







前几节主要讲了4种应用比较广泛的监督机器学习算法:线性回归,逻辑回归,神经网络,SVM。并对如何评价机器学习算法做了简要概述,其中主要包括欠拟合,过度拟合,学习曲线,正则化,precision and recall等等,接下来主要讲几种比较常用的非监督机器学习算法,例如K-means等。以及数据处理方法:PCA。
1. Clustering
1.1 Unsupervised Learning: Introduction
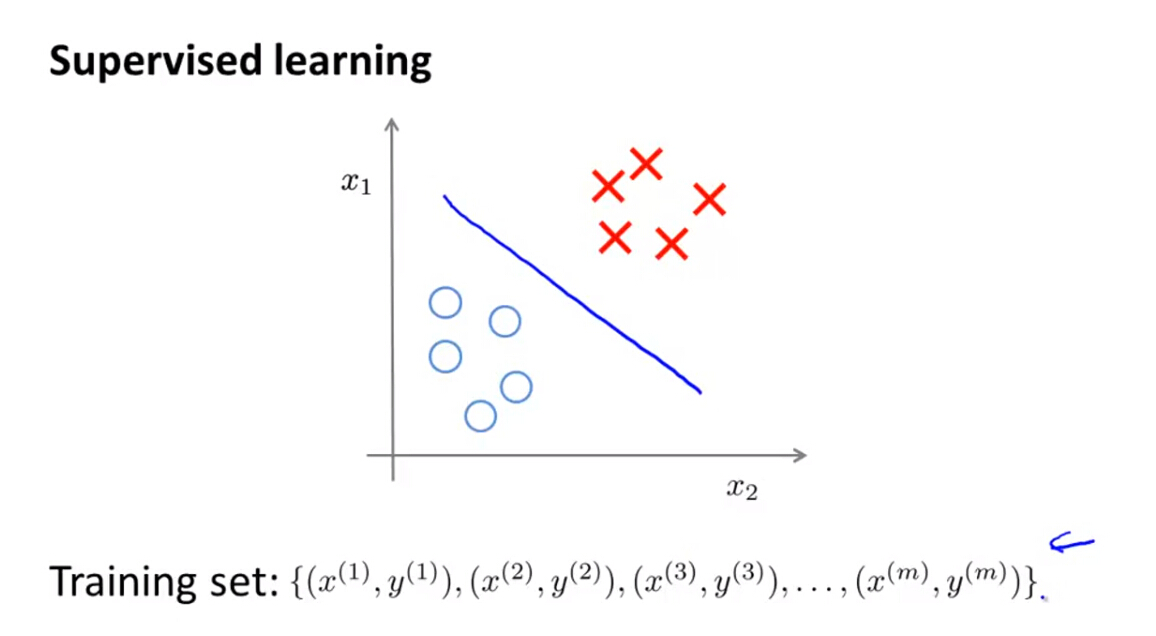
非监督分类即为训练数据中没有标记数据,我们要做的就是通过合适的算法(聚类)找到数据中存在的一种结构。然后对数据进行成功分类。

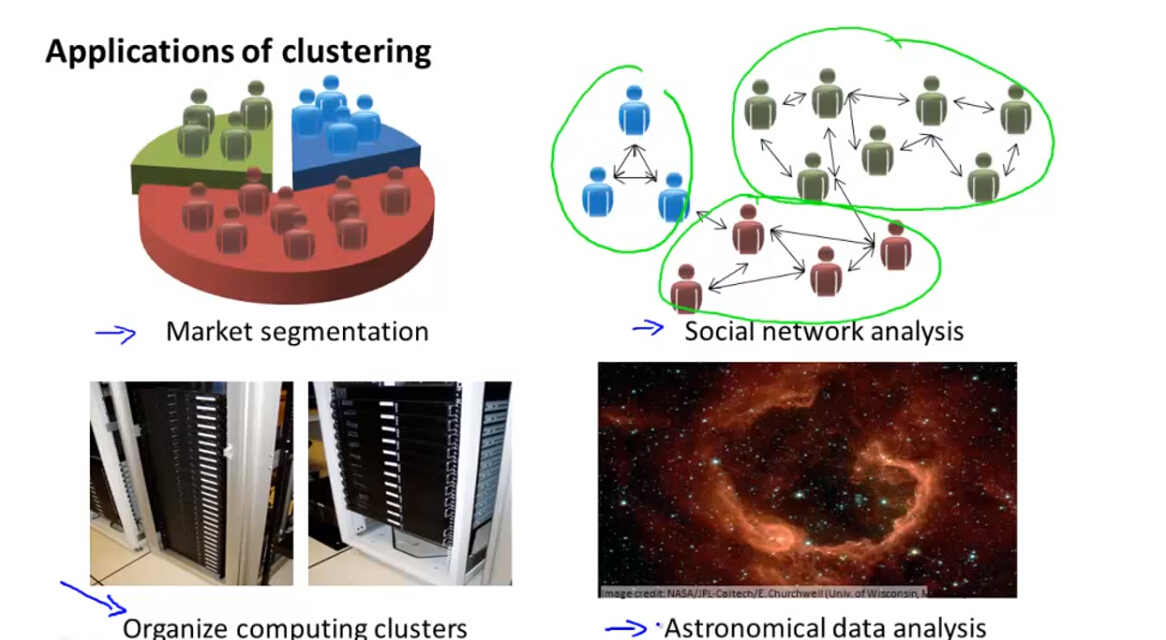
非监督分类也有很多应用。
1.2 K-Means Algorithm
K-Means算法的主要流程是:
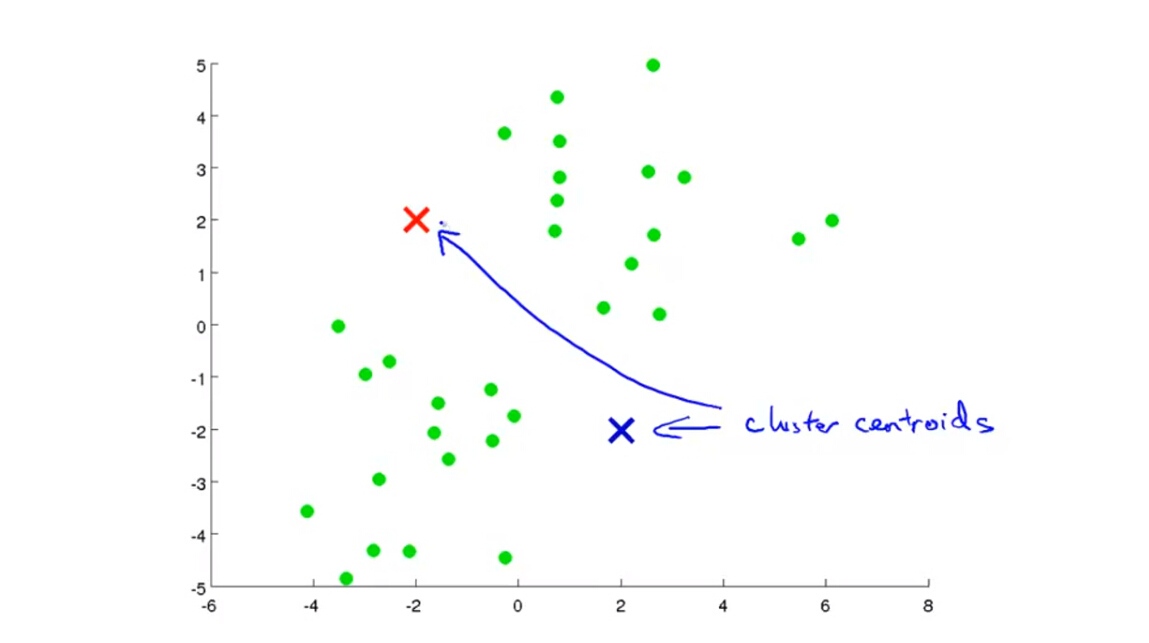
(1)假设我们要从数据中分出两类,首先随机选择两个(
K=2
)聚类中心Centroids
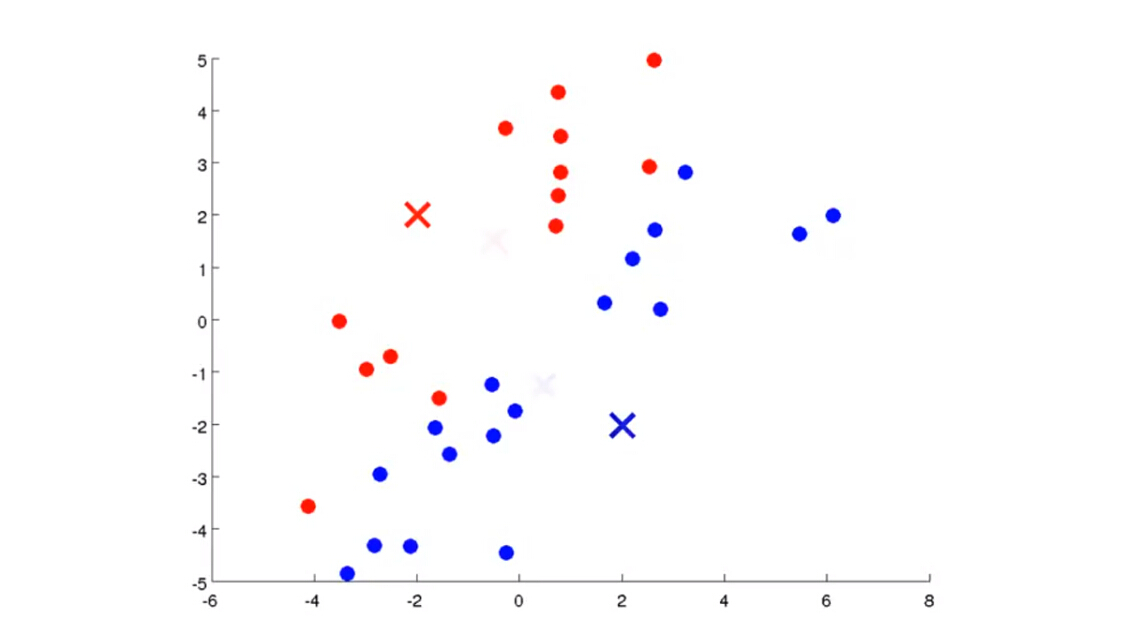
(2)计算每一个样本点与各聚类中心的距离,根据距离的大小将样本点分配给距离最小的聚类中心类别 c(i) 。
(3)对分配给某一聚类中心的所有样点求取平均值,移动聚类中心到新的聚类中心,然互再进行第二步,将所有样本点重新计算
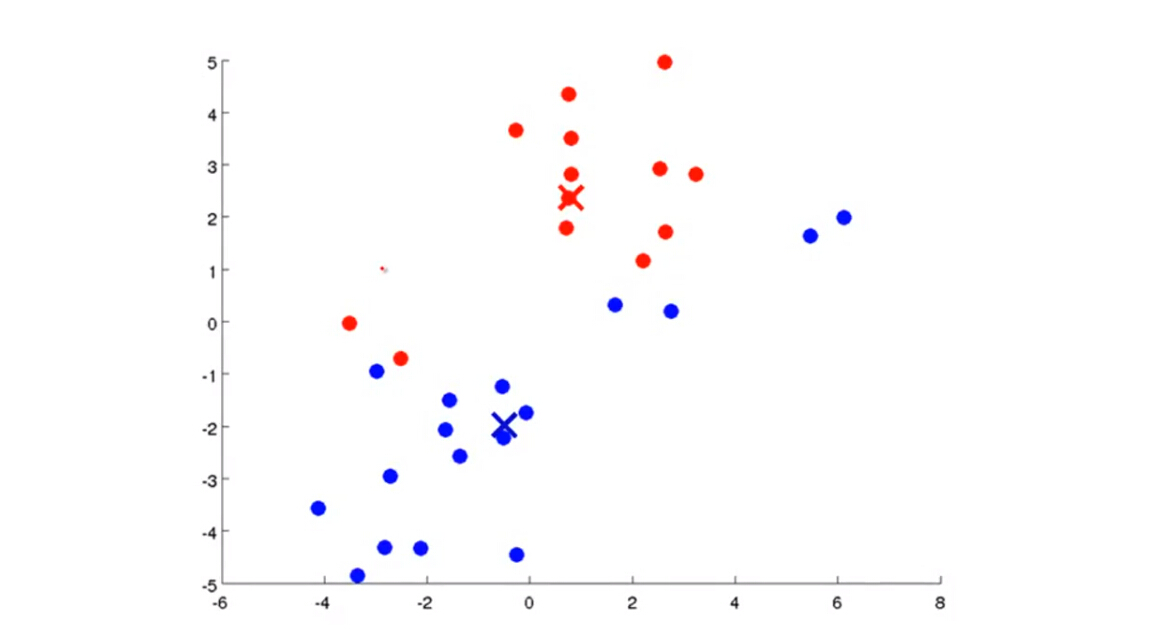
(4)依次循环第二步和第三步,直至算法收敛(迭代结束)
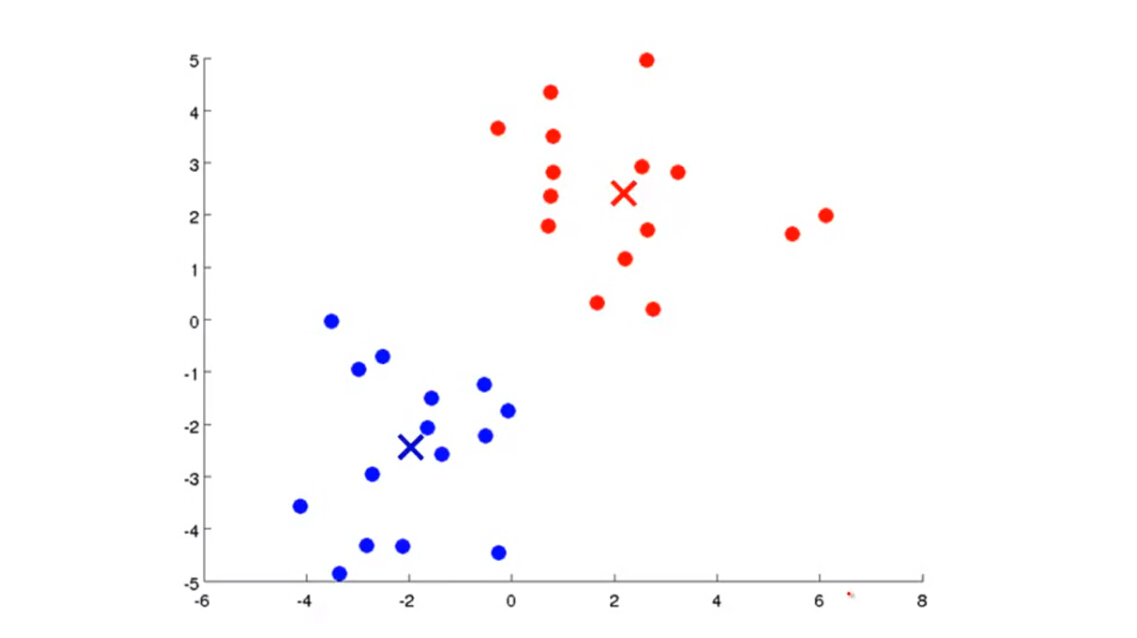
K-Means算法的要点:
- 输入K个聚类中心
- 输入所有样本点
- 样本点为n维,即没有了偏差项X0
- 需要注意的是,如果一个聚类中心在迭代过程中没有分配任何样点,则一般是删除这个聚类中心,或者是重新随机选择一个聚类中心。


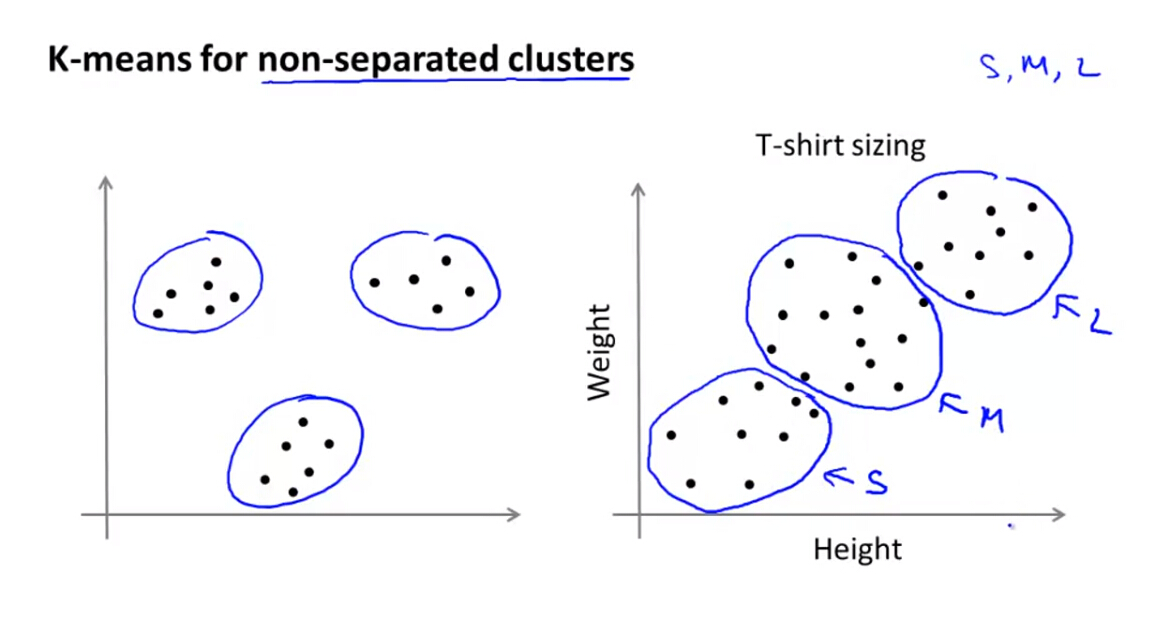
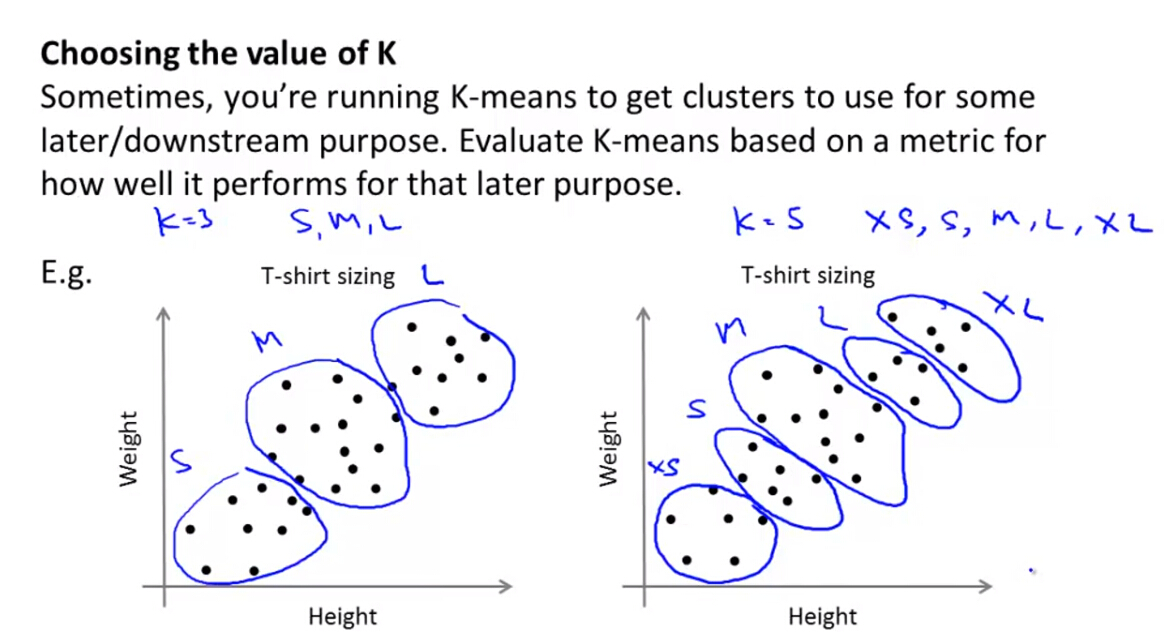
对于明显不存在簇类的数据集,K-Means也能找到合适的聚类中心进行分类,如T-shirt的型号的选择实例。
1.3 Optimization Objective
K-Means算法的代价函数又叫做失真函数(Distortion Function),目标是找到每一个样本点与对应聚类中心的最小值。


1.4 Random Initialization
(1)K-Means算法中最重要的一步就是随机选择初始聚类中心,一般的方法是从样本中随机选择样本点作为聚类中心。
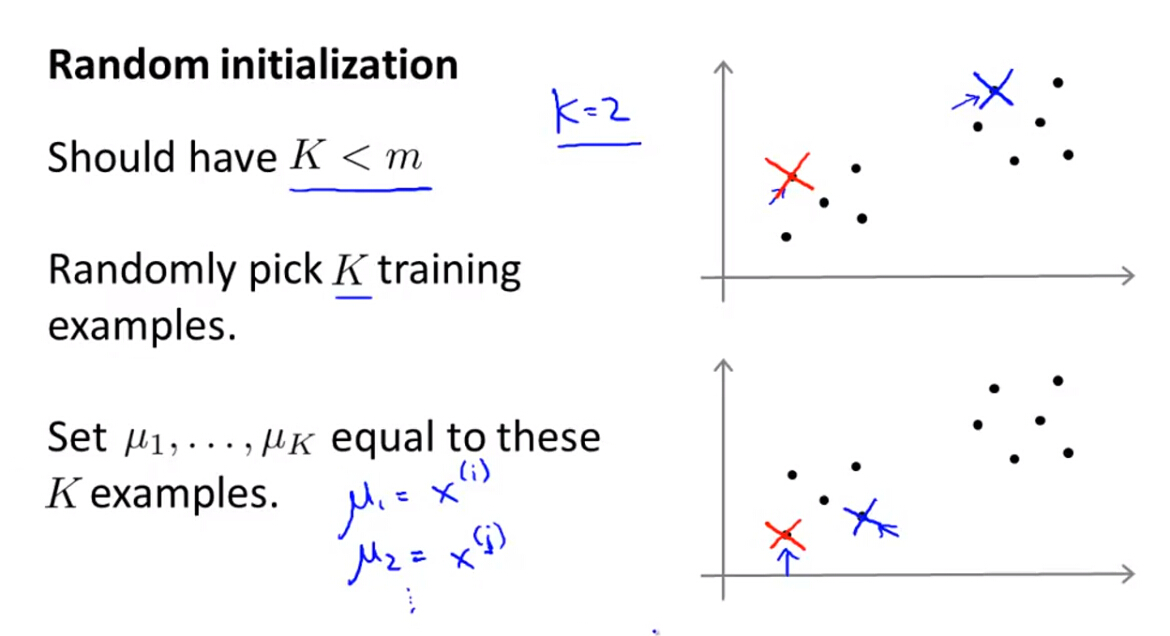
(2)由于初始化聚类中心的不同,这就可能导致K-Means算法会产生局部最优解。

(3)为了避免因为初始化导致的局部最优问题,我们可以选择
- 随机选择样本点
- 多次初始化聚类中心,然后计算K-Means的代价函数,根据失真代价函数的大小选择最优解。

1.5 Choosing the Number of Clusters
除了初始化聚类中心,另外一个重要的参数时如何选择K的大小:
(1)肘部原则
通过失真代价函数关于K大小的函数曲线,代价函数会醉着K的增大逐渐减小,直至趋于稳定,由此我们可以判断,当拐角的时候是最适合的K大小,但是实际情况中,往往我们无法得到一个明显的拐点用于判断。
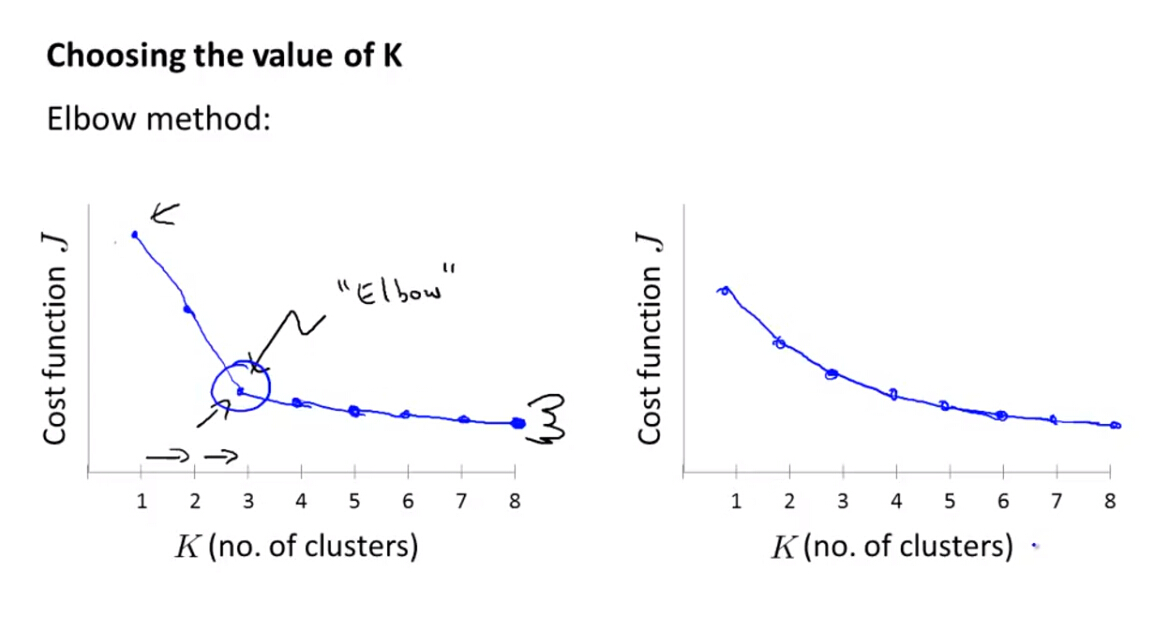
(2)根据应用目的进行选择
根据K-Means算法的应用目的,选择合适的K的大小,即类别的个数。















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









