







“Hadoop: The Definitive Guild” 这本书的例子都是使用NCDC 天气数据的,但由于书的出版和现在已经有一段时间了,NCDC现在提供的原始数据结构已经有了一些变化,本文主要描述书中附表C中的GSOD数据的预处理过程。
GSOD的数据可以在NCDC官网找到:
其实就是如下FTP信息:
ftp://ftp.ncdc.noaa.gov/pub/data/gsod
路径:/pub/data/gsod
进入FTP你会发现所有天气信息按年保存文件夹里面,当前有115个文件夹(1901至2015年):
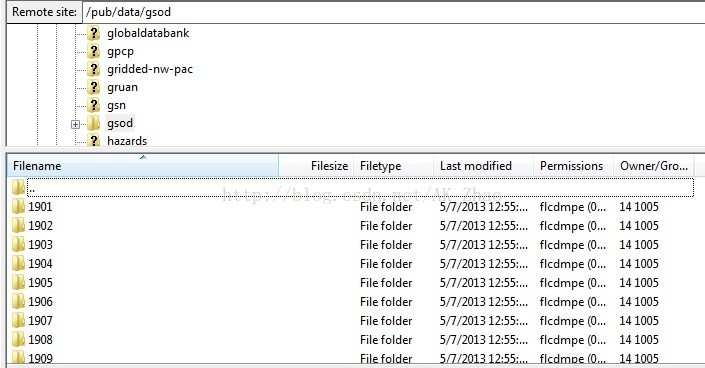
以2012年的数据为例,里面含有12409个文件:这表示里面含有全球12408个观测站点提供的数据,分别各占一个gz包,每一年的数据最终被打包在gsod_2012.tar的文件里面:
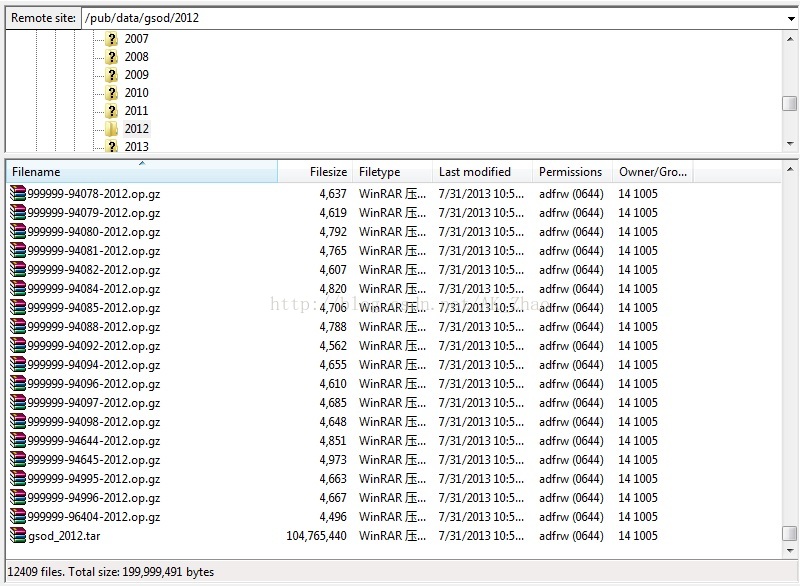
如果这时候你打算下载所有包,那你需要下载约40万个,所以我们filter掉gz包,只需要下载115个tar包就含有所有数据。
在FileZila中新建一个filter:

在远程文件中应用该设置:

此时FTP上只显示tar文件:

然后下载整个gsod文件夹到本地,最终是3.43GB的数据.
每个tar文件是如下文件结构:

首先介绍下我的环境:
Hadoop 2.6.0 一个主节点 三个从节点:
Ubuntu 14.04.01
192.168.137.10 namenode
192.168.137.11 datanode1
192.168.137.12 datanode2
192.168.137.13 datanode3
首先将Windows本地的gsod文件夹上传到namenode:

在HDFS上新建GSOD文件夹保存所有tar文件,新建GSOD_ALL文件夹来保存打包后的文件:
hdfs dfs -mkdir /GSOD /GSOD_ALL
hdfs dfs -ls /
输出如下:

将本地的namenode上的gsod文件夹里的文件上传到HDFS上:
hdfs dfs -put gsod/* /GSOD/
本例中我只上传了10个文件到HDFS:
hadoopid@namenode:~$ hdfs dfs -ls /GSOD
Found 10 items
drwxr-xr-x - hadoopid supergroup 0 2015-01-26 11:06 /GSOD/2000
drwxr-xr-x - hadoopid supergroup 0 2015-01-26 11:06 /GSOD/2001
drwxr-xr-x - hadoopid supergroup 0 2015-01-26 11:06 /GSOD/2002
drwxr-xr-x - hadoopid supergroup 0 2015-01-26 11:06 /GSOD/2003
drwxr-xr-x - hadoopid supergroup 0 2015-01-26 11:06 /GSOD/2004
drwxr-xr-x - hadoopid supergroup 0 2015-01-26 11:06 /GSOD/2005
drwxr-xr-x - hadoopid supergroup 0 2015-01-26 11:06 /GSOD/2006
drwxr-xr-x - hadoopid supergroup 0 2015-01-26 11:06 /GSOD/2007
drwxr-xr-x - hadoopid supergroup 0 2015-01-26 11:06 /GSOD/2008
drwxr-xr-x - hadoopid supergroup 0 2015-01-26 11:06 /GSOD/2009
你可以通过如下命令查看文件块的分布情况:
hdfs fsck /GSOD -files -blocks -racks
/GSOD/2007 <dir>
/GSOD/2007/gsod_2007.tar 88842240 bytes, 1 block(s): OK
0. BP-1861083552-192.168.137.10-1420535325500:blk_1073742813_2006 len=88842240 repl=3 [/default-rack/192.168.137.13:50010, /default-rack/192.168.137.12:50010, /default-rack/192.168.137.11:50010]
/GSOD/2008 <dir>
/GSOD/2008/gsod_2008.tar 59555840 bytes, 1 block(s): OK
0. BP-1861083552-192.168.137.10-1420535325500:blk_1073742814_2007 len=59555840 repl=3 [/default-rack/192.168.137.12:50010, /default-rack/192.168.137.11:50010, /default-rack/192.168.137.13:50010]
/GSOD/2009 <dir>
/GSOD/2009/gsod_2009.tar 47206400 bytes, 1 block(s): OK
0. BP-1861083552-192.168.137.10-1420535325500:blk_1073742815_2008 len=47206400 repl=3 [/default-rack/192.168.137.13:50010, /default-rack/192.168.137.11:50010, /default-rack/192.168.137.12:50010]
Status: HEALTHY
Total size: 754892800 B
Total dirs: 11
Total files: 10
Total symlinks: 0
Total blocks (validated): 10 (avg. block size 75489280 B)
Minimally replicated blocks: 10 (100.0 %)
Over-replicated blocks: 0 (0.0 %)
Under-replicated blocks: 0 (0.0 %)
Mis-replicated blocks: 0 (0.0 %)
Default replication factor: 3
Average block replication: 3.0
Corrupt blocks: 0
Missing replicas: 0 (0.0 %)
Number of data-nodes: 3
Number of racks: 1
FSCK ended at Mon Jan 26 11:09:42 CST 2015 in 8 milliseconds
接下来我们在Hadoop上处理这些文件:
首先我新建了一个generate_input_list.sh来生成MR的input文件
#!/bin/bash
a=$1
rm ncdc_files.txt
hdfs dfs -rm /ncdc_files.txt
while [ $a -le $2 ]
do
filename="/GSOD/${a}/gsod_${a}.tar"
echo -e "$filename" >>ncdc_files.txt
a=`expr $a + 1`
done
hdfs dfs -put ncdc_files.txt /
chmod +x generate_input_list.sh
使用如下命令来生成在本例中需要处理的文件列表:
./generate_input_list.sh 2000 2009
more ncdc_files.txt
hadoopid@namenode:~$ more ncdc_files.txt
/GSOD/2000/gsod_2000.tar
/GSOD/2001/gsod_2001.tar
/GSOD/2002/gsod_2002.tar
/GSOD/2003/gsod_2003.tar
/GSOD/2004/gsod_2004.tar
/GSOD/2005/gsod_2005.tar
/GSOD/2006/gsod_2006.tar
/GSOD/2007/gsod_2007.tar
/GSOD/2008/gsod_2008.tar
/GSOD/2009/gsod_2009.tar
我们在接下来的MapReduce中将读取ncdc_files.txt作为入参,读入的格式是Nline,这里我们指定了10个tar文件,所以会产生10个mapper作业
借来新建一个load_ncdc_map.sh文件:
#!/bin/bash
read hdfs_file
echo "$hdfs_file"
# Retrieve file from HDFS to local disk
echo "reporter:status:Retrieving $hdfs_file" >&2
/hadoop/hadoop260/bin/hdfs dfs -get $hdfs_file .
# Create local directory
target=`basename $hdfs_file .tar`
mkdir $target
echo "reporter:status:Un-tarring $hdfs_file to $target" >&2
tar xf `basename $hdfs_file` -C $target
# Unzip each station file and concat into one file
echo "reporter:status:Un-gzipping $target" >&2
for file in $target/*
do
gunzip -c $file >> $target.all
echo "reporter:status:Processed $file" >&2
done
# Put gzipped version into HDFS
echo "reporter:status:Gzipping $target and putting in HDFS" >&2
gzip -c $target.all | /hadoop/hadoop260/bin/hdfs dfs -put - /GSOD_ALL/$target.gz
rm `basename $hdfs_file`
rm -r $target
rm $target.all
chmod +x load_ncdc_map.sh
ll load_ncdc_map.sh
-rwxrwxr-x 1 hadoopid hadoopid 792 Jan 26 11:21 load_ncdc_map.sh*
streaming的程序可以通过如下简单的方式检测下运气情况:
cat ncdc_files.txt |./load_ncdc_map.sh
reporter:status:Processed gsod_2000/996430-99999-2000.op.gz
reporter:status:Processed gsod_2000/996440-99999-2000.op.gz
reporter:status:Gzipping gsod_2000 and putting in HDFS
但是本例中的代码只会处理第一行记录,即2000年的
查看HDFS上目标文件是否生成:
hdfs dfs -ls /GSOD_ALL
Found 1 items
-rw-r--r-- 3 hadoopid supergroup 70931742 2015-01-26 11:27 /GSOD_ALL/gsod_2000.gz
接下来你需要修改load_ncdc_map.sh,使其可以在MapReduce的Streaming上正常运行,因为使用NLineInputFormat,所以只修改了read那一行:
#!/bin/bash
read offset hdfs_file
echo -e "$offset\t$hdfs_file"
hadoop jar /hadoop/hadoop260/share/hadoop/tools/lib/hadoop-streaming-2.6.0.jar \
-D mapreduce.job.reduces=0 \
-D mapreduce.map.speculative=false \
-D mapreduce.task.timeout=12000000 \
-inputformat org.apache.hadoop.mapred.lib.NLineInputFormat \
-input /ncdc_files.txt \
-output /output/1 \
-mapper load_ncdc_map.sh \
-file load_ncdc_map.sh

提示运行完毕后使用如下命令查看目标文件是否生成:
hdfs dfs -ls /GSOD_ALL

运行的最后一行告诉你log的位置:
15/01/26 16:29:21 INFO streaming.StreamJob: Output directory: /output/1
hdfs dfs -ls /output/1
Found 11 items
-rw-r--r-- 3 hadoopid supergroup 0 2015-01-26 16:29 /output/1/_SUCCESS
-rw-r--r-- 3 hadoopid supergroup 71 2015-01-26 16:26 /output/1/part-00000
-rw-r--r-- 3 hadoopid supergroup 71 2015-01-26 16:22 /output/1/part-00001
-rw-r--r-- 3 hadoopid supergroup 71 2015-01-26 16:27 /output/1/part-00002
-rw-r--r-- 3 hadoopid supergroup 72 2015-01-26 16:26 /output/1/part-00003
-rw-r--r-- 3 hadoopid supergroup 72 2015-01-26 16:23 /output/1/part-00004
-rw-r--r-- 3 hadoopid supergroup 72 2015-01-26 16:29 /output/1/part-00005
-rw-r--r-- 3 hadoopid supergroup 72 2015-01-26 16:27 /output/1/part-00006
-rw-r--r-- 3 hadoopid supergroup 72 2015-01-26 16:20 /output/1/part-00007
-rw-r--r-- 3 hadoopid supergroup 72 2015-01-26 16:28 /output/1/part-00008
-rw-r--r-- 3 hadoopid supergroup 70 2015-01-26 16:25 /output/1/part-00009
使用cat命令查看文件内容:
hdfs dfs -cat /output/1/part-00000hadoopid@namenode:~$ hdfs dfs -cat /output/1/part-00000
25 /GSOD/2001/gsod_2001.tar
hadoopid@namenode:~$ hdfs dfs -cat /output/1/part-00001
50 /GSOD/2002/gsod_2002.tar
hadoopid@namenode:~$ hdfs dfs -cat /output/1/part-00003
100 /GSOD/2004/gsod_2004.tar前面就是输入行的offset,每天记录占25字节“/GSOD/2000/gsod_2000.tar”
生成的文件用Notepad++打开就是如下的样子:

GSOD_DESC.txt有文件的描述
接下来书中的所有实验都可以继续展开了















 4293
4293











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











