










 本文深入介绍了谷歌推荐系统中的Multi-gate Mixture-of-Experts (MMoE) 模型,该模型用于多目标排序。MMoE包含多个专家神经网络,通过门函数(gate)结合权重输出,解决多任务预测问题。然而,实践中发现MMoE可能存在极化现象,即某些专家权重接近0,导致模型失去融合优势。为解决这个问题,提出了使用dropout技术防止极化。文章强调了MMoE的实际应用效果因场景而异,并提供了系统学习推荐系统的资源和建议。
本文深入介绍了谷歌推荐系统中的Multi-gate Mixture-of-Experts (MMoE) 模型,该模型用于多目标排序。MMoE包含多个专家神经网络,通过门函数(gate)结合权重输出,解决多任务预测问题。然而,实践中发现MMoE可能存在极化现象,即某些专家权重接近0,导致模型失去融合优势。为解决这个问题,提出了使用dropout技术防止极化。文章强调了MMoE的实际应用效果因场景而异,并提供了系统学习推荐系统的资源和建议。
一文看懂推荐系统:排序02:Multi-gate Mixture-of-Experts (MMoE)
提示:最近系统性地学习推荐系统的课程。我们以小红书的场景为例,讲工业界的推荐系统。
我只讲工业界实际有用的技术。说实话,工业界的技术远远领先学术界,在公开渠道看到的书、论文跟工业界的实践有很大的gap,
看书学不到推荐系统的关键技术。
看书学不到推荐系统的关键技术。
看书学不到推荐系统的关键技术。
王树森娓娓道来**《小红书的推荐系统》**
GitHub资料连接:http://wangshusen.github.io/
B站视频合集:https://space.bilibili.com/1369507485/channel/seriesdetail?sid=2249610
基础知识:
【1】一文看懂推荐系统:概要01:推荐系统的基本概念
【2】一文看懂推荐系统:概要02:推荐系统的链路,从召回粗排,到精排,到重排,最终推荐展示给用户
【3】一文看懂推荐系统:召回01:基于物品的协同过滤(ItemCF),item-based Collaboration Filter的核心思想与推荐过程
【4】一文看懂推荐系统:召回02:Swing 模型,和itemCF很相似,区别在于计算相似度的方法不一样
【5】一文看懂推荐系统:召回03:基于用户的协同过滤(UserCF),要计算用户之间的相似度
【6】一文看懂推荐系统:召回04:离散特征处理,one-hot编码和embedding特征嵌入
【7】一文看懂推荐系统:召回05:矩阵补充、最近邻查找,工业界基本不用了,但是有助于理解双塔模型
【8】一文看懂推荐系统:召回06:双塔模型——模型结构、训练方法,召回模型是后期融合特征,排序模型是前期融合特征
【9】一文看懂推荐系统:召回07:双塔模型——正负样本的选择,召回的目的是区分感兴趣和不感兴趣的,精排是区分感兴趣和非常感兴趣的
【10】一文看懂推荐系统:召回08:双塔模型——线上服务需要离线存物品向量、模型更新分为全量更新和增量更新
【11】一文看懂推荐系统:召回09:地理位置召回、作者召回、缓存召回
【12】一文看懂推荐系统:排序01:多目标模型
提示:文章目录
文章目录
谷歌推荐模型:Multi-gate Mixture-of-Experts (MMoE)
之前我介绍过最简单的多目标排序模型,
这节介绍一种改进的模型,叫做multi gate mixture of experts,缩写是MMOE,
跟上节一样,模型的输入是一个向量,包含用户特征、物品特征、统计特征还有成型特征,
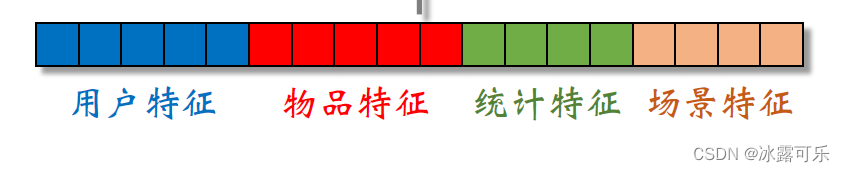
把向量输入三个神经网络。
这三个神经网络结构相同,都是有很多全连接层组成,
但这三个神经网络不共享参数,三个神经网络各输出一个向量,三个向量叫做X1X2X3。
这三个神经网络被叫做专家,就是mixture of experts中的experts。
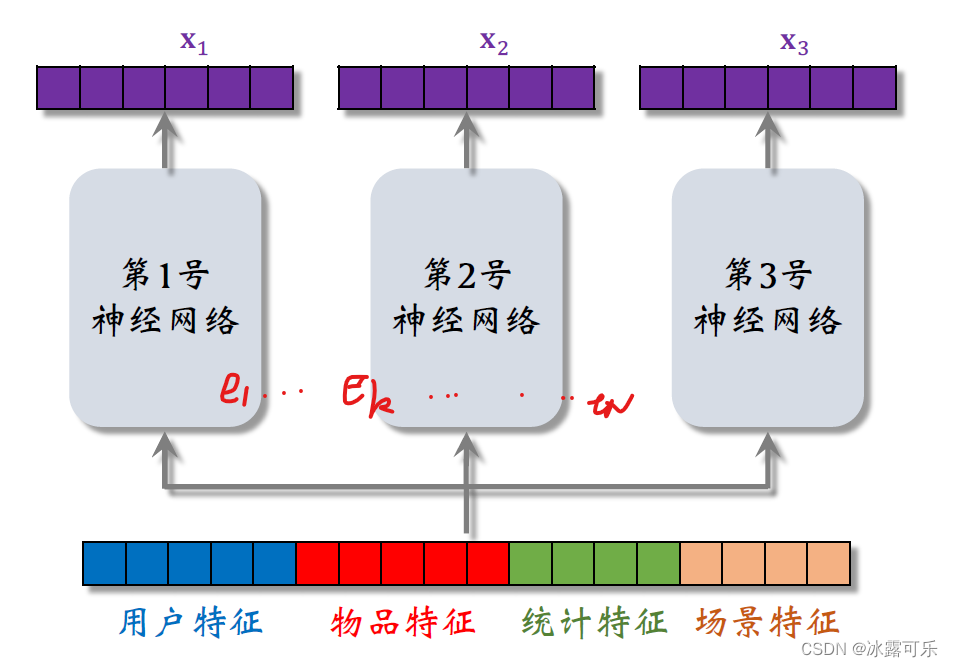
这里我是为了画图方便,用了三个专家神经网络。
实践中通常会试一试四个或者八个,
gate 门函数–权重输出
把下面的特征向量输入另一个神经网络,这个神经网络也有多个全连接层。
在神经网络的最后,加一个soft max激活函数突出一个三维的向量。
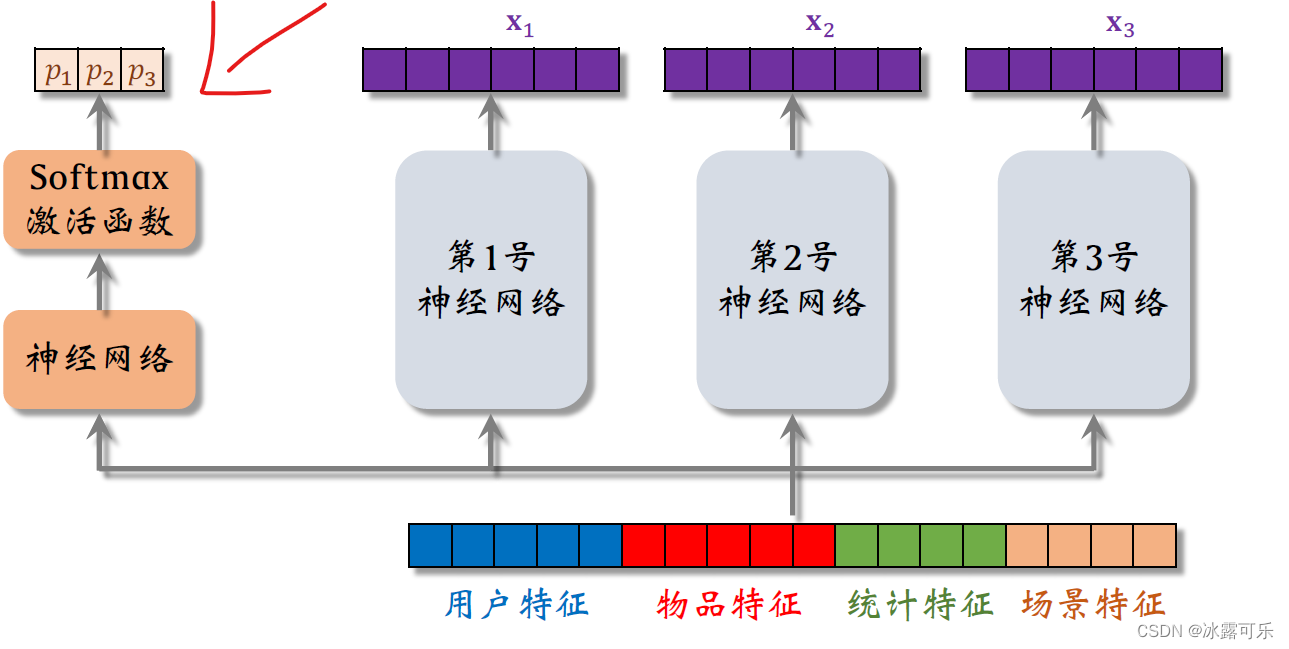
由于是soft max的输出向量的三个元素都大于零,而且相加等于一向量的三个元素,记作P1P2P3,
分别对应三个专家神经网络之后,
我们会用这三个元素作为权重,对向量X1 x2 X3做加权平均。
同样的方法把下面的特征向量送入右边的神经网络。
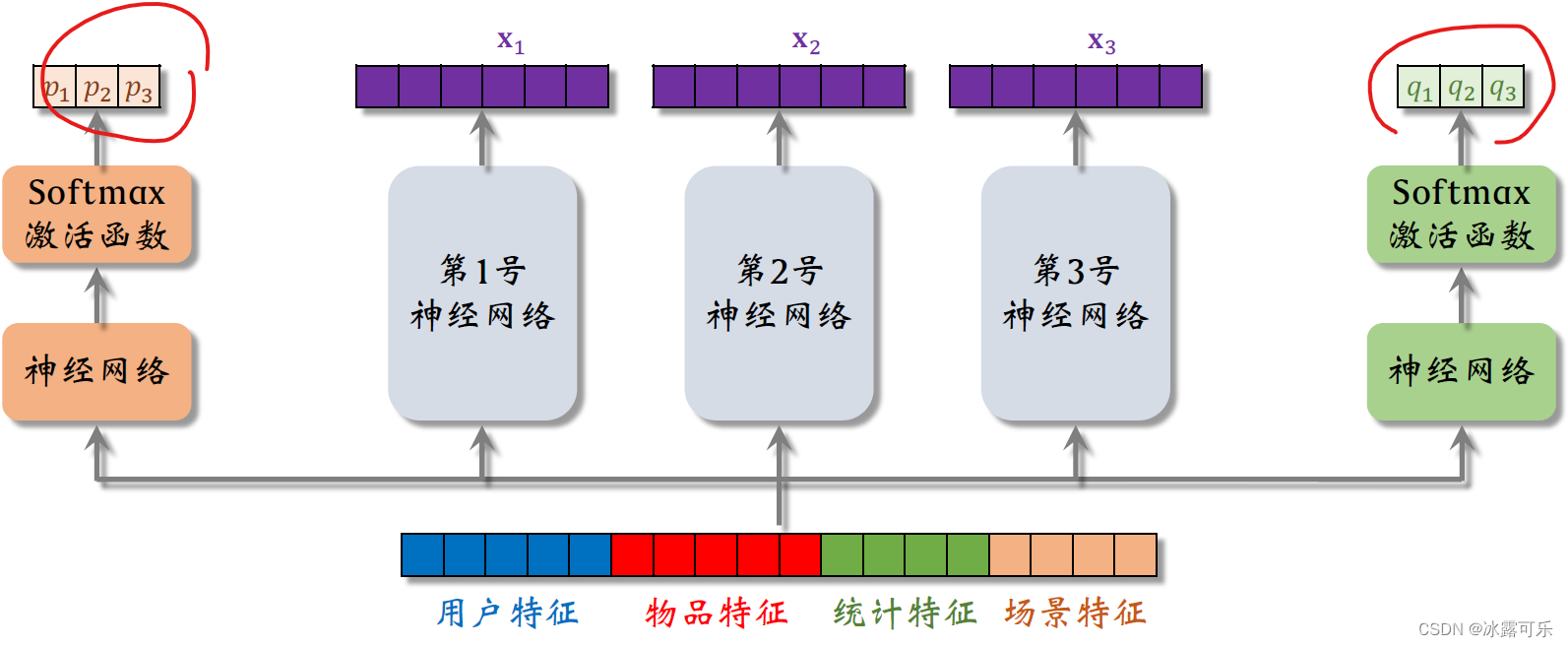
在神经网络的最后也是soft max结果函数,输出一个三维向量元素,分别记作Q1 Q2 Q3。
这三个元素,也是之后做加权平均时的权重,
接下来我们研究更上层的结构,刚才我说了P1P2 P3和Q1Q2Q三都是权重用于之后的加权平均,
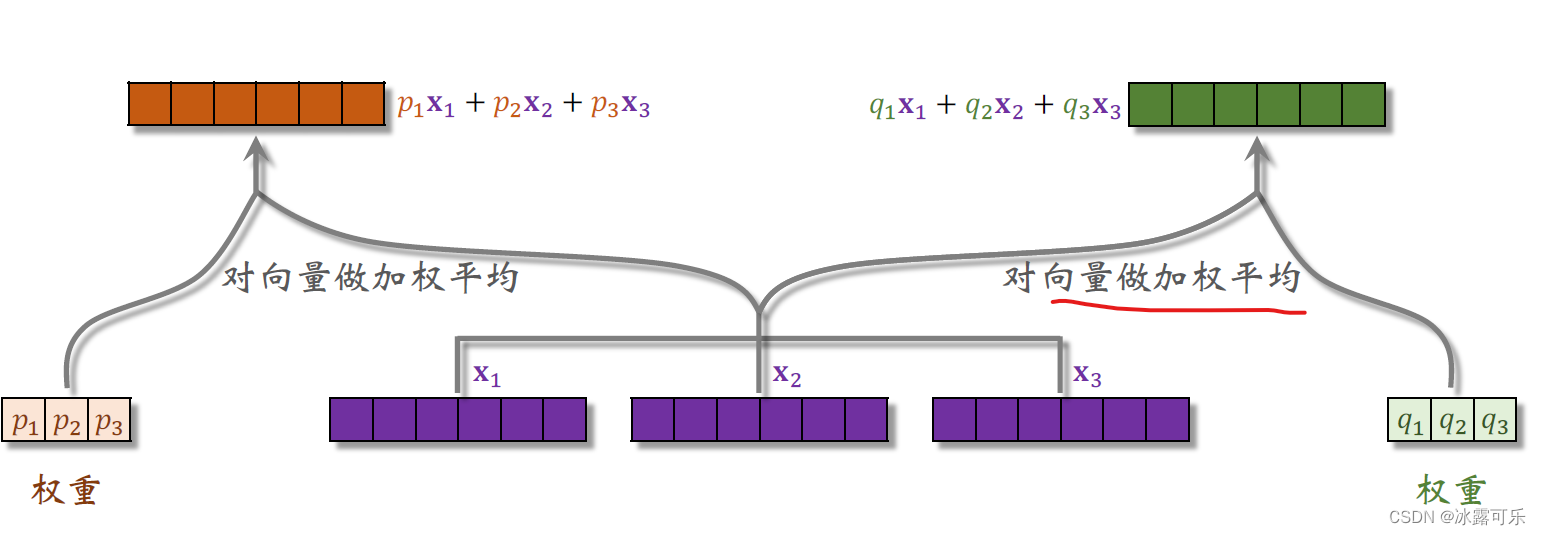
对向量X1X2X3做加权平均权重是P1P2 P3,得到上面的向量,它等于P1X1加P2X2加P3X3。
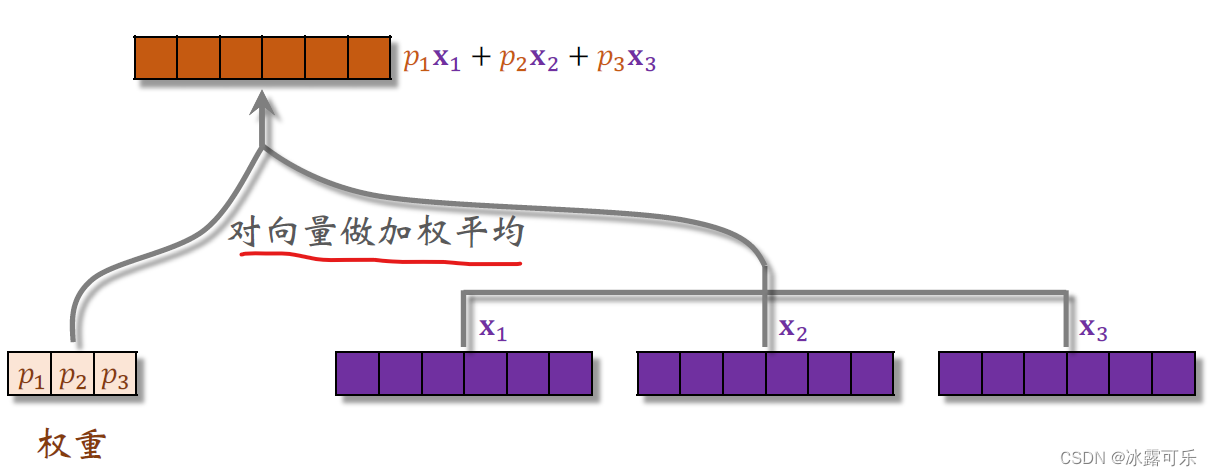
就是三个紫色向量的加权平均,
用右边的权重Q1Q2 Q3,对向量X1X2X3做加权平均得到右边的向量,它等于Q1X1加Q2X2加Q3X3,
它也是三个紫色向量的加权平均,
用左边还是右边的向量输出,取决于具体的任务,比如神经网络输出对点击率的是一个介于零到一之间的实数,
把右边的向量输入另一个神经网络,这个神经网络会输出另一个指标的预估,
比如对点赞率的预估也是介于零到一之间的实数。
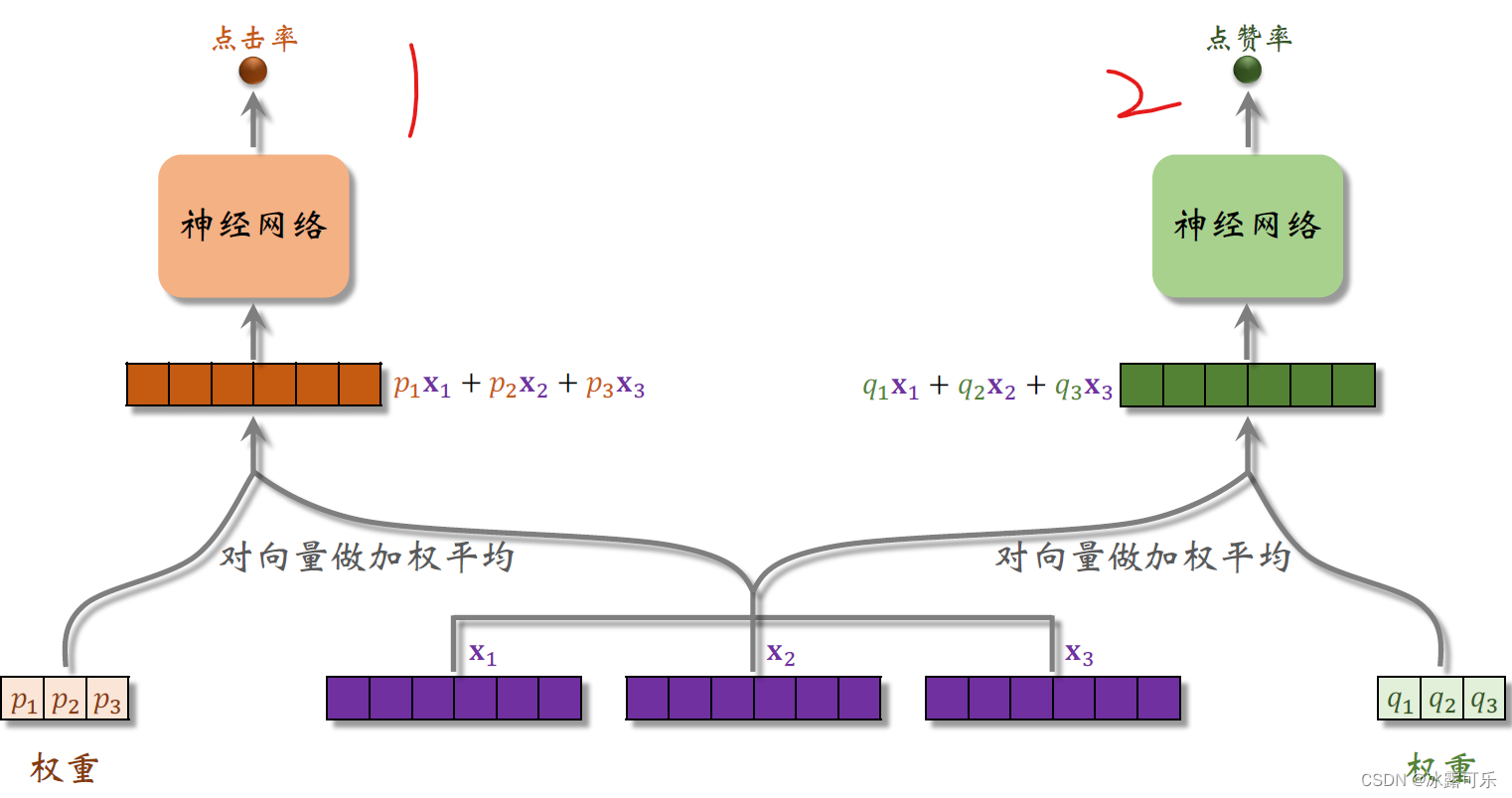
我这里假设多目标模型只有点击率和点赞率这两个目标,所以用了P和Q这两组权重,假如有十个目标,那么就要用十组权重。
到此为止,我已经讲完了MMOE的模型。
结构模型很简单,就是对神经网络输出的向量X1X2X3做加权平均,
然后用加权平均得到的向量去预估某个业务指标。
在这个例子中,需要预估点击率和点赞率这两个指标。
我用了三个专家,神经网络专家。
神经网络的数量是个超参数,需要手动调。
通常来说会试一试四个和八个。
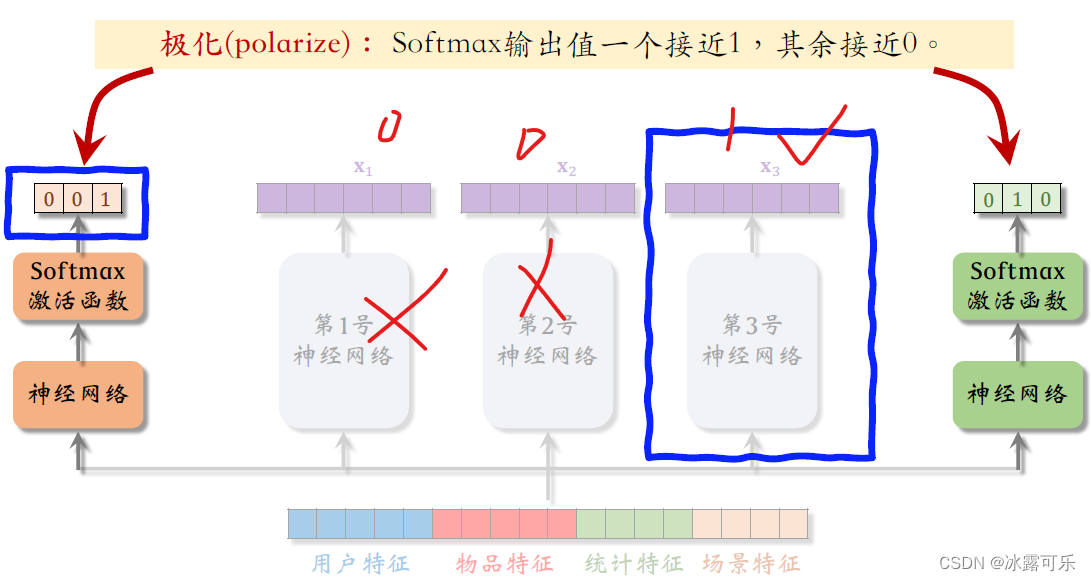
MMoE实践过程中发现有问题,被极化了,就是老是只有一个专家有效,权重是001的形式
在实践中,大家都发现MMOE有个问题。
就是soft max值约等于001,
比如:也就是说,左边的预估点击率任务只使用了第三号专家神经网络,而没有使用其他两个专家神经网络,
这样就等于没有用mix of experts,没有让三个专家神经网络的输出融合,而是简单使用了一个专家。
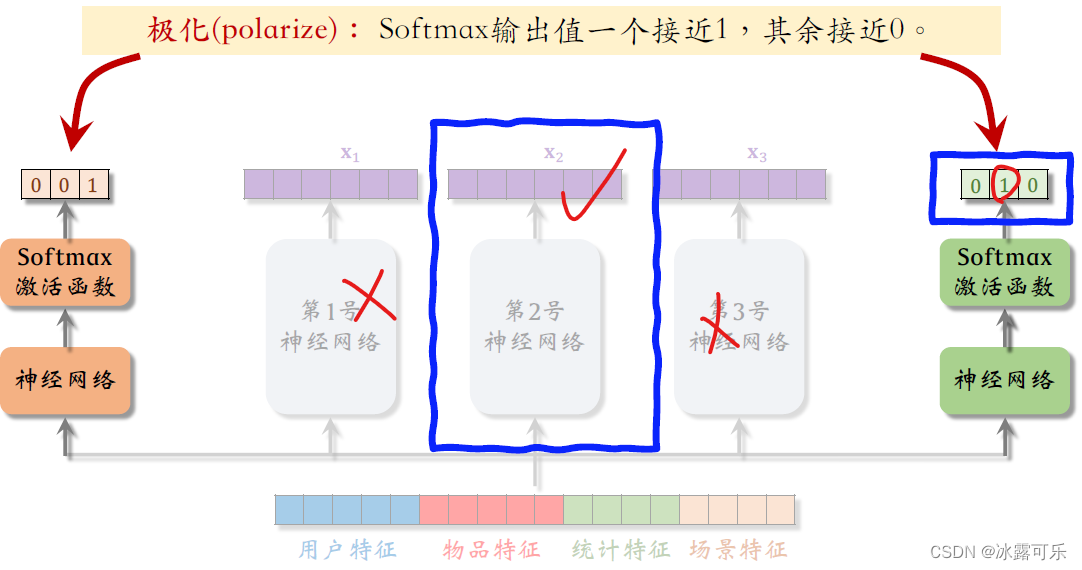
再看右边soft max的输出值接近010,
也就是说,右边的任务只使用了第二号专家神经网络,也没有对三个专家做融合,
整理合起来,就是:
两个任务分别使用了第二号和第三号专家神经网络。
这样的话,第一号专家神经网络就相当于死掉了,不会被用到。
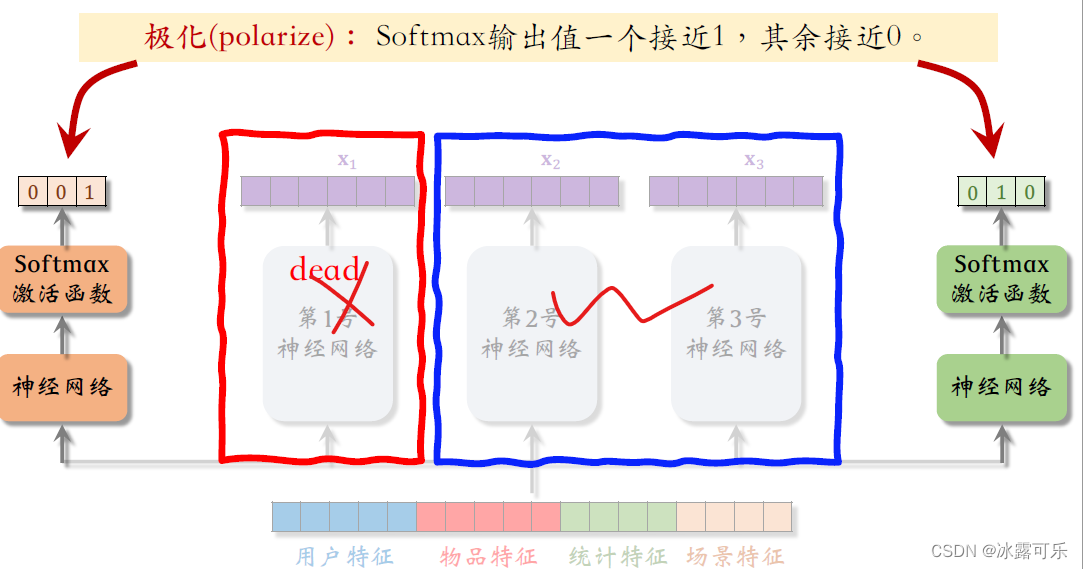
那么MMOE就相当于一个简单的多目标模型,不会对专家做融合,失去了MMOE的优势。
我们不希望这种现象出现,当然是有办法进行去极化现象的。
如果有N个专家神经网络,那么每个softmax结果函数的输入和输出都是N维向量。

我们不希望看到其中一个输出的元素接近1,其余N减一个元素接近零。
解决极化现象的一种方法是dropout
在训练的过程中被soft max输出使用dropout
soft max输出的N个数值被mark的概率都是10%,
也就是说在训练的过程中,每个专家被丢弃的概率都是10%,
这样会强迫每个任务根据部分专家做预测,
如果用dropout不太可能会发生极化,否则预测的结果会特别差。
假如发生极化soft max输出的某个元素接近11000,这个元素被mask预测的结果肯定会错的离谱。
为了让预测尽量精准,神经网络会尽量避免极化的发生
,避免soft max输出的某个元素接近1
用了Dropout基本上能避免发生极化。
下面列了两篇参考文献,第一篇是Google的他们。

提出了MMOE模型,第二篇论文是Youtube的,他们俩一家的,
最开始Google提出了mmoe,而YouTube提出了这个解决方案。
最后提一句,不要以为把MMOE用上就一定会有提升。
我跟很多算法工程师聊过,有人用MMOE之后有提升,
有人用了之后就没有MMOE没效果的
原因不清楚,可能是实现不够好,也有可能是不适用于特定的业务场景。
如果你们公司没有用MMOE,很可能是尝试之后发现没有提升。
总结
提示:如何系统地学习推荐系统,本系列文章可以帮到你
(1)找工作投简历的话,你要将招聘单位的岗位需求和你的研究方向和工作内容对应起来,这样才能契合公司招聘需求,否则它直接把简历给你挂了
(2)你到底是要进公司做推荐系统方向?还是纯cv方向?还是NLP方向?还是语音方向?还是深度学习机器学习技术中台?还是硬件?还是前端开发?后端开发?测试开发?产品?人力?行政?这些你不可能啥都会,你需要找准一个方向,自己有积累,才能去投递,否则面试官跟你聊什么呢?
(3)今日推荐系统学习经验:如果你们公司没有用MMOE,很可能是尝试之后发现没有提升。


















 1745
1745

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











