









原创: 牛超 2017-03-19 Mail:10867910@qq.com
说起数据挖掘机器学习,印象中很早就听说过关于啤酒尿布的神话,这个问题经常出现在数据仓库相关的文章中,由此可见啤酒尿布问题对数据挖掘领域影响的深远程度。先看看它的成因:“啤酒与尿布”的故事产生于20世纪90年代的美国沃尔玛超市中,沃尔玛的超市管理人员分析销售数据时发现了一个令人难于理解的现象:在某些特定的情况下,“啤酒”与“尿布”两件看上去毫无关系的商品会经常出现在同一个购物篮中,这种独特的销售现象引起了管理人员的注意,经过后续调查发现,这种现象出现在年轻的父亲身上,买尿布的同时经常顺便带一瓶啤酒回家。
在对这个问题津津乐道的同时,可能并不是所有的人都会关注它的实现细节。啤酒尿布问题归属于关联分析,即从一组数据集中发现项之间的隐藏关系,是一种典型的无监督学习。关联规则的项集可以是同构的如啤酒->尿布,也可以是异构的如夏天->空调备货。
本篇文章Apriori算法主要是基于频繁集的关联分析,也是十大经典数据挖掘算法之一,本文中所出现的关联分析默认都是指基于频繁集的关联分析。
以下为个人收集整理的Apriori算法的相关描述以辅助记忆,如有误导之处,请指正。
项的集合称为项集。包含k个项的项集称为k项集。
项集I表示为{i1,i2,...ik-1,ik},i可以是啤酒、尿布、牛奶等等。
集合D表示训练集,训练集中对应多笔交易(可理解为购物小票),每笔交易对应都是I的子集(不同商品)。
候选项集,经过关联组合构造的项集。候选项集经过剪枝处理形成频繁项集。
频繁项集,即满足最小支持度条件的项集,同时它的所有子集必须是频繁的,理解为经常同时出现在同一购物篮中的一组商品。
支持度公式:support = P(A并B),由于训练集交易总次数相对固定,因此可简化为A并B的发生频次(分母相同可忽略)。
Apriori算法具有一个非常重要的性质,即先验性质,说的是频繁项集的所有子集也一定是频繁的。一般在算法的实现中利用了该性质的反语,即一个项集如果不是频繁项集,其超项集也一定不是频繁项集。利用该性质可以大大减少算法对数据的遍历次数。
两个K项集(频繁集)需要进行连接以生成超项集(候选集),连接条件是二者有K-1项相同或者K为初始频繁集。
极大频繁项集,满足最小支持度条件的最终的频繁项集。
关联规则表示为A->B,其中A、B均为I的子集,且A与B的交集为空,规则相关具有单向性,因此用->表示,可理解为一种因果关系。
根据计算出来的K项集最终推导的关联规则要满足置信度条件,理解为大于已设定的概率值。
置信度公式:confidence = P(A)|P(A并B) = support(A并B)/support(A)
根据上面的描述,我们可以发现,这个算法多次出现候选集、频繁集、子集的概念,如何构建与操作集合是Apriori算法的关键,而最擅长集合操作的语言正是SQL。也是基于本系列,Thinking in SQL,看看如何用SQL来再现经典的啤酒尿布销售神话。
与穷举法不同,根据频繁集的性质,Aprior算法采用逐层搜索的方法,包含以下5个步骤:
1.首先根据集合D初始化候选集(K-1),依据最小支持度条件得到K-1项频繁集。
2.K-1项频繁集自连接获取K项候选集。第一轮K-1项频繁集就是在步骤1构造的,而其他轮是由步骤3得到(频繁集由候选集剪枝得到)。
3.对于候选集进行剪枝。如何剪枝呢?如果候选集的支持度小于最小支持度,那么就会被剪掉;另外,候选集的子集有不是频繁集的,也会被剪掉(这步处理较为复杂)。
4.递归步骤2,3,算法的终止条件是:如果自连接得到的已经不再是频繁集,取最后一次得到的频繁集作为结果。
5.构建候选的关联规则,并利用最小置信度剪枝以形成最终的关联规则。
对这个算法有进一步认识之后,下面就需要着手实现了,简要的说明一下我的思路:
1. 构建并导入用于机器学习的训练集
2. 创建集合类型以便于SQL与PLSQL交互
3. 创建支持度计算函数,用于输出项集支持度
4. 创建构建极大频繁集的函数(递归生成频繁集,剪枝操作依赖步骤3的支持度函数)
5. 主体查询SQL,利用步骤4创建的函数,构建关联规则,根据最小置信度剪枝输出结果
具体实现步骤如下(个人环境ORACLE XE 11.2):
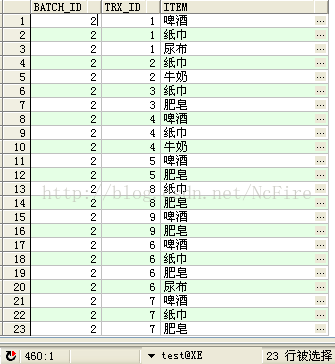
1.构建训练集D,创建表DM_APRIORI_LEARNING_T用于存放训练集
CREATE TABLE DM_APRIORI_LEARNING_T
(
BATCH_ID NUMBER ,--批次ID,区分训练集D
TRX_ID NUMBER ,--交易票据ID
ITEM VARCHAR2(100) --商品
) ;
2. 创建集合类型以便SQL与PLSQL交互。每个项集的项数可能不相同,归属于一个项集ID。
CREATE OR REPLACE TYPE DM_APRIORI_SET_OBJ IS OBJECT (
GID NUMBER ,--项集ID
ITEM VARCHAR2(100),--项
SUPPORT NUMBER --支持度
);
CREATE OR REPLACE TYPE DM_APRIORI_SET_TAB IS TABLE OF DM_APRIORI_SET_OBJ;3. 创建函数用于项集支持度计算,返回项集支持度的集合,依赖APRIORI训练集表,其中P_BATCH_ID用于界定训练集,P_TAB用于传入候选项集,重点关注如何判断项集能被训练集全匹配以及匹配次数的SQL实现,需要面向集合来思考,即Thinking in SQL。
CREATE OR REPLACE FUNCTION FUN_DM_APRIORI_SUPPORT(P_BATCH_ID NUMBER,
P_TAB DM_APRIORI_SET_TAB,
P_DEBUG NUMBER DEFAULT 0)
RETURN DM_APRIORI_SET_TAB IS
RTAB DM_APRIORI_SET_TAB; --结果频繁集
BEGIN
WITH TA AS
(SELECT A.GID, A.ITEM, COUNT(1) OVER(PARTITION BY A.GID) KCNT --每组项的个数
FROM TABLE(P_TAB) A --候选集
),
TB2 AS
( --匹配事实,以便计算支持度
SELECT A.GID,
A.ITEM,
A.KCNT,
T.TRX_ID GID2,
COUNT(1) OVER(PARTITION BY A.GID, T.TRX_ID) MATCH_CNT --每组匹配交易次数
FROM TA A
JOIN DM_APRIORI_LEARNING_T T
ON A.ITEM = T.ITEM
AND T.BATCH_ID = P_BATCH_ID) --计算项集GID在训练集中同时出现的频次SUPPORT
SELECT DM_APRIORI_SET_OBJ(GID, NULL, COUNT(1) / KCNT) --计算支持度
BULK COLLECT
INTO RTAB
FROM TB2
WHERE MATCH_CNT = KCNT --项数与交易匹配次数相同才算全匹配
GROUP BY GID, KCNT;
RETURN RTAB;
END;
4. 创建递归函数用于构造K项频繁集的超集,根据指定参数递归地构造极大频繁项集,而且这里可以指定P_MAXLVL最大K值以限制递归层次(默认无限制),重点关注频繁集连接构建候选超集的SQL实现,这是该算法的核心部分,Thinking in SQL,屏蔽ROW BY ROW循环处理的思路,注意如果没有面向集合的思维可能会迷失。
CREATE OR REPLACE FUNCTION FUN_DM_APRIORI_FREQ_SET --Apriori关联规则剪枝
(P_BATCH_ID NUMBER, --批次
P_TAB DM_APRIORI_SET_TAB, --前一轮传递的频繁集
P_CURK NUMBER, --构造频繁集前的K原值
P_SUPPORT NUMBER, --最小支持度
P_MAXLVL NUMBER DEFAULT NULL --最大递归层次,最大K值
) RETURN DM_APRIORI_SET_TAB IS
ATAB DM_APRIORI_SET_TAB; --前一轮传递的频繁K-1项集
RTAB DM_APRIORI_SET_TAB; --构造生成的频繁K项集
BEGIN
--初始化ATAB
IF P_CURK = 1 THEN
SELECT DM_APRIORI_SET_OBJ(ROWNUM, ITEM, SUPPORT)
BULK COLLECT INTO ATAB
FROM (SELECT ITEM, COUNT(1) SUPPORT
FROM DM_APRIORI_LEARNING_T
WHERE BATCH_ID = P_BATCH_ID
GROUP BY ITEM
HAVING COUNT(1) >= P_SUPPORT);
IF P_MAXLVL = 1 THEN
RETURN ATAB;
END IF;
ELSE
ATAB := P_TAB;
END IF;
WITH TA AS
(SELECT * FROM TABLE(ATAB)),
TB0 AS
( --K=1时构造K+1项集
SELECT RANK() OVER(ORDER BY A.GID, B.GID) GID, A.ITEM ITEM1, B.ITEM ITEM2
FROM TA A
JOIN TA B
ON A.ITEM < B.ITEM
AND P_CURK = 1 --注意这个条件开关
),
TB AS
( --K>1时构造K+1项集
SELECT RANK() OVER(ORDER BY GID1, GID2) GID, GID1, GID2, ITEM
FROM (SELECT A.GID GID1,
B.GID GID2,
A.ITEM,
COUNT(1) OVER(PARTITION BY A.GID, B.GID) MATCH_CNT
FROM TA A
JOIN TA B
ON A.ITEM = B.ITEM
AND A.GID < B.GID)
WHERE P_CURK > 1
AND MATCH_CNT = P_CURK - 1 --项集连接条件:K-1项相同
),
TC AS
( --候选集构造
SELECT DISTINCT C.GID, A.ITEM --非第一轮的候选集构造
FROM TB C
JOIN TA A
ON (C.GID1 = A.GID OR C.GID2 = A.GID)
AND A.ITEM NOT IN (SELECT K.ITEM FROM TB K WHERE K.GID = C.GID)
UNION ALL
SELECT GID, ITEM
FROM TB
UNION ALL --K=1分段
SELECT GID, ITEM --初始候选集
FROM TB0 UNPIVOT(ITEM FOR COL IN(ITEM1, ITEM2))),
TE AS
(SELECT GID,
ITEM,
LISTAGG(ITEM) WITHIN GROUP(ORDER BY ITEM) OVER(PARTITION BY GID) VLIST --项集LIST,便于计算
FROM TC),
TF AS
( --K+1项集
SELECT ROWNUM RNUM, GID, ITEM
FROM TE A
WHERE GID = (SELECT MIN(GID) FROM TE B WHERE A.VLIST = B.VLIST)),
--以下为计算所有K集子集是否全部频繁
TG AS
( --K+1=>K集子集 C(K+1,K)= C(K+1,1)
SELECT A.RNUM, A.GID, B.ITEM
FROM TF A
JOIN TF B
ON A.GID = B.GID
AND A.ITEM != B.ITEM),
TH AS
(SELECT G.RNUM, G.GID, COUNT(1) OVER(PARTITION BY G.GID) CNT2 --每个群中匹配K次的项数
FROM TG G
JOIN TA A --TA为已知的频繁项集
ON G.ITEM = A.ITEM
GROUP BY G.RNUM, G.GID, A.GID
HAVING COUNT(1) = P_CURK --K集元素需各自匹配K次
),
TI AS
(SELECT * FROM TH WHERE CNT2 = P_CURK + 1 --留下频繁项集
),
TKC AS
( --候选项集(所有子集频繁)
SELECT TF.GID, TF.ITEM
FROM TF
JOIN TI
ON TF.RNUM = TI.RNUM
AND TF.GID = TI.GID),
TKCA AS
( --构造候选子集参数
SELECT CAST(MULTISET (SELECT GID, ITEM, NULL FROM TKC) AS
DM_APRIORI_SET_TAB) STAB
FROM DUAL),
TK2 AS
( --剪枝 过滤支持度
SELECT TKC.*, TS2.SUPPORT
FROM TKCA
CROSS JOIN TABLE(FUN_DM_APRIORI_SUPPORT(P_BATCH_ID, TKCA.STAB)) TS2 --候选子集支持度
JOIN TKC
ON TKC.GID = TS2.GID
AND TS2.SUPPORT >= P_SUPPORT)
SELECT DM_APRIORI_SET_OBJ(GID, ITEM, SUPPORT) BULK COLLECT
INTO RTAB
FROM TK2;
IF P_MAXLVL = P_CURK + 1 THEN
RETURN RTAB; --满足最大项
ELSIF RTAB.COUNT = 0 THEN
RETURN ATAB; --项集为空,取前次项集
ELSE
--递归取项集
RETURN FUN_DM_APRIORI_FREQ_SET(P_BATCH_ID,
RTAB,
P_CURK + 1,
P_SUPPORT,
P_MAXLVL);
END IF;
END;
函数创建好了之后,可以做几个简单的查询以帮助理解:
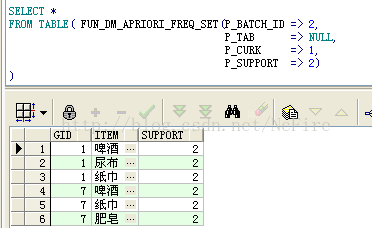
a.查询极大频繁项集的计算结果,可以看到结果一共2个3项集
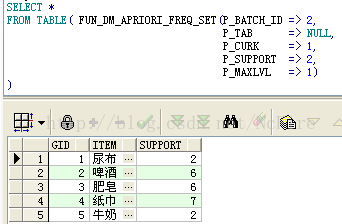
b.查询初始项集,指定最大搜索层次为1,结果是6个1项集
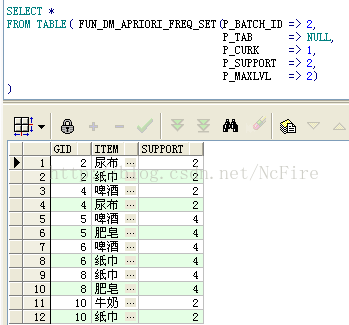
c.查询频繁2项集,指定最大搜索层次为2,结果是6个2项集
d.查询频繁2项集对应的支持度,注意CAST与MULTISET的用法,不解释了
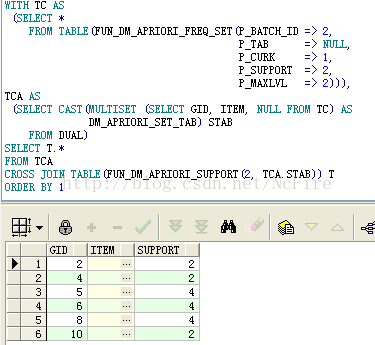
5. 主体查询SQL,利用步骤3、4创建的函数,构建关联规则,根据最小置信度剪枝输出结果,为了保持通用性,使用参数集PARAMS(支持度2,置信度60%)来驱动全盘,Thinking in SQL,一气呵成,如下:
WITH PARAMS AS
(SELECT 2 BATCH_ID, 2 SUPPORT, 0.6 CONF FROM DUAL),
TA AS
( --频繁集
SELECT GID, ITEM, SUPPORT, COUNT(1) OVER(PARTITION BY GID) KCNT --集的项数
FROM PARAMS P
CROSS JOIN TABLE(FUN_DM_APRIORI_FREQ_SET(P.BATCH_ID, NULL, 1, P.SUPPORT))),
TB AS
( --k集的子集准备
SELECT ROWNUM GID,
TA.GID OGID,
TA.ITEM,
TA.KCNT,
TA.SUPPORT KSUPPORT,
LEVEL LVL,
'{' || LTRIM(SYS_CONNECT_BY_PATH(ITEM, ','), ',') || '}' ITEM_LIST --项集描述,用于规则输出
FROM TA
CONNECT BY LEVEL <= KCNT - 1
AND PRIOR ITEM < ITEM
AND PRIOR GID = GID),
TC AS
( --k集的子集
SELECT A.GID, A.OGID, A.ITEM_LIST, A.KCNT, A.LVL, B.ITEM
FROM TB A
JOIN TB B
ON A.OGID = B.OGID
AND B.LVL <= A.LVL
AND B.GID = (SELECT MAX(C.GID)
FROM TB C
WHERE C.OGID = B.OGID
AND C.LVL = B.LVL
AND C.GID <= A.GID)),
TCA AS --组装集合参数
(SELECT BATCH_ID,
SUPPORT,
CONF,
CAST(MULTISET (SELECT GID, ITEM, NULL FROM TC) AS
DM_APRIORI_SET_TAB) STAB
FROM PARAMS),
TD AS
( --子集支持度计算
SELECT A.GID,
B.OGID,
B.KCNT,
B.KSUPPORT,
B.LVL,
B.ITEM_LIST,
A.SUPPORT,
TCA.CONF
FROM TCA
CROSS JOIN TABLE(FUN_DM_APRIORI_SUPPORT(TCA.BATCH_ID, TCA.STAB)) A
JOIN TB B
ON A.GID = B.GID),
TE AS
(SELECT A.GID AGID,
A.OGID,
A.ITEM_LIST AITEM_LIST,
A.KSUPPORT,
A.SUPPORT,
B.GID BGID,
B.ITEM_LIST BITEM_LIST,
A.CONF,
A.KSUPPORT / A.SUPPORT REAL_CONF --置信度结果
FROM TD A
JOIN TD B
ON A.OGID = B.OGID
AND A.LVL + B.LVL = A.KCNT --a并b 属于极大频繁集的元素
AND NOT EXISTS ( --a交b为空
SELECT ITEM
FROM TC
WHERE GID = A.GID
INTERSECT
SELECT ITEM FROM TC WHERE GID = B.GID))
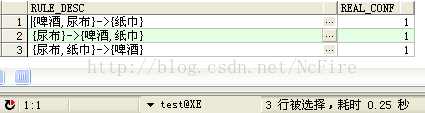
SELECT AITEM_LIST || '->' || BITEM_LIST RULE_DESC, REAL_CONF
FROM TE
WHERE REAL_CONF >= CONF --剪枝 过滤置信度
啤酒尿布这类经典算法能够让我们拓展思维,并非局限于纵向拓展(术业专攻,自认能力有限),否则会陷入“太学术”的误区死角。跳出深究算法本身,也不要只关注购物篮分析,通过头脑风暴地横向思维扩展可以发现很多应用场景。例如身为开发DBA在工作过程中经常会分析一类问题:哪些表会经常同时被关联查询;哪些列会同时出现在谓词中;如何创建组合索引、冗余加速列、冗余加速表会对系统整体性能有战略提升效果。可以通过定期挖掘分析生产库的SQL形成训练集,通过操控频繁集找到表间关联项集,谓词列关联项集与关联规则,也可以结合欧拉定理给出支持度权重。从而为高效的数据库设计运营提供有效的决策依据。当然现实中的开发工作无法让人思考太多战略技术层要素,对性能的要求也只不过是追求一时的快感。因此虽然工作N年很多设想只能局部落地。敏捷+结果为导向难免会让人怀揣游击战的心理,相信很多人会有同感。
回到主题,SQL语言处理数据有天生的优势,Thinking in SQL,面向集合思考问题,通过关系运算(并、交、乘、除)处理数据,ORACLE高效的SQL引擎会负责循环处理。结合ORACLE高级开发技巧,通过不断地总结归纳,注入灵魂算法,ORACLE数据库也能定制机器学习能力。















 3946
3946

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









