







目录
336 条记录,直接上结果
前言
基于最近的一些微博爬虫工作,对目前微博爬虫内容需要考虑的问题进行描述。当前基于爬虫的思路主要有以下两种:
思路一:从页面上把数据下载下来,再用正则表达式一条一条匹配
思路二:微博平台提供了一种更便捷的思路,通过调用API,返回需要的数据。
本文选取思路二,基于微博API展开工作内容。
说明:工作是基于微博移动客户端(通常都是选择这个)https://m.weibo.cn/
一、🌍爬虫是什么?🌍
爬虫(Spider)是指一类网络程序,其目的是自动地浏览互联网,并收集特定的信息。通常情况下,爬虫被用于从网页中提取数据,如文本内容、链接、图片等,并将这些数据保存下来供后续分析或展示使用。
二、🌍微博爬虫的难点🌍
难点:
1)受到请求频率的限制,需要采用一些方法来避免限制,例如:time.sleep等
2)通常来说,需要设置cookie,通过设置url,模拟网页发送请求,获得网页内容。缺点:需要对数据进行预处理,并且需要找到网页url的逻辑,cookie。
3)经过测试,当前微博的评论,不能全部提取。本文通过实验得到结果,微博评论通常只能抓到200条数据后,就会被限制。
基于上述问题,为了爬取到微博的评论,本文爬取的思路采取通过微博API进行调用相关接口,具体实现步骤如下:
三、🌍微博API爬取步骤🌍
1.🌕基础信息配置 🌕
1.1注册微博开放平台
登录微博开放平台,如下链接。注册一个账号。
1.2.创建一个应用
在顶部【微连接】中,创建一个微链接。

1.3获取token
查看创建应用的App Key,App Secret
【我的应用】->【应用信息.基本信息】
配置【高级信息】,两项都设置为
https://api.weibo.com/oauth2/default.html

经过上面的配置后,我们将获得的App Key,App Secret发送给客户端,返回给用户特定的token值,拿到这个token之后,我们才能调用API拿到数据。
导入包,可以去github上下载sinaweibopy3:https://github.com/olwolf/sinaweibopy3
import webbrowser
from sinaweibopy3.sinaweibopy3 import APIClient
其中XXXXX替换为创建应用的App Key,App Secret;
APP_KEY = 'XXXXX'
APP_SECRET = 'XXXXX'
CALLBACK_URL = 'https://api.weibo.com/oauth2/default.html'#回调授权页面
client = APIClient(app_key=APP_KEY, app_secret=APP_SECRET, redirect_uri=CALLBACK_URL)
url = client.get_authorize_url()
webbrowser.open_new(url)
code = input('输入 code:')
r = client.request_access_token(code)
print(r)这时会自动打开浏览器,需要登录你创建应用的微博账号进行扫码登录,登录后,会返回一串code码,注意看浏览器中的网址。将网址中code后面的部分复制下来,返回到python的输出窗口进行粘贴。
https://api.weibo.com/oauth2/default.html?code=edd808049ac941c8dccd76a071b95a88

这时,程序返回数据,我们将access_token这部分数据保存下来
'access_token': '2.00XXXXXXXXXXXXXXXXXXXXXX' #这里要自己进行替换具体得到的token

2.🌕调用API接口获取数据 🌕
参数说明:
access_token是在第二部分你获得的;
suffix是你调用的API,具体还有哪些API接口,可以参考官方的接口文档:
https://open.weibo.com/wiki/微博api
params中的参数,id是每条微博对应的号码,举个例子,打开一条微博
注意观察浏览器的网址变化,不难发现detail/后面的数字就是这条微博对应的ID
https://m.weibo.cn/detail/496044833636XXXX
from weibopy import WeiboOauth2, WeiboClient
import json
# access_token , params中的id需要替换
access_token = '2.00XXXXXXXXXXXXXXXXXXXXXX'
client = WeiboClient(access_token)
#调用API
result = client.get(suffix='comments/show.json', params={'id': 496044833636XXXX, 'count': 50, 'page': 1})
json_result = json.dumps(result)
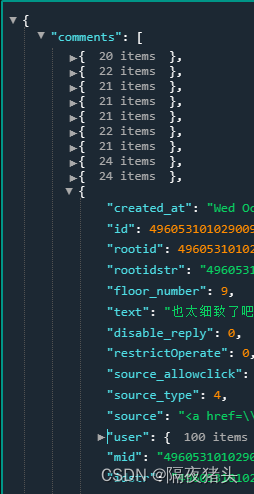
print(json_result)执行上述程序,我们即可获得微博(page=1)对应的评论数据,得到的数据是JSON格式,复制得到的数据,可以通过JSON可视化网站进行可视化。
3.🌕获取“所有”评论数据 🌕
很显然,我们知道如果采用思路一,即在网页下爬取评论数据,我们做过这样的测试,发现在思路一下每条微博最多能获取200条左右的数据(即在拿到200条数据后,返回的数据为空,受到限制)。故此,通过思路二的方式我们可以爬取微博下的全部评论,这里的全部其实是一个引号,当然API能爬到的评论受到的限制远小于在网页上获取数据。
接下来,我们设计获取尽可能多的评论,通过第三部分知道,我们是通过变量page来获得数据。
import re
import time
import pandas as pd
from weibopy import WeiboClient
import csv
# 下面两行的解释在第三部分有详细说明
access_token = '2.00XXXXXXXXXXXXXXXXXXXXXX' #替换为自己应用的token,获取方法见本文第二部分
client = WeiboClient(access_token)
comment_list = [] # 保存所有评论正文
# 共获取 10 页 * 每页最多 50 条评论
for i in range(1, 11):
result = client.get(suffix='comments/show.json', params={'id': 4966558150951081, 'count': 50, 'page': i})
comments = result['comments']
if not len(comments):
break
for comment in comments:
# 获取微博文本
original_text = comment['status']['text']
# 获取评论文本
text = re.sub('回复.*?:', '', str(comment['text']))
created_at = comment['created_at']
# 获取评论时间
created_time = str(pd.Timestamp(created_at).tz_convert(tz=None))
# 获取评论地区
location = comment['user']['location']
# 拼接数据
comment_concat = [original_text, created_time, text, location]
comment_list.append(comment_concat)
print('已抓取评论 {} 条'.format(len(comment_list)))
time.sleep(1)
# 将数据写入csv文件中
with open("result.csv", 'w', newline='', encoding="utf-8") as f:
writer = csv.writer(f)
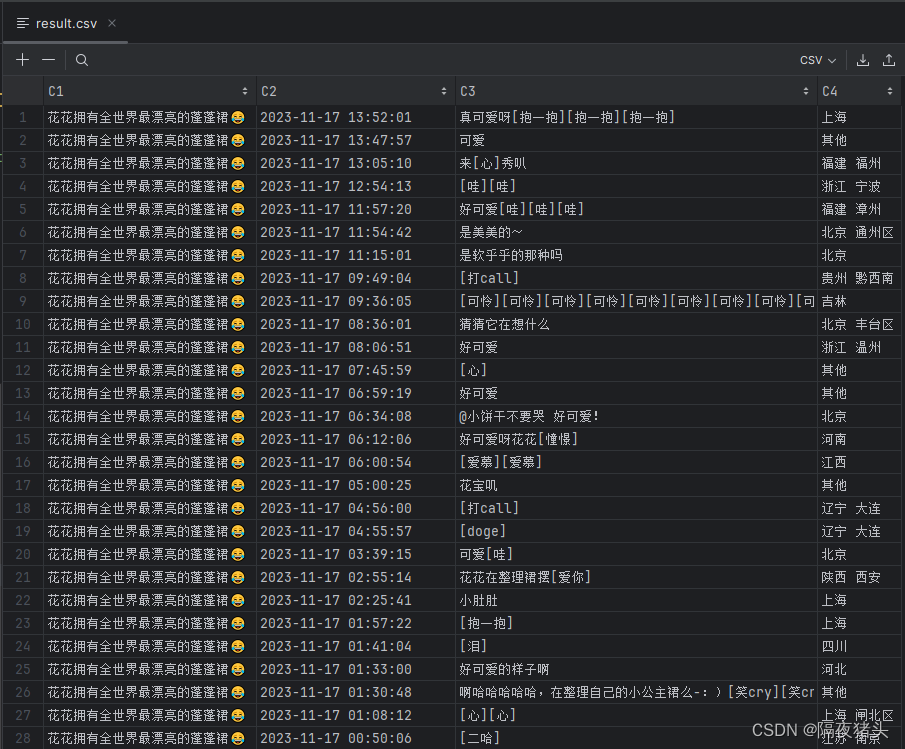
writer.writerows(comment_list)结果:
已抓取评论 45 条
已抓取评论 84 条
已抓取评论 121 条
已抓取评论 165 条
已抓取评论 207 条
已抓取评论 240 条
已抓取评论 283 条
已抓取评论 321 条
已抓取评论 336 条Process finished with exit code 0
四、🌍总结 🌍
3.🌕代码汇总🌕
只需要配置自己的token,修改你想要爬取的微博ID,不用任何修改!!!
童叟无欺,直接上手,话不多说,代码附上!
# -----------------------------------------------------------------#
# Step1:先创建一个py文件,写入以下内容,用于获取你的token
'''
import webbrowser #python内置的包
from sinaweibopy3.sinaweibopy3 import APIClient
APP_KEY = '857XXXXXX'#注意替换这里为自己申请的App信息
APP_SECRET = '110f8c95d7d371964e08XXXXXXXXXXXX'
CALLBACK_URL = 'https://api.weibo.com/oauth2/default.html'#回调授权页面
#利用官方微博SDK
client = APIClient(app_key=APP_KEY, app_secret=APP_SECRET, redirect_uri=CALLBACK_URL)
#得到授权页面的url,利用webbrowser打开这个url
url = client.get_authorize_url()
print(url)
webbrowser.open_new(url)
code = input('输入 code:')
r = client.request_access_token(code)
print(r)
'''
# -----------------------------------------------------------------#
# Step2:创建第二个py文件,将你的token写入到这里
from weibopy import WeiboClient
access_token = '2.00c7LqqH0CJbDw49044ad8XXXXX' #替换自己的token
client = WeiboClient(access_token)
# -----------------------------------------------------------------#
#调用API
result = client.get(suffix='comments/show.json', params={'id': 4966558150951081, 'count': 50, 'page': 1})
# import json
# json_result = json.dumps(result)
# # print(json_result)
# -----------------------------------------------------------------#
import re
import csv
import time
import pandas as pd
comment_list = [] # 保存所有评论正文
# 共获取 10 页 * 每页最多 50 条评论
for i in range(1, 11):
result = client.get(suffix='comments/show.json', params={'id': 4966558150951081, 'count': 50, 'page': i})
comments = result['comments']
if not len(comments):
break
for comment in comments:
# 获取微博文本
original_text = comment['status']['text']
# 获取评论文本
text = re.sub('回复.*?:', '', str(comment['text']))
created_at = comment['created_at']
# 获取评论时间
created_time = str(pd.Timestamp(created_at).tz_convert(tz=None))
# 获取评论地区
location = comment['user']['location']
# 拼接数据
comment_concat = [original_text, created_time, text, location]
comment_list.append(comment_concat)
print('已抓取评论 {} 条'.format(len(comment_list)))
time.sleep(1)
# 将数据写入csv文件中
with open("result.csv", 'w', newline='', encoding="utf-8") as f:
writer = csv.writer(f)
writer.writerows(comment_list)
展望
本文通过调用微博API进行爬取微博评论,克服了在网页端爬取时,对于每条微博限制爬取200条左右的评论,并且在数据预处理方面,通过API调用也更简洁,对新手十分有利。
思考,微博官方对每个用户的token设置了访问API的限制,如何才能避免限制爬取多条微博的多条评论,在下一篇文章中,我们的工作引入了反爬机制,爬取了接近20万余条评论记录。下一篇工作:【Python爬虫】高效实现的微博爬虫代码资源 https://blog.csdn.net/weixin_51167671/article/details/137262187?spm=1001.2014.3001.5501
https://blog.csdn.net/weixin_51167671/article/details/137262187?spm=1001.2014.3001.5501


















 812
812

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









