







本文整理自Coursera Machine Learning Exercise 5,提取出了训练一个模型的主要步骤。
matlab源码地址weekend6/LinearReg
1. visualizing the dataset
2. Model selection
2.0 Feature mapping and normalization
2.1 Model selection for p
2.2 Model selection for
λ
3. Estimating generalization on test set
下面是分步解释
1.visualizing the dataset
一般情况下,要是数据集能事先可视化,那么在选择模型的时候就相对的有了一点谱;但如果不能可视化,凭后面的学习曲线来分析,我想也是能达到一样效果的。
%% Visualzing.m
% Load from ex5data1:
load('ex5data1.mat');
m = size(X,1);
plot(X,y,'rx','MarkerSize',10,'LineWidth',1.5);
xlabel('Change in water level (x)');
ylabel('Water flowing out of the dam (y)');载入数据集之后我们可以看到,里面一共有三组分别是:训练集,验证集,测试集;且数据集的特征只有一个维度。
2.Model selection
原练习中直接选取了一个模型,不具有说明性;我们现在来假设几个模型,然后来进行筛选;下面列举了10个模型
需要注意的是,现在虽然么个模型中有
p
个特征,且最高每个模型的最高幂次为
所以我们就需要一个把原数据集映射到 p 维的函数。
2.0 Feature mapping and normalization
%% polyFeatures.m
function [X_poly] = polyFeatures(X, p)
X_poly = zeros(numel(X), p);
X_poly = X;
for i = 2:p
X_poly = [X_poly,X .^ i];
end
end
在映射完之后,我们就会发现特征值之间的范围差距特别大,比如
%% featureNormalizaion.m
function [X_norm, mu, sigma] = featureNormalize(X)
% standardazation
mu = mean(X);
X_norm = bsxfun(@minus, X, mu);
sigma = std(X_norm);
X_norm = bsxfun(@rdivide, X_norm, sigma);
end
里面关于bsxfun()函数的用法戳此处
2.1 Model selection for p
当我们任意选取一个模型之后,接下来的工作就是训练参数了。下面用到的训练方法依然是ng提供的fmincg,我们前面也多次用到过这个函数,只需要提供代价函数,一个关于每个参数的梯度就能得到训练好的参数。(当然也可以梯度下降)
下面是代价函数以及梯度的求解,之所以一开始就预留了参数 λ 的位置,是因为:到底进不进行规则化我们开始是不知道的,要通过学习曲线来分析,如果不需要,我们在训练模型的时候把 λ 设为0就行了;如果需要,则传递相应的值即可,这样就更方便了。
%% linearRegCostFuntion
function [J, grad] = linearRegCostFunction(X, y, theta, lambda)
m = length(y); % number of training examples
J = 0;
grad = zeros(size(theta));
h_theta = X*theta;
squar_error = (1/(2*m))*(sum((h_theta-y).^2));
regular_term = (lambda/(2*m))*(sum(theta.^2) - theta(1)^2);
J = squar_error + regular_term;
grad(1) = (1/m)*sum((h_theta - y).*X(:,1));
for j = 2:size(theta,1)
grad(j) = (1/m)*sum((h_theta - y).*X(:,j))+(lambda/m)*theta(j);
end
grad = grad(:);
end
下面是调用fminc来训练参数的函数
%% trainLinearReg.m
function [theta] = trainLinearReg(X, y, lambda)
initial_theta = zeros(size(X, 2), 1);
% Create "short hand" for the cost function to be minimized
costFunction = @(t) linearRegCostFunction(X, y, t, lambda);
% Now, costFunction is a function that takes in only one argument
options = optimset('MaxIter', 200, 'GradObj', 'on');
% Minimize using fmincg
theta = fmincg(costFunction, initial_theta, options);
end
%% p = 5
lambda = 0;
theta = trainLinearReg(X_poly,y,lambda);
J_error = linearRegCostFunction(X_poly_val,yval,0);此时,我们已经训练得到了当 p=5 时参数 Θ (注意没有规则化),并且在验证集上计算出了代价值;接下来,我们也算出其余模型下的参数和代价值;
注意,在任何时候,我们只在训练的时候可能会要正则化项;但在训练好参数后计算误差时,都不需要正则化项,所以第四个参数我直接写成了0,不管前面 λ 是多少。
J_error = 29.433818 when p = 1.000000
J_error = 6.994650 when p = 2.000000
J_error = 5.768795 when p = 3.000000
J_error = 9.216278 when p = 4.000000
J_error = 15.629587 when p = 5.000000
J_error = 21.576766 when p = 6.000000
J_error = 9.19248 when p = 7.000000
J_error = 7.810592 when p = 8.000000
J_error = 8.389444 when p = 9.000000
J_error = 8.618122 when p = 10.000000
后面两个是我顺便计算的,可以发现,只有当 p=3 的时候 Jcv−error(θ) 是最小的,所以自然就选择了它;同样,我们再来看看其模型随 p 变化学习曲线:(关于学习曲线,参见此处)
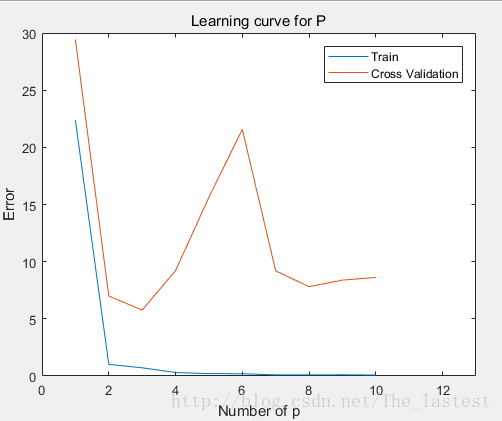
横坐标是p的值,也也可以看到:当
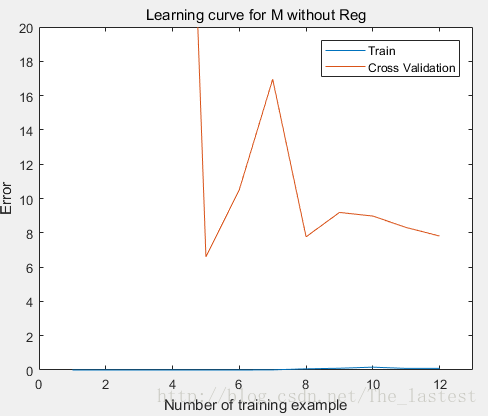
我们可以明显的发现,随着训练集的增长, Jcv−error 仍然有下降的趋势,这就说明模型出现了过拟合的现象,泛化误差大需要规则化(或者增大数据集)。
2.2 Model selection for λ
同
p
的选择一样,在选择
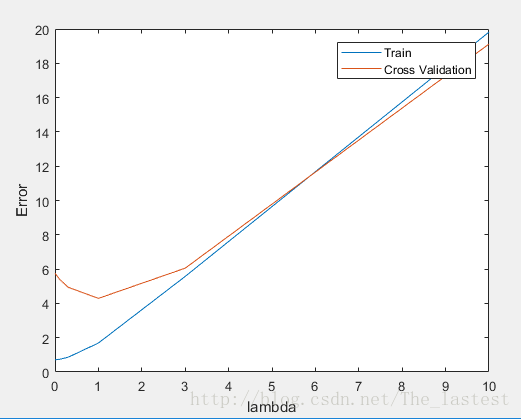
我们可以看出,当 λ=1 时, Jcv−error(θ) 最小,所以当然也就选择它了。此时,我们再来画出模型随数据集增长得学习曲线来分析其泛化能力:
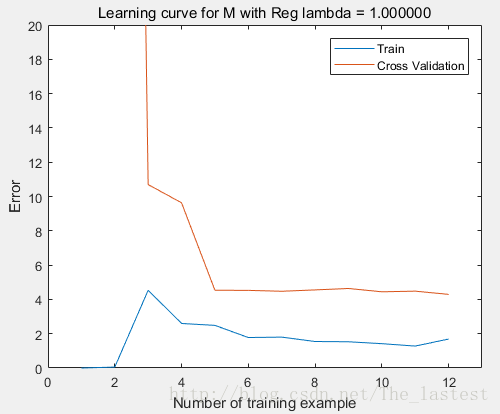
可以发现,明显比没有规则化之前好多了。但是随着数据集的增大, Jcv−error(θ) 仍然有减小的趋势,说明该模型还是可能有点过拟合(高方差);而此时也就只能通过增大数据集来解决了。
3.Estimating generalization on test set
theta = trainLinearReg(X_poly,y,lambda);
J_error = linearRegCostFunction(X_poly_test,ytest,theta,0);
fprintf('J_error = %f\twhen p = %f\tlambda = %f\n',J_error,p,lambda);
%% output
J_error = 5.025814 when p = 3.000000 lambda = 1.000000
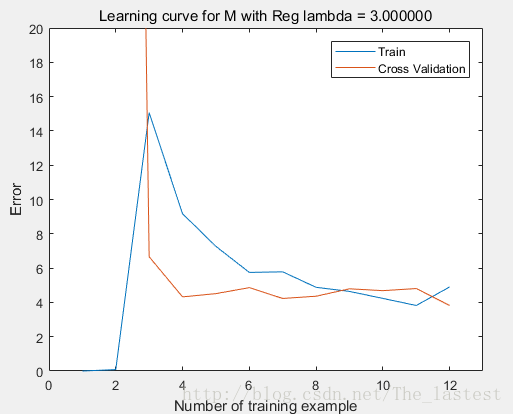
但是,其实原练习中选取的模型是 p=8,λ=3 ,与这里的结果又一点差异。对于为什么 p <script type="math/tex" id="MathJax-Element-170">p</script>选8,我估计用的是两个嵌套循环来遍历了所有情况。















 6397
6397

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









