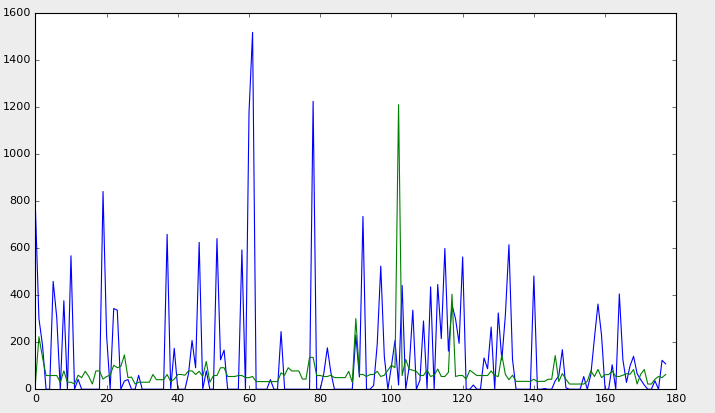
哎,问题很大啊!!!
进行简单的特征工程 改进模型
我们发现,以天为变量,发现0太多了,稀疏矩阵怎么处理???现在还不会,等会了,再考虑!!!可是如果以周来看,情况就好很多!!
import graphlab
data_day=graphlab.SFrame("nv_cai01_week.csv")
a=data_day.column_names()
a=a[0:5]
print a
data_day_2=data_day[a]
print data_day_2
data_day_2.column_names()
data_day_2.rename({'\xd6\xdc\xca\xfd':'data',
'\xd6\xdc\xb3\xf5\xbf\xe2\xb4\xe6':'Daily initial inventory',
'\xb5\xb1\xd6\xdc\xc8\xeb\xbf\xe2':'input',
'\xb5\xb1\xd6\xdc\xb3\xf6\xbf\xe2':'output',
'\xd6\xdc\xc4\xa9\xbf\xe2\xb4\xe6':'End of day inventory'})
new1=data_day_2['Daily initial inventory']
new4=data_day_2['End of day inventory']
ef str_to_float(data):
li=[];
a='';
for i in data:
if i[0]=='(':
a=i.split('.00')[0].split('(')[1]
a=int(a)
li.append(a)
else:
a=i.split('.00')[0]
a=int(a)
li.append(a)
return li
day1=str_to_float(new1)
day4=str_to_float(new4)
data_day_2.remove_columns(column_names=['Daily initial inventory','End of day inventory'])
data_day_2.add_column(graphlab.SArray(day1),name='Daily initial inventory').add_column(graphlab.SArray(day4),name='End of day inventory')得到的原始数据为
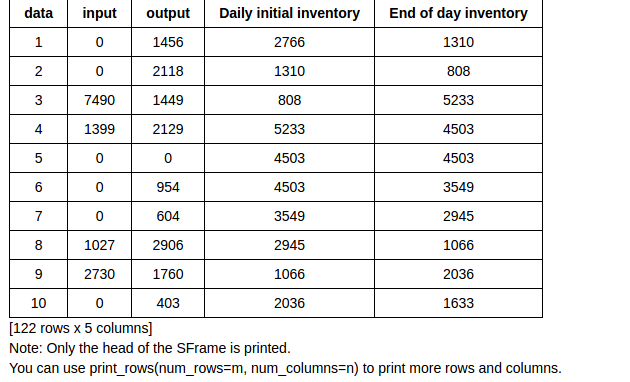
data_day_2.show()发现
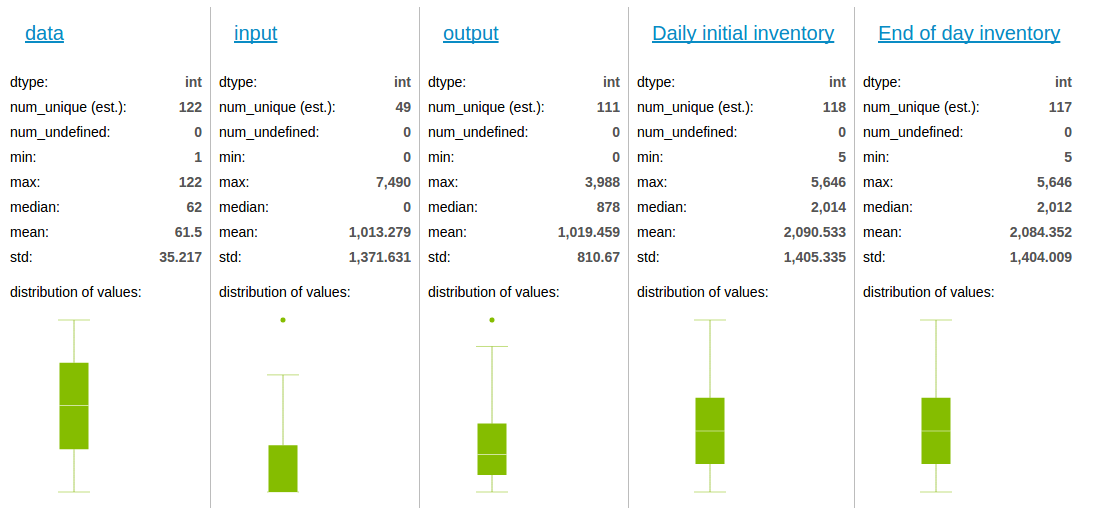
发现离群点比以天 为单位少的多
训练基本模型
train_data,test_data=data_day_2.random_split(0.8,seed=0)
features=['data','input','Daily initial inventory']
m=graphlab.boosted_trees_regression.create(train_data,target='output',features=features,max_iterations=100)打印出来
import matplotlib.pyplot as plt
predoction=m.predict(test_data)
%matplotlib qt
fir=plt.figure()
a=fir.add_subplot(211)
a.plot(range(len(predoction)),test_data['output'])
a.plot(range(len(predoction)),predoction)
predoction=m.predict(train_data)
b=fir.add_subplot(212)
b.plot(range(len(predoction)),train_data['output'])
b.plot(range(len(predoction)),predoction)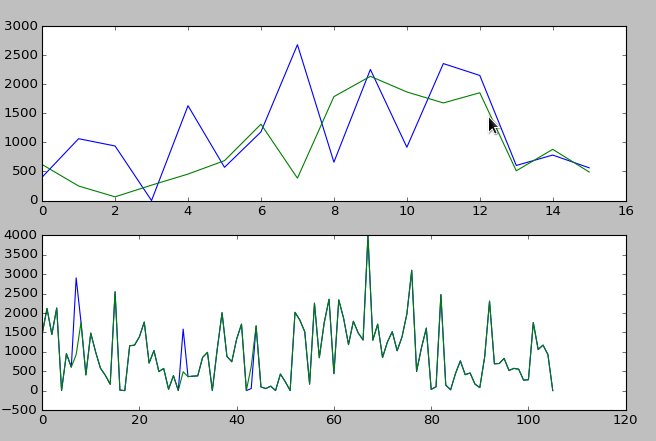
下面的是训练集 与 对训练集预测得到的图形,发现 二者几乎完全重合
上面的是测试集 与 对测试集预测得到的图形,发现 有一定的偏差
训练集合预测太好,测试集有大的偏差,说明发生了过拟合现象
m.show()
从图中也可以看到,training rmse 很小,而 validation rmse 太大
这也证明了有过拟合现象。
发现validation rmse的值为 1347.167 ,我们的目的就是要削减他。
寻找最好的参数
def parameter_search(training_url, validation_url,params):
"""
Return the optimal parameters in the given search space.
The parameter returned has the lowest validation rmse.
"""
job= graphlab.toolkits.model_parameter_search.create((training_url,validation_url),
graphlab.boosted_trees_regression.create,model_parameters=params)
# When the job is done, the result is stored in an SFrame
# The result contains attributes of the models in the search space
# and the validation error in RMSE.
result =job.get_results().sort('validation_rmse', ascending=True)
# Return the parameters with the lowest validation error.
optimal_params = job.get_best_params()
optimal_rmse = result['validation_rmse'][0]
print 'Optimal parameters: %s' % str(optimal_params)
print 'RMSE: %s' % str(optimal_rmse)
return optimal_params
ntrees = 100
fixed_params = {'features': [features],
'max_depth': [1, 5,10,15, 20],
'min_child_weight': [1,5, 10,15, 20],
'step_size': 0.05,
'max_iterations': ntrees}
fixed_params['target'] = 'output'
params_log_output = parameter_search(train_data,
test_data,
fixed_params)
params_log_output.pop('target','features')
m_output = graphlab.boosted_trees_regression.create(train_data,
features=features,
target='output',
max_iterations=params_log_output['max_iterations'],
max_depth=params_log_output['max_depth'],
step_size=params_log_output['step_size'],
min_loss_reduction=params_log_output['min_loss_reduction'],
min_child_weight=params_log_output['min_child_weight'],
row_subsample=params_log_output['row_subsample'],
column_subsample=params_log_output['column_subsample'],
verbose=True)
显示
predoction=m_output.predict(test_data)
%matplotlib qt
fir=plt.figure()
a=fir.add_subplot(211)
a.plot(range(len(predoction)),test_data['output'])
a.plot(range(len(predoction)),predoction)
predoction=m_output.predict(train_data)
b=fir.add_subplot(212)
b.plot(range(len(predoction)),train_data['output'])
b.plot(range(len(predoction)),predoction)
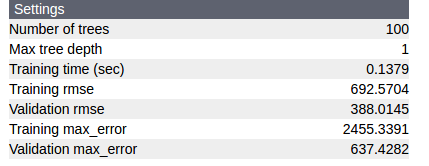
发现 validation rmse 由 1347.167 减小到了388.0145 ,而 training rmse 变大了
数据清洗,发现有的数据太大,决定删除少部分过火的数据
发现爱那个原始数据有一些离群点,比如再output中,一般数据都达到了几千量级,但是有9 个数据却是0,所以认为这9个数据对模型拟合有很大的影响,则尝试删除这9个数据 和最大值。
data_day_2= data_day_2[data_day_2['output']!= data_day_2['output'].max()]
data_day_2=data_day_2[data_day_2['output']!=0]# 训练模型
train_data,test_data=data_day_2.random_split(0.8,seed=0)
train_data,valia=train_data.random_split(0.95,seed=0)
features=['data','input','Daily initial inventory']
m2=graphlab.boosted_trees_regression.create(train_data,target='output',features=features,max_iterations=100,validation_set=valia)
# 画图
predoction=m.predict(test_data)
%matplotlib qt
fir=plt.figure()
a=fir.add_subplot(211)
a.plot(range(len(predoction)),test_data['output'])
a.plot(range(len(predoction)),predoction)
predoction=m.predict(train_data)
b=fir.add_subplot(212)
b.plot(range(len(predoction)),train_data['output'])
b.plot(range(len(predoction)),predoction)
m2.show()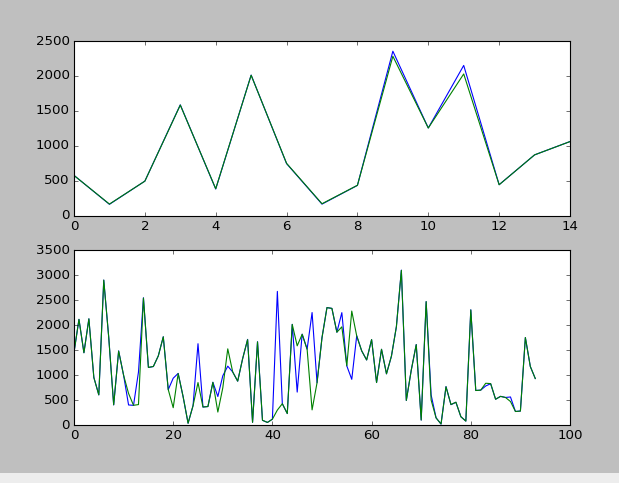
发现测试集拟合的还可以!!!















 756
756

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









