







混合专家系统(Mixture of Experts)
原理:
混合专家系统(MoE)是一种神经网络,也属于一种combine的模型。适用于数据集中的数据产生方式不同。不同于一般的神经网络的是它根据数据进行分离训练多个模型,各个模型被称为专家,而门控模块用于选择使用哪个专家,模型的实际输出为各个模型的输出与门控模型的权重组合。各个专家模型可采用不同的函数(各种线性或非线性函数)。混合专家系统就是将多个模型整合到一个单独的任务中。
混合专家系统有两种架构:competitive MoE 和cooperative MoE。competitive MoE中数据的局部区域被强制集中在数据的各离散空间,而cooperative MoE没有进行强制限制。
对于较小的数据集,该模型的表现可能不太好,但随着数据集规模的增大,该模型的表现会有明显的提高。
定义X为Nd维输入,y为Nc维输出,K为专家数,$\lambda $为学习率:
各专家输出为: V i k = w i k x V_{ik}=w_{ik}x Vik=wikx
(其中 w i k w_{ik} wik为第k个专家模型对第i列输出的权重, V i k V_{ik} Vik为第k个专家对第i列的预测。( w i k w_{ik} wik添加了bias所以输出为d+1维))
第k个专家输出均值为:
门限模块输出为:
输出 y i y_i yi通过softmax函数转成概率值为:
对于Cooperative MoE:
Δ m k = λ ( y i − y s i ) ( v i k − y s i ) g k x \Delta m_{k}=\lambda(y_{i}-y_{si})(v_{ik}-y_{si})g_{k}x Δmk=λ(yi−ysi)(vik−ysi)gkx
对于Competitive MoE:
Δ m k = λ ( f k − g k ) x \Delta m_{k}=\lambda (f_{k}-g_{k})x Δmk=λ(fk−gk)x
y i k = e V i k ∑ i e V i k y_{ik}=\frac{e^{V_{ik}}}{\sum_{i}e^{V_{ik}}} yik=∑ieVikeVik
f k = g k e ∑ i y i l o g y i k ∑ l g l e ∑ i y i l o g y i k f_{k}=\frac{g_{k}e^{\sum_{i}y_{i}logy_{ik}}}{\sum_{l}g_{l}e^{\sum_{i}y_{i}logy_{ik}}} fk=∑lgle∑iyilogyikgke∑iyilogyik
实验结果:
不同数据集相同k值:
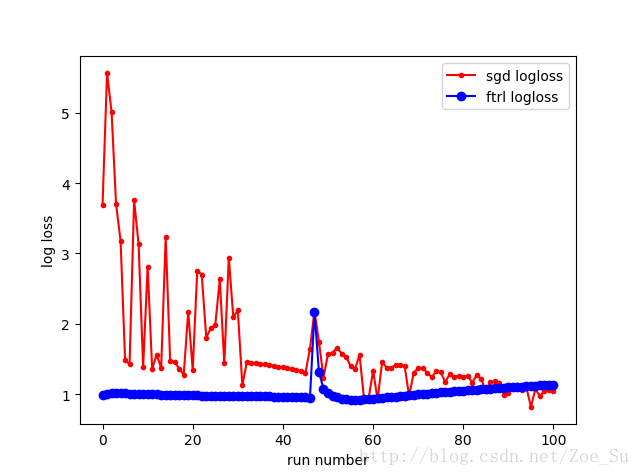
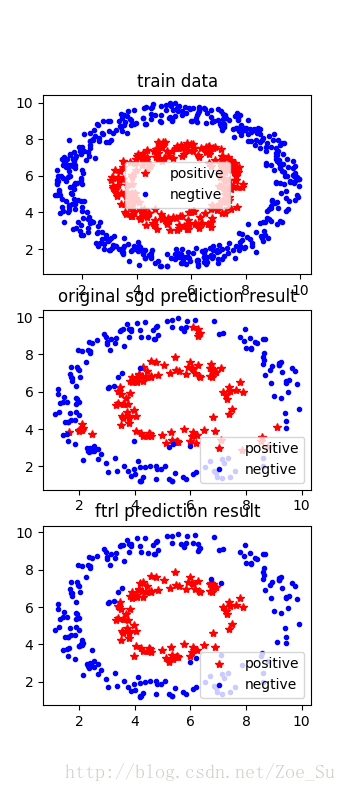
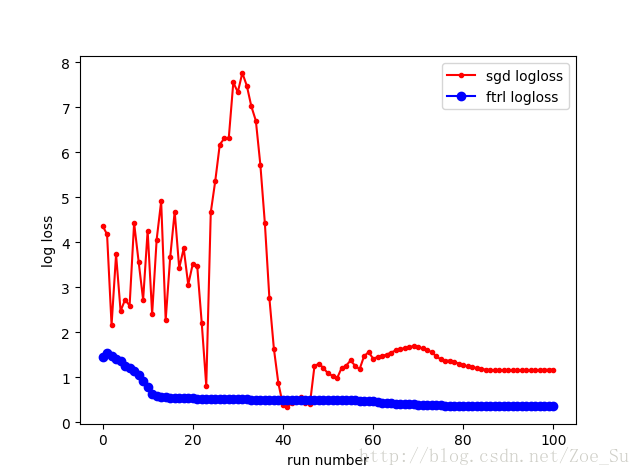
- k=2使用线性数据集,采用SGD和FTRL两种训练方式,结果如下:
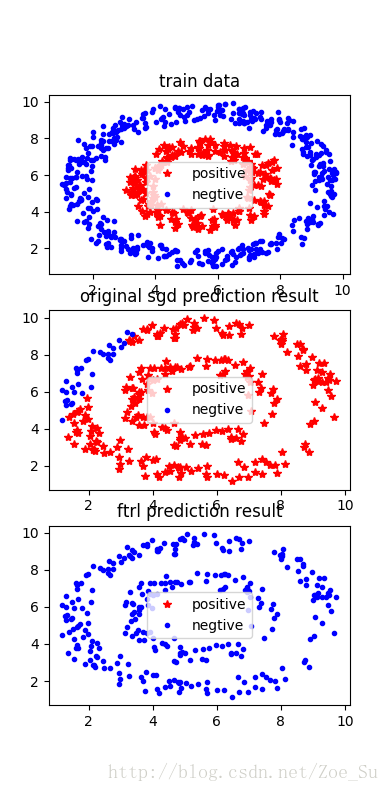
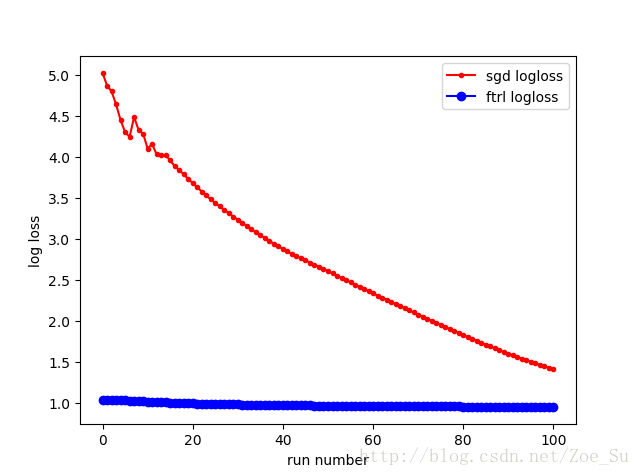
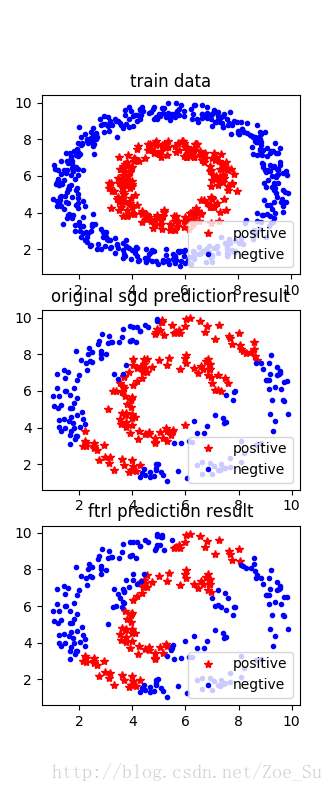
- k=2使用非线性数据集,采用SGD和FTRL两种训练方式,结果如下:

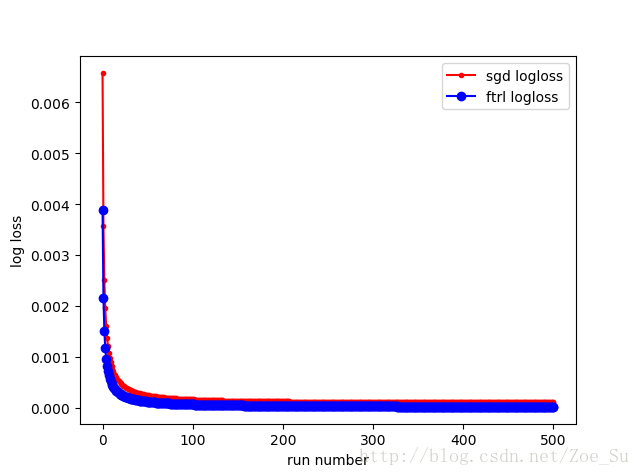
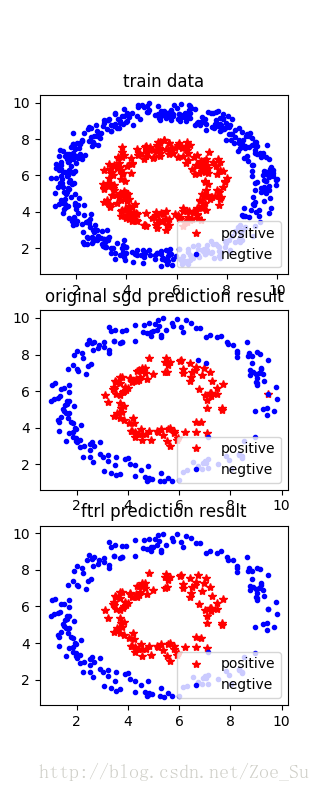
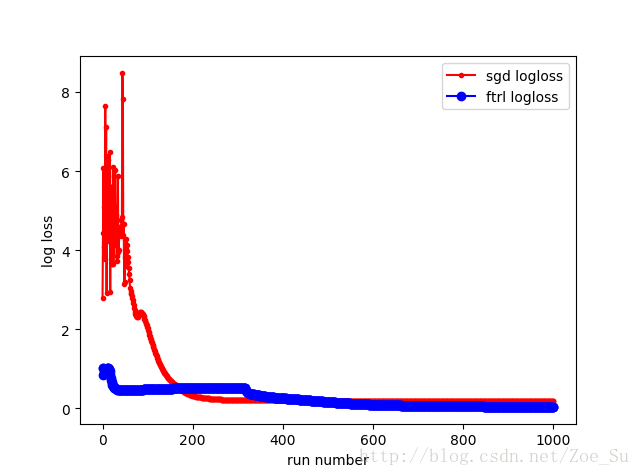
相同数据集不同k值:
- k=1:
- k=2:
- k=4:














 3537
3537











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









