






记一次使用开源代码的微博爬虫的经历
开源可以让我们的生活更佳美好。之前一直打算把写一个的新浪微博爬虫,然后将数据存入数据库,从而以支持我后续的科研数据分析。
最初,我去看看了微博官方提供的开发者API,结果这个API受限太大,比如我用我的账号,生成的accesstoken只能爬取我自己微博的数据,这就让我直接放弃了这个途径。紧接着,我花了2天的时间把微博的API搞清楚,好了,万事具备,开始coding,我预估要花一个星期的时间才可以把代码的大致样子写出来。但是接下来发生的事情,让我在一天之内完成了从新浪微博的数据爬虫到最终展现,让我不得不感叹开源的力量!
之所以写这篇文章,并不打算把分享一些自己专研的技术,而是“搬运” 别人的经验,总结一下。我的爬虫代码是https://github.com/LiuXingMing/SinaSpider ,这个开源代码。感谢!
scrapy
这个代码是基于scrapy实现的,因此(1)要正确安装;scrapy依赖关系非常多,安装要最好基于anconda。(2)scrapy的教程。花了半天的时间把scrapy官方网址的教程(https://scrapy.org/doc/)看了前面两章,基本上了解了scrapy的基本流程和一些特点。客观来说,scrapy这个框架还是不错的,考虑了很多的爬虫的因素。抽象了很多。之前都是自己去写爬虫框架,确实非常麻烦。这里就不诉苦了。
mongodb和pymongo
由于爬下来的数据都是整齐的结构化数据,因此要将其存入Nosql数据库里,当然mongodb是一个优秀的Nosql软件。mongodb本身的知识,也非常容易入手。可以参考菜鸟教程(http://www.runoob.com/mongodb/mongodb-tutorial.html)和我之前写的一个博客(http://blog.csdn.net/richard_more/article/details/51278136),这篇文章是对mongodb中常用的命令,并且和mysql的设计概念做对比,如果你熟悉了mysql,看这篇文章最为适合。
接下来,pymongo,就是连接python和mongo的第三方package了。基本语法(http://api.mongodb.com/python/current/tutorial.html)
说到这里,看看实验界面吧,我开了4个shell,第一个shell是mongod,是mongodb的服务开启界面;第二个shell是mongo界面是,mongo数据库的命令行界面;第三个shell是ipython界面,是我为了测试了pymongo是否可以正常连接数据库的测试界面;第四个界面是scrapy爬虫界面。
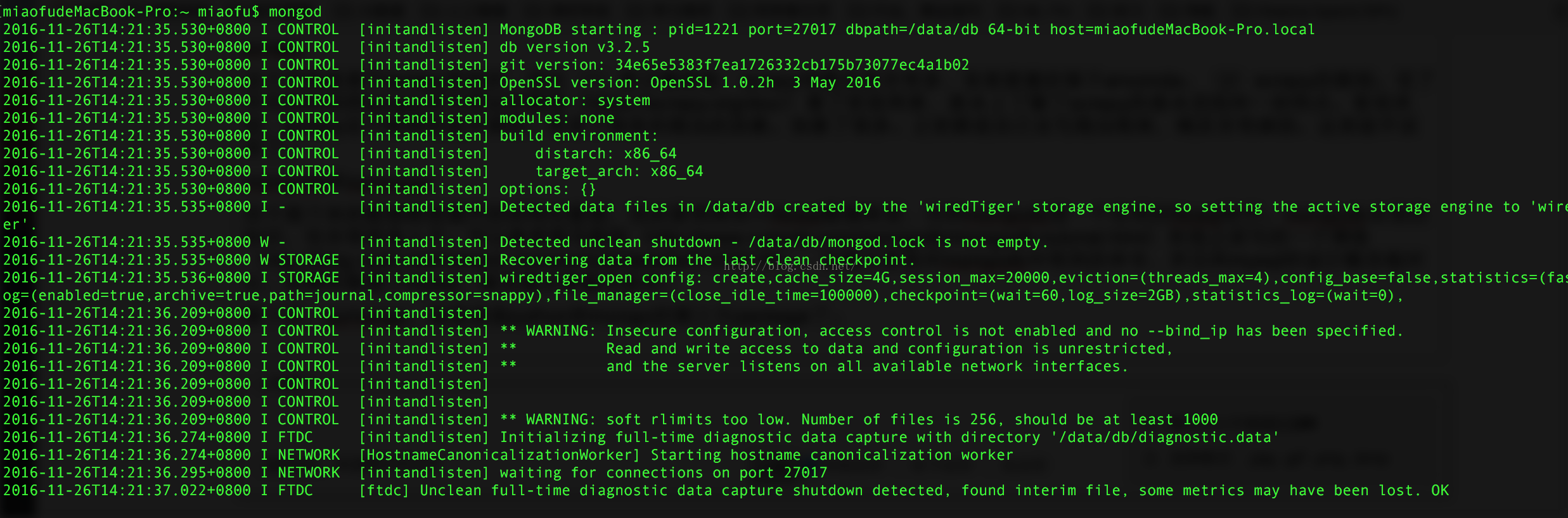
第一 mongodb的服务开启界面
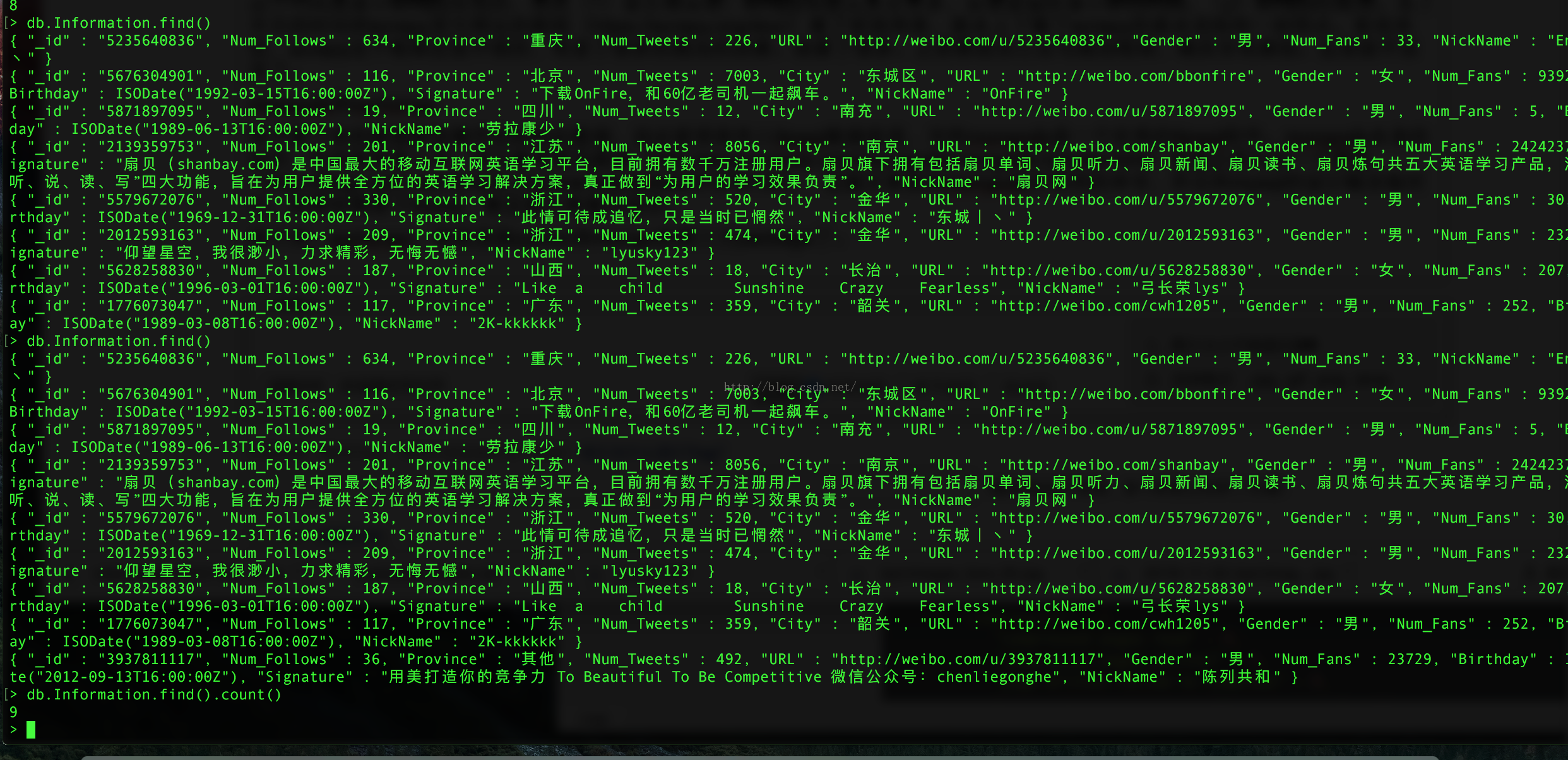
第二个界面mongo数据库的命令行界面
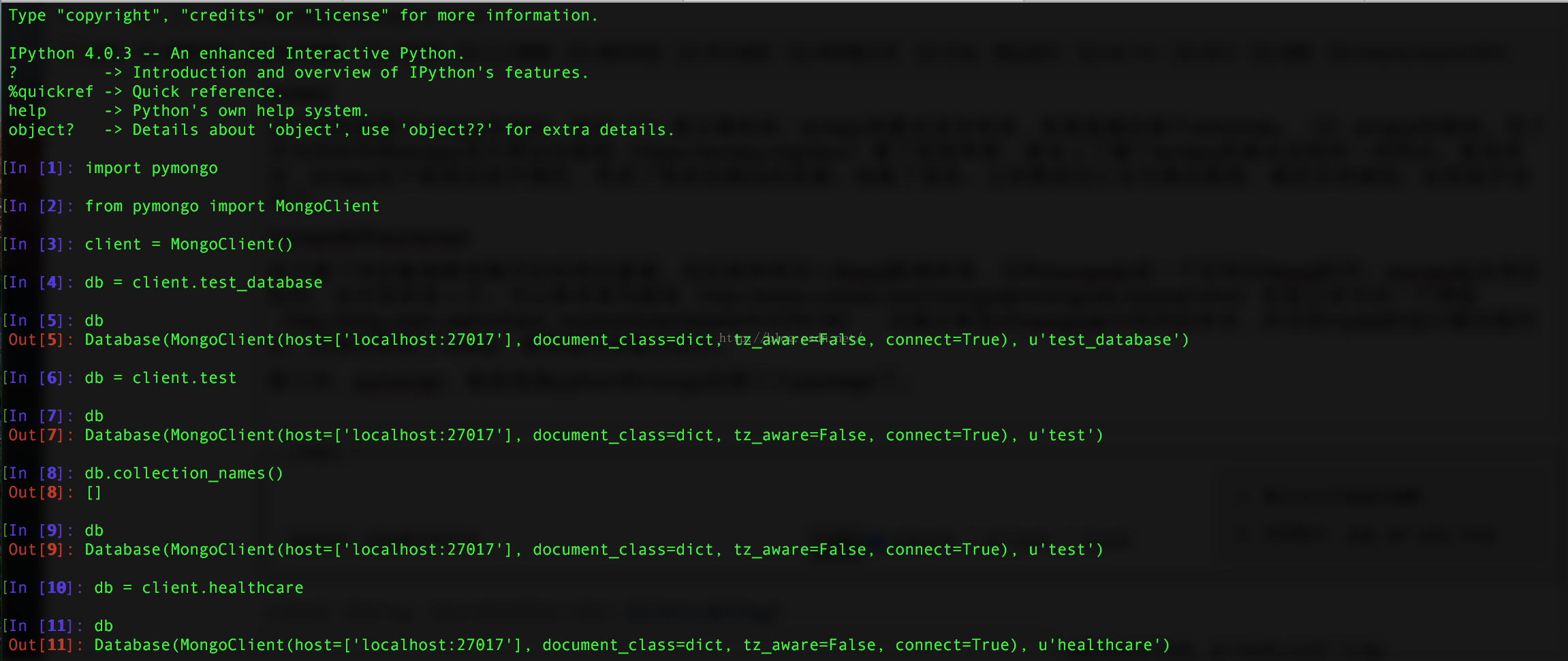
第三个界面 测试了pymongo
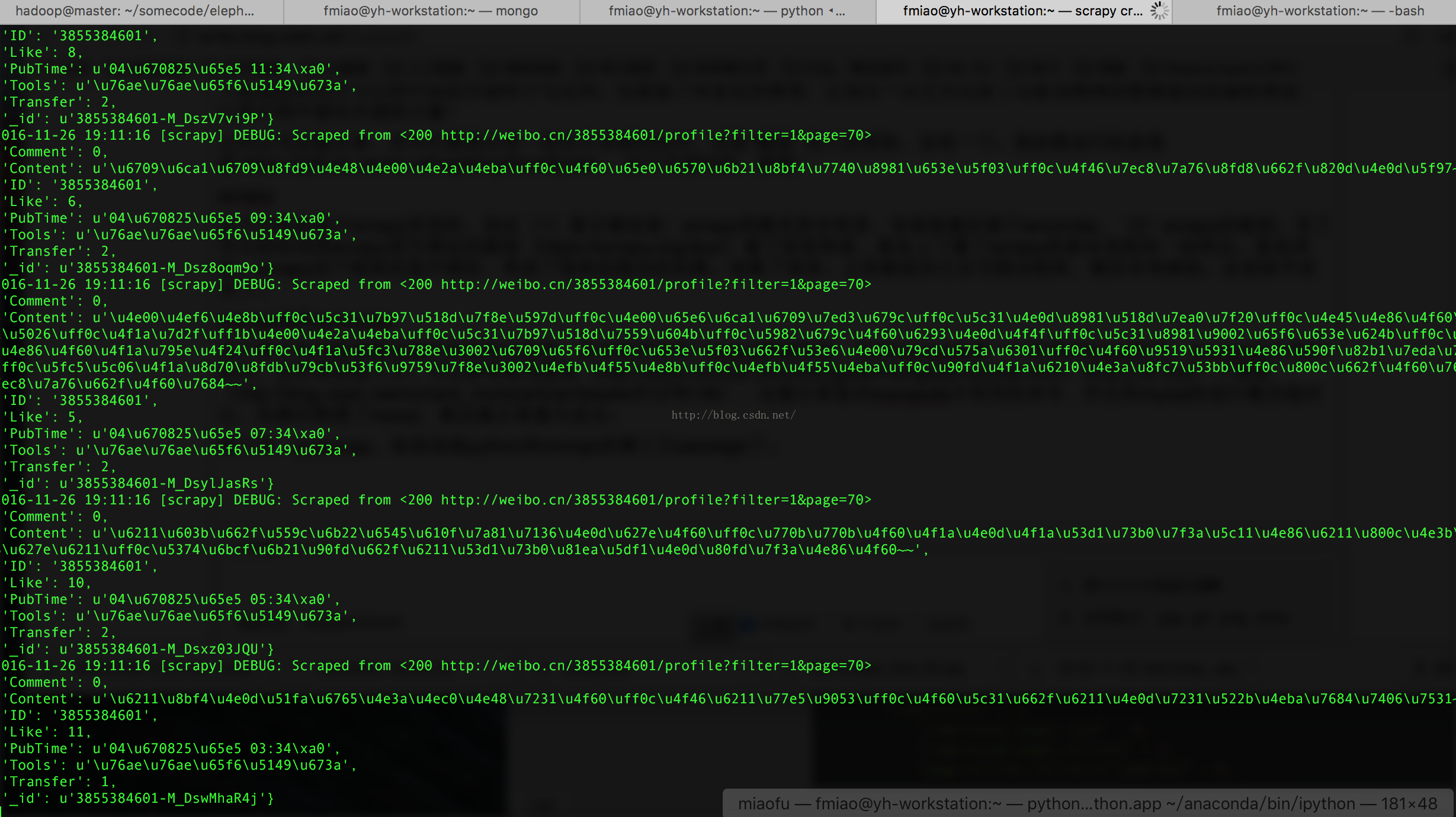
第四个界面 scrapy爬虫界面
mongo可视化界面 Robomongo
为了可以及时监测自己的数据库的现状,老是在命令行中,查询数据库实在是太麻烦了。于是必须有 一个可视化的界面进行管理。之前我试用了rockmongo,但是这个是基于web的,因此需要安装apache,php,还要开启服务器,以及配置php和mongo的接口,非常的麻烦。于是综合网友的建议,选择了Robomongo。(https://robomongo.org/)
据说,这是一个谁用谁知道的良心软件。
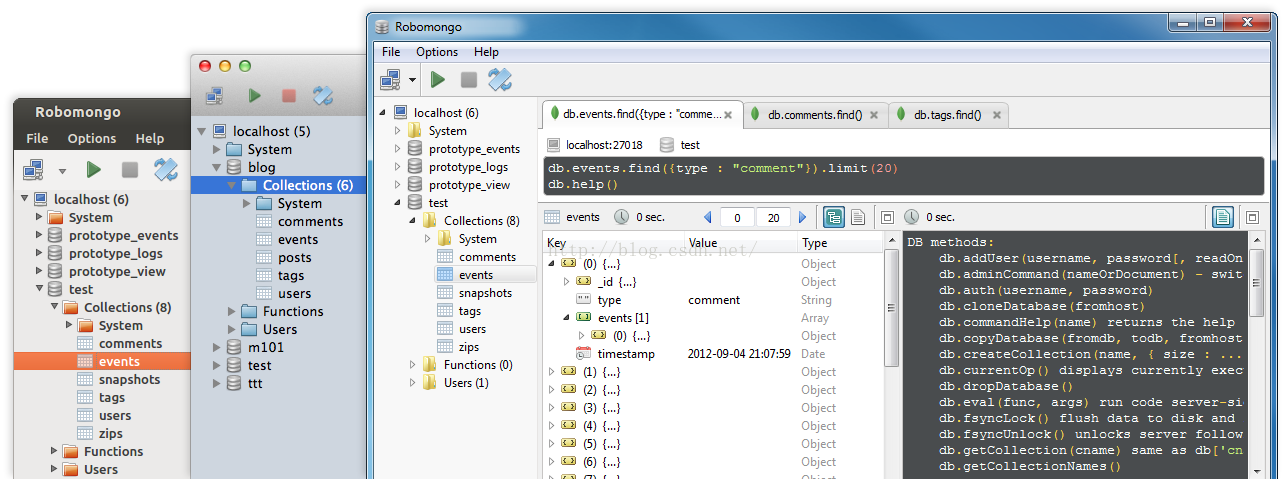
看到这么好的界面,我还有什么理由不用呢?
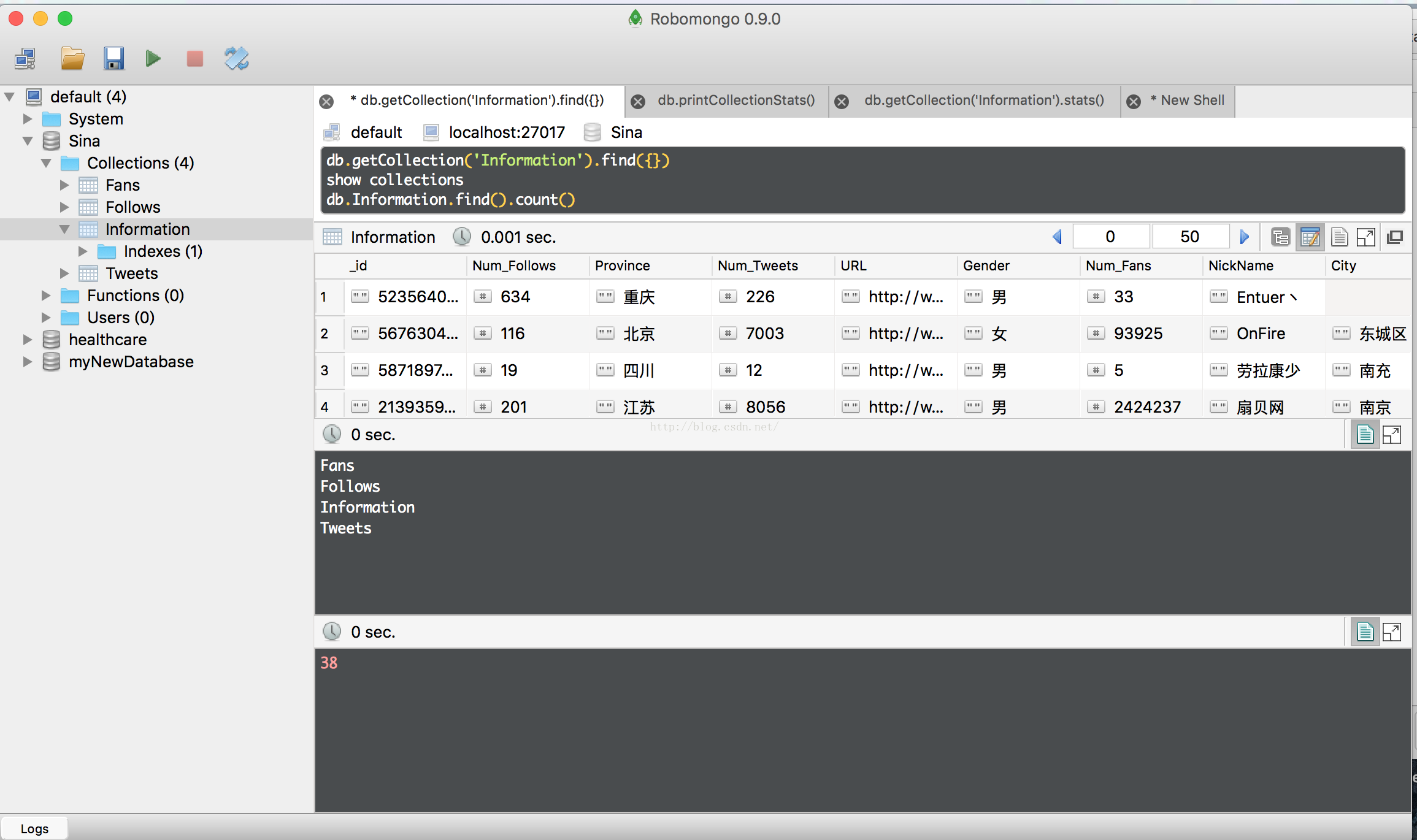
结束
最后,我就一边scrpay跑着,一边robomongo界面查询着,看着数据从微博,到数据库的数据流动。感受着开源精神的伟大!














 2032
2032











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









