






点击上方“深度学习大讲堂”可订阅哦!
编者按:随着终端摄像设备的普及,互联网上存在着海量的数据资源。然而,由于这些数据存在无标注、有噪标注等问题,并不能够直接应用于机器学习任务。在如今“数据为王”的时代,如果能够利用小样本精确标注数据来训练模型,并进一步泛化到大样本有噪标注、乃至无标注数据中,将为基于图像的机器学习任务带来巨大进步。本文中, CVPR2017 WebVision图片分类竞赛冠军黄伟林博士,将为大家介绍,如何利用海量无精确人工标注的网络图片,训练高性能神经网络模型。文末,大讲堂特别提供文中提到所有文章的下载链接。
本文整理自Valse Webinar 2017-11-29期报告。


我所在的码隆科技团队在CVPR 2017 WebVision图片分类竞赛中取得了冠军,这里主要就比赛经验和大家分享一下。
训练一个神经网络通常需要数据 (ImageNet, Webvision)、网络 (AlexNet, GoogleNet, VggNet和ResNet等)、损失函数三个必要成分。这三个方面在训练过程中扮演什么样的角色呢?首先,数据是学习的资源;其次,网络结构主要解决“how to do”的问题,指导网络如何完成一项任务,它提供从输入图像到特征空间的一个映射;然后,损失函数主要解决“what to do”的问题,指导网络做什么事情,比如分类,检测和分割等任务。 最终模型性能高低体现在哪一部分呢? 卷积神经网络其实是一个特征提取过程,只要特征这块提取的好,剩下的任务就相对简单了。而决定特征的好坏,就是中间这个how to do这块,也就是训练CNN得到的参数和最终模型。这里就像人的大脑,是由大量的神经元组成的。我们训练一个神经网络,就好比一个人,或者一个婴儿的学习过程。决定它性能的好坏有三个因素:数据,网络结构,loss方程。除了这三个,还有一个非常重要却经常被人们忽略的因素——学习策略,最近几年在机器学习圈子里它的关注度逐渐升温。所谓学习策略,是指采用一定的学习计策让模型学习得更加高效。比如教一个小孩学习,为了使他学得更高效,就不可能让一个小学生去学习大学课程,而是采用循序渐进的由易及难策略。在这里主要跟大家分享我们在学习策略方面的改进。
此外值得一提的是,在刚才所提的三方面中,我个人认为数据是最重要的,深度学习由数据驱动。在现实应用特别是公司项目中,如果能够较好地定义、收集及标注数据,那么项目就成功了70%。但是在学术圈,大家通常在标准的数据集(benchmark)上进行工作,所以网络结构(方法、模型)更受关注,这大概是学术圈过去五六年一直在做的一个主要东西。从2012年的ImageNet到今年的SENet,网络性能在不断提高,甚至今年ImageNet上top-5 error已经到了2.2%,所以经过多年的发展新模型结果的改进已趋向饱和。
最近两年学术圈的关注点集中在如何设计损失函数,有两个方面的工作。其一,随着数据及任务复杂度的提升,大家设计更加复杂的损失函数来解决更加复杂的问题,比如最近Mask R-CNN是在物体检测的框架上,进一步解决更加复杂的instance-level segmentation问题;其二,通过优化或者额外设计损失函数来提高模型的综合性能,可以添加额外的监督信息或者其他信息来训练模型,比如最近基于attention机制的模型通过额外的损失函数来提高模型的性能。

下面说说WebVision这个比赛。 我们参加CVPR 2017 WebVision竞赛的出发点是什么?首先,ImageNet比赛的性能已经趋向饱和,图片分类top-5错误率从2009年的30%降到了2017年的2.2%,我们想尝试一下更具有挑战性的任务,在没有人工标注的情况下训练高效的卷积神经网络,这属于弱监督学习的一个问题。此外,我们想尝试在现实世界中训练大规模的数据,并探索数据、模型结构、损失函数以及训练策略在训练模型过程中起的作用。最后,WebVision的数据场景跟目前多数AI公司用的数据非常相似。利用网络图片训练网络符合当前工业界的主流和趋势。以上是我们参加比赛的主要出发点。

Webvision比赛主要是由ETH(苏黎世联邦理工)、谷歌和CMU共同举办的,如图是举办者的一些信息。
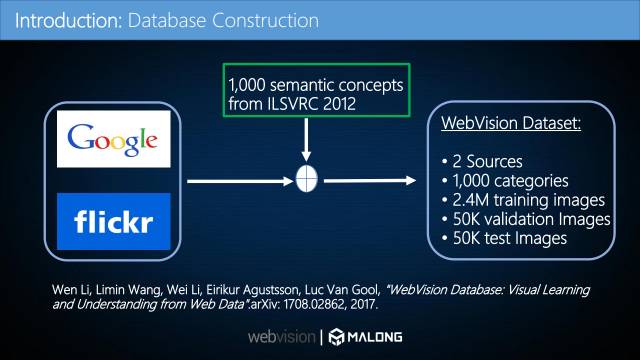
WebVision数据集主要有Google和Flickr两个数据源。 主要是利用ImageNet 1000个类的文本信息从网站上爬数据,所以它的数据类别与ImageNet完全一样,为1000类别,由240万幅图片构成训练数据,比ImageNet的两倍还多,分别由5万张图片构成验证集和测试集(均带有人工标注)。
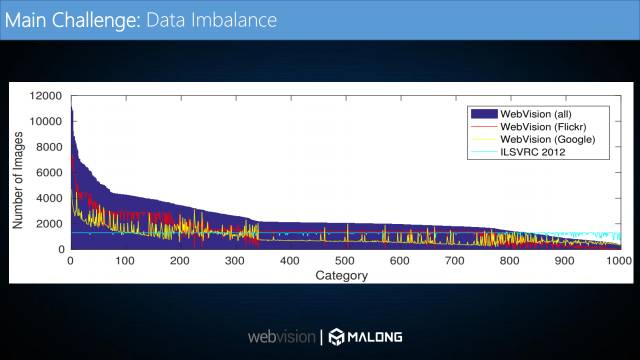
WebVision数据集主要有两个挑战。
第一个挑战,数据分布非常不平衡。如图横坐标代表1000个类别,纵坐标代表每个类别的图片数量。如图浅蓝色的平稳曲线是ImageNet的数据分布,每一个类别大概有1200张图片。而深蓝色曲线为WebVision数据分布,可以看出有的类别高达11000张而最少的小于400张图片,这种极度不平衡的分布对训练模型影响非常大。

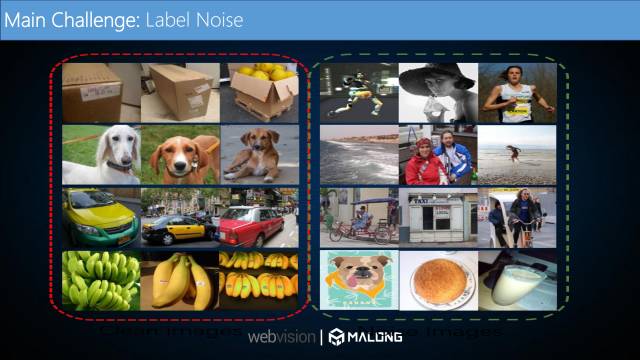
第二个挑战,数据集含有大量错误标签。如图所示,每一行代表一个类别,从图中可以看出数据集中含有大量与类别不相关的图片,也就是所谓的噪声,这也是最主要的一个难点。

处理含有大量错误标签的算法通常有两种。第一种方法直接从有噪数据中学习,这里有两种思想,其一是设计一些对噪声鲁棒的算法,其二是让模型自动检测出干净样本和有噪样本,然后直接丢弃或者修正错误标签,再进行模型训练。这类方法有一个缺点,即很难从难训练样本 (hard training samples)中准确识别出错误标签的样本, 而这些hard samples 通常对提升模型的性能是非常重要的。 第二种方法主要采用半监督学习,只提供一小部分人工标注样本,将有标注的小样本上训练的模型泛化到无标注的样本上,这类方法的缺点是需要一小部分人工标注的样本才能完成, 并且泛化能力和模型性能是主要问题。 近来,深度学习方法在这两方面都有一些相关的工作。
那么,如何在使用标准神经网络的情况下提高模型的性能呢?我们引入了新的训练策略——课程学习(curriculum learning)。

我们可能是第一次将“课程学习”应用到大规模非人工标注的数据上,以解决大量错误标签的问题。课程学习(curriculum learning)是Bengio于2009年提出来的,从论文引用量来看,这个方法最初几年并没有得到特别广泛的应用。但是,随着数据量、学习任务及复杂度的增大,最近两年课程学习的热度不断升温。如何提高模型的泛化能力和综合性能变得愈加重要,特别是在现实应用中,Deepmind,OPEN AI最近一年也有关于课程学习的文章陆续发表。例如:
Alex Graves · Marc Bellemare · Jacob Menick · Remi Munos · Koray Kavukcuoglu: Automated Curriculum Learning for Neural Networks, ICML, 2018.
Tambet Matiisen, Avital Oliver, Taco Cohen, John Schulman: Teacher-Student Curriculum Learning, arXiv:1707.00183, 2017.
课程学习的基本思想是,将一个复杂的任务分成一系列子任务,把任务按简单到难的程度进行排序,在学习过程中让模型由易到难地学习。在大规模数据里,我们可以把整个数据集分成一系列子集, 将子集按简单干净数据到复杂有噪数据进行排序,然后在模型训练过程中,让网络从简单干净的数据集开始学习,通过增加数据集的难度逐渐提高模型的能力。这个机理和人的学习机理是非常相似的,人类接受的教育也是经过由易到难高度组织编排的。

这里是课程学习标准的流程。首先将学习任务分成一系列子任务,然后根据难度对子任务进行排序,再设置一个任务转换的阈值(从一个任务跳转到另一个任务的条件)。从机器学习的角度来看,课程学习就是在各个子任务之间寻找一个最优路径使得整个模型能够收敛得更快且具备更好的泛化能力。它的整体思路非常简单:学习完一个简单任务之后再开始学习一个更难的任务。

如图是理想状态下课程学习的过程。对于三个任务task1,task2,task3,左图中横坐标表示任务学习的进程,纵坐标表示任务完成程度。整个学习过程是先学习task1,然后task2,最后task3。如何进行学习进程的切换以及学习时间段和学习任务是如何对应的呢?如右图所示,每一个学习阶段每一个任务都有其对应的概率分布, 根据这个概率分布来决定左图的tasks顺序。
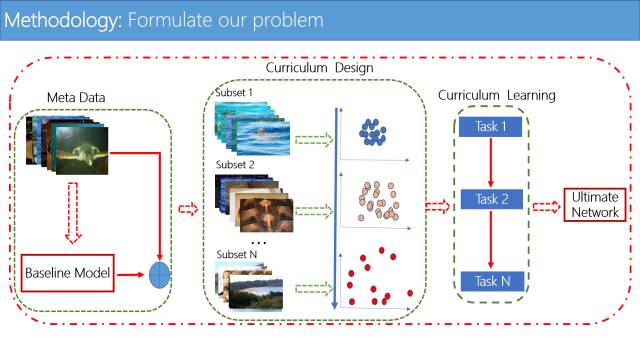
接下来介绍我们在WebVision比赛中所用的框架。我们将课程学习方法用到WebVision大规模非人工标注的数据上,这个框架主要由三个部分构成。
第一个部分是对所有图片进行特征提取,先用所有数据训练一个基础的卷积神经网络, 来进行图片特征提取。第二部分是课程设计,通过第一部分提取的特征进行课程设计,利用图片特征定义该图片的难易程度,用它来设计课程。第三部分利用设计好的课程进行课程学习,来逐渐优化和迭代模型。
这里面两个主要部分是课程设计和课程学习。课程设计是最重要的,它的好坏直接决定模型的性能。难点在于没有先验知识的情况下如何定义数据集或者图片的难易程度呢?
我们在这里提出了一个无监督方法来设计课程方法,在特征空间里根据这些样本的密集度来定义数据复杂度。我们的猜想是这样的: 样本越密集,表示图片特征越相似,我们假设这些数据集较干净(简单);样本越稀疏,表示图片越多样化,就认为这个数据集较复杂(难)。我们的目标是在整个训练集中, 需要不同空间密度的数据子集。 根据此思路来设计课程。

如上图是课程设计的具体步骤:首先将整个训练集分为一系列子集,然后根据难易程度对子集进行排序,这里我们采用density-distance的聚类方法在每个类别数据中进行子集分类,这个聚类方法最早在2014年的Nature上发表。具体做法分为三步:
第一步,通过卷积神经网络对每一个样本提取特征,在特征空间里计算每一类别所有样本的欧氏距离,构成一个距离矩阵;
第二步,计算每一个样本的密度值,通过设置距离参数d,当距离小于这个参数时,将距离加1,否则认为距离为0,通过上图第二步公式计算样本密度值;
第三步,对每一个样本计算密度距离值,对第二步得到的样本密度进行从高到低排序,然后在密度最大的点处计算离它最远的点的距离,把该点当成该点的密度距离值。 如果该点密度不是最大值,计算密度比它大的所有点中,与它最近的点的距离,当成该点的密度距离值。最后, 我们每一个样本都可以得到一个密度值和密度距离值, 根据这两个值来定义聚类中心点。

如图,横坐标表示密度值,纵坐标表示密度距离值,聚类中心的值通过对应横纵坐标值相乘而得到。简单地把两个值相乘,进行从大到小排序,值越大,说明它为聚类中心的可能性越大,聚类中心点如图右上角三角所示,通过计算横纵坐标乘积值与聚类中心的距离对样本进行聚类。如图可以聚出三类,我们定义了每个聚类子集样本数量的比例为:第一个60%,第二个类20%,第三个类20%。
根据上述方法,我们在Webvision里随机选取图片对“猫”这个类别做了聚类,可以看出图片集的干净程度由subset1, subset2到subset3依次递减。

这也是根据我们的方法对Webvision数据集中另外两类的结果。可以看出,我们的课程设计算法能够有效地把训练样本分成不同难易程度,从而让这些样本按照设定的顺序来逐步训练CNN。 课程学习的思路比较简单,但是课程设计的方法却是多样的。需要指出的是,最近斯坦福大学的李飞飞教授和她在谷歌的团队也同样利用了课程学习这个思路来解决错误标签问题,她们设计了一个MentorNet来评估每个样本的难易程度。详细内容见Arxiv上2017年12月14日的文章:Lu Jiang, Zhengyuan Zhou, Thomas Leung, Li-Jia Li, Li Fei-Fei: MentorNet: Regularizing Very Deep Neural Networks on Corrupted Labels, arXiv:1712.05055, 2017.
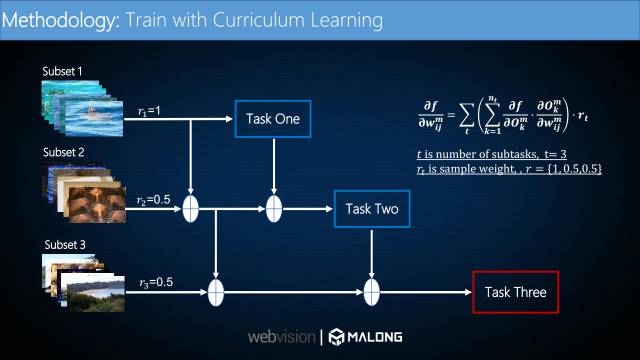
接下来介绍课程学习的基本流程。根据上述课程设计的方法,我们将每个类别中的数据分成了三个子集,然后将整个数据集中所有类别数据的第一子集合成一个数据集,作为整个数据集的subset1(第一子集)。对二、三子集进行同样的操作。这就构成了整个数据集的subset1(比较干净的数据),subset2(含有部分噪声的数据),subset3(噪声较大的数据)。我们采用逐步迭代的思想对这三个子集依此进行模型训练:首先在第一个子集上训练一个模型,然后将前两个子集合起来作为训练集, 并在第一个模型的基础上再训练, 最后将三个子集结合在一起, 并在第二个模型的基础上再训练。我们在训练过程中给三个子集的样本设置不同的权重(1,0.5,0.5),更多依赖于置信度高的子集以提高模型的准确率。
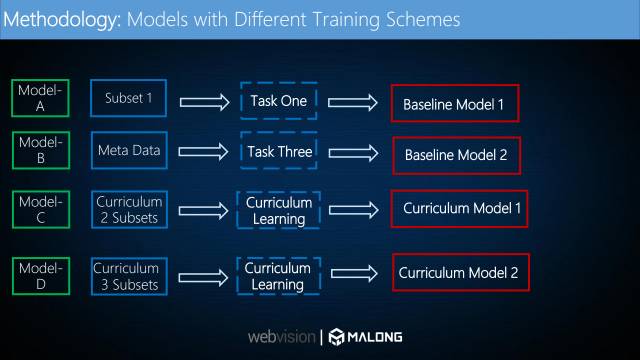
我们用了四个模型来做对比试验。模型A是由subset1(较干净子集)训练得到的,模型B是由所有数据直接训练得到的,模型C和D都采用课程学习的策略训练得到,不同之处在于模型C是将训练数据分为两个子集而得到的,模型D是将训练数据分为三个子集而训练得到的。

由于WebVision数据集是极度不平衡的,我们做了选择性的数据平衡。在课程子集个数为3,mini-batch为256的情况下,我们做了两个层面的数据平衡。第一,在子集之间做数据平衡,每个mini-batch里面,将第一子集图片个数定义为128,其他两个分别为64,在训练过程中它们的比重是相同的;第二,在干净子集上做类别之间的平衡,比如在子集一上随机选取128个类别,每一个类别只随机选取一个样本。实验表明,类别平衡只适用于干净子集,而对于含噪子集其效果反而下降。

为了加强底层特征,我们在底层使用了大小分别为5,7,9三种大小的卷积核,然后将分别得到的特征图连接作为底层的特征图。实验表明该方法对模型整体性能有0.5%的提升。

我们对比了四个模型的test loss的曲线,同时对比了k-means聚类方法来做课程设计的效果,虚线部分为k-means的。从图中可以看出,聚类方法对课程学习有很强的影响,课程设计有效提高了整个模型性能。
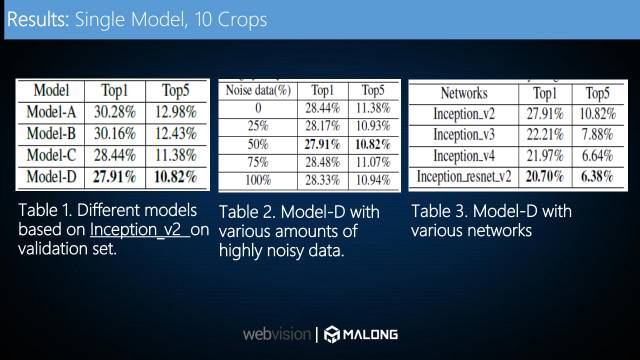
如表1是对四个模型错误率的对比,可以看出使用课程学习的模型C,D相对于未使用课程学习的模型A,B性能有明显提升。
如表2,加入第三子集(含大量噪声数据)会对模型性能有所提升,实验表明当采用第三子集50%的数据量时,模型能力最优。我们发现在不使用subset3 情况下,模型性能反而不如加入这些含有大量噪声的数据。这说明,在使用了我们课程学习的算法后,即使是噪声数据,也对模型的综合能力有一定的正面作用。这些噪声数据更像是对模型提供了一个regularizer的作用,提高模型泛化能力。
之前的实验都是在Inception_v2上做的,我们也利用了其他网络进行对比,结果如表3所示。Inception_v3之后的模型性能提升很明显。
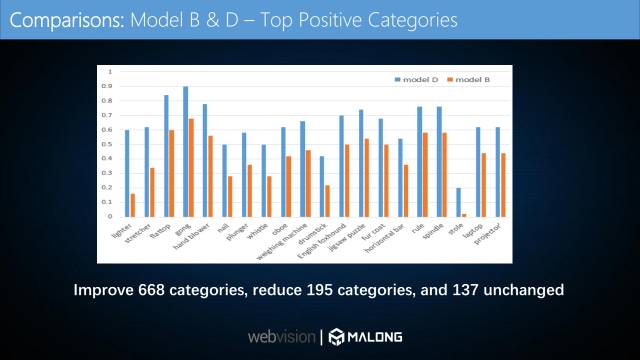
如图,我们对比了使用全部数据集而未使用课程学习的模型B与使用课程学习策略得到的模型D对每个类别数据的识别准确率。挑选了提高最多的15个类别。横坐标为类别,纵坐标为准确率。使用课程学习策略后,1000个类别中,有668类性能提升,195类性能下降,137类基本没有变化。

这是加入课程学习后性能降得最多的15个类。可以看出其实性能下降得并不是很多。
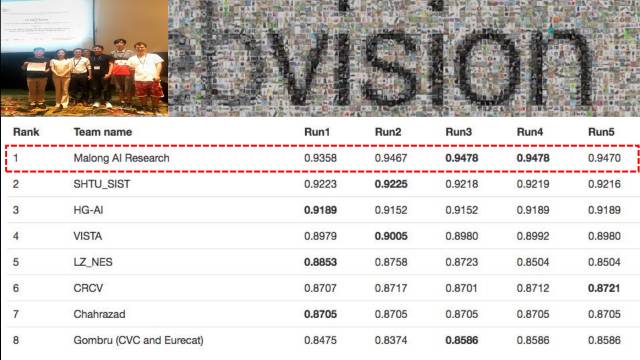
这是我们提交的最终结果,最终合成了大概6个模型。最高准确率为94.78%,错误率为5.2%,这非常接近ImageNet上人类的performance。

总结一下,WebVision比赛旨在利用大规模网络图片训练高性能的卷积神经网络,使其能够抑制标注不一致和数据不平衡问题,并探讨提高模型泛化能力的方法,使得能够在现实场景中利用从网络上爬的数据。我们的研究团队今后还会继续开发弱监督或者半监督方法在这些方面的算法和应用。

我们团队一共有9个人。该工作主要由我们的研究员郭胜博士完成。

过去两年中,我们团队在大规模比赛中取得了优异的成绩:
ICCV 2015: ILSVRC2015(ImageNet):场景分类,第二名;
CVPR 2015:大规模场景理解竞赛(LSUN):场景分类,第二名;
CVPR 2015:ChaLearn Looking at People Chanllenge 2015:文化活动识别,第三名;
CVPR 2016:大规模场景理解竞赛(LSUN):场景分类,第一名;
ECCV 2016:ILSVRC2016(ImageNet):场景分类,第四名;
CVPR 2017: Webvision图像分类竞赛,第一名。


简单介绍一下码隆科技,公司旨在利用深度学习和计算机视觉技术做通用商品识别,比如进行10万类的商品识别。我们的主要产品是ProductAI。利用商品识别的优势,我们也在大力拓展最近很火的新零售行业,比如无人售货店,无人超市。 另外,我们也在做工业检测及分子级别的检测,深挖垂直行业的AI应用场景,为行业提供“新”的生产力。

谢谢大家,我们长期招收Research Intern,Research Engineer 和 Research Scientist。 我们会提供非常有竞争力的Package。诚挚欢迎有志之士的加入!

文中黄老师提到的文章下载链接为:
https://pan.baidu.com/s/1miGcSly
致谢:

本文主编袁基睿,诚挚感谢志愿者杨茹茵对本文进行了细致的整理工作

该文章属于“深度学习大讲堂”原创,如需要转载,请联系 astaryst。
作者信息:
作者简介:

黄伟林,码隆科技首席科学家。曾在英国牛津大学Andrew Zisserman的VGG组做博士后, 和中国科学院的助理教授。 他博士毕业于英国曼彻斯特大学, 研究兴趣包括场景文本检测识别、大规模图像分类和医学图像分析。 黄伟林博士长期但任计算机视觉领域主要会议ICCV、CVPR、ECCV和AAAI的审稿人/PC member。他所在团队获得2015年ImageNet场景识别竞赛的亚军,也获得了CVPR 2017 WebVision挑战赛的冠军。个人主页:whuang.org
VALSE是视觉与学习青年学者研讨会的缩写,该研讨会致力于为计算机视觉、图像处理、模式识别与机器学习研究领域内的中国青年学者提供一个深层次学术交流的舞台。2017年4月底,VALSE2017在厦门圆满落幕,近期大讲堂将连续推出VALSE2017特刊。VALSE公众号为:VALSE,欢迎关注。

往期精彩回顾



欢迎关注我们!
深度学习大讲堂是由中科视拓运营的高质量原创内容平台,邀请学术界、工业界一线专家撰稿,致力于推送人工智能与深度学习最新技术、产品和活动信息!
中科视拓(SeetaTech)将秉持“开源开放共发展”的合作思路,为企业客户提供人脸识别、计算机视觉与机器学习领域“企业研究院式”的技术、人才和知识服务,帮助企业在人工智能时代获得可自主迭代和自我学习的人工智能研发和创新能力。
中科视拓目前正在招聘: 人脸识别算法研究员,深度学习算法工程师,GPU研发工程师, C++研发工程师,Python研发工程师,嵌入式视觉研发工程师,运营经理。有兴趣可以发邮件至:hr@seetatech.com,想了解更多可以访问,www.seetatech.com


中科视拓

深度学习大讲堂
点击阅读原文打开中科视拓官方网站














 724
724











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









