






主成分分析法(Principal Component Analysis)大多在数据维度比较高的时候,用来减少数据维度,因而加快模型训练速度。另外也有些用途,比如图片压缩(主要是用SVD,也可以用PCA来做)、因子分析等。具体怎么用,看个人需求如何,这篇文章主要解释一下PCA的原理。当然应用起来也非常简单,现在常用的语言,python、R、matlab都有直接求解PCA或者SVD的包了。
这篇文章主要想讲讲PCA的思想,当然有很多看官并不在乎这个算法的思想是什么,而仅仅急切地想要实现它,在文章最后,我们给出了R语言的实现方法,想看实现方法的可以直接跳到文章最后。
下面我们看看PCA具体做了些什么。
我们有一组数据
X
X
X,维度是m x n,表示有 n个样本,每个样本有m个特征,即:
X
=
[
x
1
,
1
x
1
,
2
⋯
x
1
,
n
x
2
,
1
x
2
,
2
⋯
x
2
,
n
⋮
⋮
⋱
⋮
x
m
,
1
x
m
,
2
⋯
x
m
,
n
]
X=\left[ \begin{matrix} x_{1,1} & x_{1,2} & \cdots & x_{1,n} \\ x_{2,1} & x_{2,2} & \cdots & x_{2,n} \\ \vdots & \vdots & \ddots & \vdots \\ x_{m,1} & x_{m,2} & \cdots & x_{m,n} \\ \end{matrix} \right]
X=⎣⎢⎢⎢⎡x1,1x2,1⋮xm,1x1,2x2,2⋮xm,2⋯⋯⋱⋯x1,nx2,n⋮xm,n⎦⎥⎥⎥⎤
现在我们想知道这个数据具体包含了哪些信息,这里可能需要引入一个大家都很熟悉的概念,方差。让我们先看其中某一维的数据,例如:
x
1
=
[
x
1
,
1
,
x
1
,
2
,
⋯
 
,
x
1
,
n
]
x_1=\left[x_{1,1},x_{1,2},\cdots,x_{1,n}\right]
x1=[x1,1,x1,2,⋯,x1,n]。如果说
x
1
x_1
x1其中每一项都相等,也就是每一项都等于一个常数,那么我们认为
x
1
x_1
x1并没有包含什么信息,因为它 就是一个已知的常数。所以,我们想要某一维的数据越多样性越好,这样它可以包含更多的信息,我们可以据此做出更多的推断。笼统来说,我们可以用方差来表示数据的多样性。
PCA对数据的分布其实是有一个假设的,即每一个维度上的数据都服从Gaussian分布。假设 x 1 x_1 x1平均值是 x 1 ‾ \overline{x_1} x1、方差是 σ 1 2 \sigma_1^2 σ12,令 x 1 = [ x 1 , 1 − x 1 ‾ σ 1 , ⋯   , x 1 , n − x 1 ‾ σ 1 ] x_1=\left[\frac{x_{1,1}-\overline{x_1}}{\sigma_1},\cdots,\frac{x_{1,n}-\overline{x_1}}{\sigma_1}\right] x1=[σ1x1,1−x1,⋯,σ1x1,n−x1],这样 x 1 x_1 x1就服从均值为0,方差为1的高斯分布。后面我们默认X的每一个维度都服从均值为0,方差为1 的高斯分布,即每一个维度上的数据方差都为1。这样处理过后,似乎每一个维度上的数据都包含等量的信息。
然而真实情况好像并不是这样,我们会发现有些特征能给我们带来更大的帮助,往往某一个或者两个特征能对模型产生重要的影响,而继续增加更多特征,也只会使模型在小幅度内提升。这说明有些特征能够给我们带来更多的信息,这是怎么回事呢?下面,我们来看另一个定义,协方差。
协方差是来反映数据间的相关性。有两组数据,他们的关系如下图:
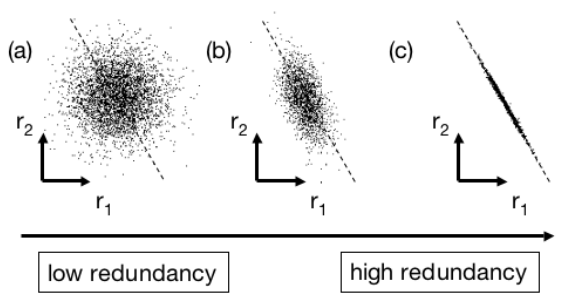
(注:上图引用某篇博客,忘记出处了,若有侵权请告知)
如果如图(a),则说明两组数据相关性低(或者说low redundancy);如果如图(c),则说明两组数据的相关性高,也就是high redundancy,因为我们基本上可以认为
r
2
=
k
∗
r
1
r_2=k*r_1
r2=k∗r1,也就是
r
2
r_2
r2其实是多余的。
x
1
=
[
x
1
,
1
,
x
1
,
2
,
⋯
 
,
x
1
,
n
]
x_1=\left[x_{1,1},x_{1,2},\cdots,x_{1,n}\right]
x1=[x1,1,x1,2,⋯,x1,n],
x
2
=
[
x
2
,
1
,
x
2
,
2
,
⋯
 
,
x
2
,
n
]
x_2=\left[x_{2,1},x_{2,2},\cdots,x_{2,n}\right]
x2=[x2,1,x2,2,⋯,x2,n]是服从均值为0,方差为1 的高斯分布的两组数据。我们知道方差的定义:
σ
1
2
=
1
n
−
1
∑
i
=
1
n
(
x
1
,
i
−
x
1
‾
)
2
,
σ
2
2
=
1
n
−
1
∑
i
=
1
n
(
x
2
,
i
−
x
2
‾
)
2
\sigma_1^2=\frac1{n-1}\sum_{i=1}^n(x_{1,i}-\overline{x_1})^2,\sigma_2^2=\frac1{n-1}\sum_{i=1}^n(x_{2,i}-\overline{x_2})^2
σ12=n−11i=1∑n(x1,i−x1)2,σ22=n−11i=1∑n(x2,i−x2)2
我们现在定义数据
x
1
x_1
x1和
x
2
x_2
x2的协方差:
σ
1
,
2
2
=
1
n
−
1
∑
i
=
1
n
(
x
1
,
i
−
x
1
‾
)
(
x
2
,
i
−
x
2
‾
)
\sigma_{1,2}^2=\frac1{n-1}\sum_{i=1}^n(x_{1,i}-\overline{x_1})(x_{2,i}-\overline{x_2})
σ1,22=n−11i=1∑n(x1,i−x1)(x2,i−x2)
协方差有两个性质: 1)当且仅当
x
1
x_1
x1和
x
2
x_2
x2完全不相关时,
σ
1
,
2
2
=
0
\sigma_{1,2}^2=0
σ1,22=0;2)如果
x
1
=
x
2
x_1=x_2
x1=x2,那么
σ
1
,
2
2
=
σ
1
2
\sigma_{1,2}^2=\sigma_1^2
σ1,22=σ12。
现在,让我们看一个矩阵
X
X
T
XX^T
XXT,实际上它是一个表示各维度之间方差的对称方阵,
σ
1
,
2
2
=
σ
2
,
1
2
\sigma_{1,2}^2=\sigma_{2,1}^2
σ1,22=σ2,12,也可以叫做协方差矩阵。
X
X
X的维度是
m
×
n
m\times n
m×n,
X
T
X^T
XT的维度是
n
×
m
n\times m
n×m,那么
X
X
T
XX^T
XXT的维度则是
m
×
m
m\times m
m×m,即:
X
X
T
=
[
σ
1
,
1
2
σ
1
,
2
2
⋯
σ
1
,
n
2
σ
2
,
1
2
σ
2
,
2
2
⋯
σ
2
,
n
2
⋮
⋮
⋱
⋮
σ
m
,
1
2
σ
m
,
2
2
⋯
σ
m
,
n
2
]
XX^T= \left[ \begin{matrix} \sigma_{1,1}^2 & \sigma_{1,2}^2 & \cdots & \sigma_{1,n}^2 \\ \sigma_{2,1}^2 & \sigma_{2,2}^2 & \cdots & \sigma_{2,n}^2 \\ \vdots & \vdots & \ddots & \vdots \\ \sigma_{m,1}^2 & \sigma_{m,2}^2 & \cdots & \sigma_{m,n}^2 \\ \end{matrix} \right]
XXT=⎣⎢⎢⎢⎡σ1,12σ2,12⋮σm,12σ1,22σ2,22⋮σm,22⋯⋯⋱⋯σ1,n2σ2,n2⋮σm,n2⎦⎥⎥⎥⎤
假设我们有一个矩阵
3
×
4
3\times4
3×4的矩阵
A
A
A:
A
=
[
0.360
0.210
−
0.86
0.29
−
0.60
−
0.20
0.80
0.00
−
0.21
0.72
0.14
−
0.65
]
A=\left[ \begin{matrix} 0.360 & 0.210 & -0.86 & 0.29 \\ -0.60 & -0.20 & 0.80 & 0.00 \\ -0.21 & 0.72 & 0.14 & -0.65 \\ \end{matrix} \right]
A=⎣⎡0.360−0.60−0.210.210−0.200.72−0.860.800.140.290.00−0.65⎦⎤
我们可以得到矩阵
A
A
T
AA^T
AAT:
A
A
T
=
[
1.00
−
0.95
−
0.23
−
0.95
1.00
−
0.094
−
0.23
−
0.094
1.00
]
AA^T=\left[ \begin{matrix} 1.00 & -0.95 & -0.23 \\ -0.95 & 1.00 & -0.094 \\ -0.23 & -0.094 & 1.00 \\ \end{matrix} \right]
AAT=⎣⎡1.00−0.95−0.23−0.951.00−0.094−0.23−0.0941.00⎦⎤
可以看到
A
A
T
AA^T
AAT是一个对称的矩阵,且每一个维度与自己的方差为1,而与其它维度的协方差则各不相同。也就是说每一个维度不仅表达了自身,这个维度所带有的信息,还表达了与其它维度的部分信息。这也就能解释,虽然每个维度的方差都为1,但是它们所包含的真实信息量是不同的。
然而,假如我们得到一个
A
A
T
AA^T
AAT的矩阵:
A
A
T
=
[
0.59
0
0
0
0.29
0
0
0
0.12
]
AA^T=\left[ \begin{matrix} 0.59 & 0 & 0 \\ 0 & 0.29 & 0 \\ 0 & 0 & 0.12 \\ \end{matrix} \right]
AAT=⎣⎡0.590000.290000.12⎦⎤
也就是说,各个维度是完全独立的,维度与维度之间的相关性为0。这样每个维度就只包含了自己的信息,我们现在就可以说第一个维度包含了矩阵
A
A
A 59%(0.59/(0.59 + 0.29 + 0.12))的信息,第二个维度包含了29%的信息,第三个维度包含了12%的信息。
这是不是给了你一个启发,要是我能有一个数据(矩阵),它的每一个维度都是完全独立的,那么我计算出每个维度的方差,取方差最大的几个,这样我就可以用很少的几个维度,包含整个数据大部分的信息。比如上面那个例子,我用前面两个维度,就可以包含所有数据88%的信息。
这就是PCA的基本思想。然而现实中,并不是遇到的每个数据集合,它各个维度之间的方差均为0。实际上,基本上不可能存在这样的数据集合。我们收集到的数据之间或多或少都会存在关联。例如我们要预测一个人是否会发生购买行为,我们会看他浏览了了多少商品,收藏了多少商品,然而浏览与收藏之间肯定是有联系的。那么如何实现PCA呢。
矩阵当中有一个非常著名的理论,一个 n × n n\times n n×n的对称矩阵 A A A可以表示为: A = V D V T A=VDV^T A=VDVT。其中, V V V是一个正交矩阵, D D D是一个对角矩阵,除了对角线上的值可能不为0以外,其它的值均为0。
根据上面理论,对于任意一个
m
×
n
m\times n
m×n的矩阵
A
A
A,
A
A
T
AA^T
AAT是一个
m
×
m
m\times m
m×m的对称矩阵,因而对矩阵
A
A
T
AA^T
AAT有:
A
A
T
=
V
D
V
T
AA^T=VDV^T
AAT=VDVT,那么
V
T
A
(
V
T
A
)
T
=
V
T
A
A
T
V
=
V
T
(
V
D
V
T
)
V
=
D
V^TA(V^TA)^T=V^TAA^TV=V^T(VDV^T)V=D
VTA(VTA)T=VTAATV=VT(VDVT)V=D,因为
V
V
V是一个正交矩阵,
V
V
T
=
I
VV^T=I
VVT=I。也就是对于任意一个
m
×
n
m\times n
m×n的矩阵
A
A
A,我们可以找到一个
m
×
m
m\times m
m×m的正交矩阵
V
V
V,使得矩阵
V
T
A
V^T A
VTA的方差矩阵
V
T
A
(
V
T
A
)
T
V^TA(V^TA)^T
VTA(VTA)T,只有对角线上的值不为0,即矩阵各个维度之间相互独立。
D
=
[
σ
1
0
0
0
σ
2
0
0
0
⋱
]
D=\left[ \begin{matrix} \sigma_1 & 0 & 0 \\ 0 & \sigma_2 & 0 \\ 0 & 0 & \ddots \\ \end{matrix} \right]
D=⎣⎡σ1000σ2000⋱⎦⎤
以上,PCA的思想就介绍完了。但是
V
T
A
V^TA
VTA具体是做了什么事情呢?它对矩阵
A
A
A又有什么影响?让我们来看一下
V
V
V是一个什么样子的矩阵。
根据这个定理 A A T = V D V T AA^T=VDV^T AAT=VDVT,实际上 V V V是矩阵 A A T AA^T AAT中所有的特征向量构成的一个矩阵,不过这里我们并不考虑V是如何求来的。如何求得,不过是线性代数里面的一些知识。
这里我们关心的是, V V V是一个 m × m m\times m m×m的矩阵,所以 V T A V^TA VTA是一个 m × n m\times n m×n的矩阵。如果我们在的 V T A V^TA VTA左边乘上 ( V T ) − 1 (V^T)^{-1} (VT)−1,矩阵又会变回 A A A,也就是 ( V T ) − 1 V T A = A (V^T)^{-1} V^TA=A (VT)−1VTA=A。所以,实际上用 V V V的转置乘上 A A A,只是对 A A A做了一些行列上的变换,并没有减少任何信息,如果我们想要,我们还可以把 A A A变回来。
这样,我们完全可以由变换后的矩阵 V T A V^TA VTA,来表示原来的数据 A A A,且不会有任何信息损失。而且,转换后的矩阵有一个非常好的性质,就是各个维度之间相互独立,所以我们可以得到它的协方差矩阵 V T A ( V T A ) T = D V^TA(V^TA)^T=D VTA(VTA)T=D,是一个只有对角线上元素不为0的对角矩阵。
这样,我们就可以知道每一个维度分别包含了多少信息。假如数据的维度m,是一个非常大的值,例如10,0000,如果我们发现仅仅使用前10个维度,就能包含95%以上的信息,那么我们将很高兴用这10个维度,而舍弃掉剩下的其它维度,这相当于将数据压缩了10000倍,而并没有损失多少信息。当然这只是我们的臆想,实际情况不一定有这么好。
R实现:
#从R内置数据集iris中取前10行,这里数据和文中的例子正好相反,每一行是代表一个样本,每一列代表一个维度
> A <- as.matrix(iris[1:10,-5])
> A
Sepal.Length Sepal.Width Petal.Length Petal.Width
1 5.1 3.5 1.4 0.2
2 4.9 3.0 1.4 0.2
3 4.7 3.2 1.3 0.2
4 4.6 3.1 1.5 0.2
5 5.0 3.6 1.4 0.2
6 5.4 3.9 1.7 0.4
7 4.6 3.4 1.4 0.3
8 5.0 3.4 1.5 0.2
9 4.4 2.9 1.4 0.2
10 4.9 3.1 1.5 0.1
#可以看到A是一个10x4的矩阵,下面我们对A进行标准化
> A <- scale(A)
> A
Sepal.Length Sepal.Width Petal.Length Petal.Width
1 0.8237318 0.6186158 -0.46291 -0.2535463
2 0.1372886 -1.0093205 -0.46291 -0.2535463
3 -0.5491545 -0.3581460 -1.38873 -0.2535463
4 -0.8923761 -0.6837333 0.46291 -0.2535463
5 0.4805102 0.9442031 -0.46291 -0.2535463
6 1.8533965 1.9209649 2.31455 2.2819165
7 -0.8923761 0.2930285 -0.46291 1.0141851
8 0.4805102 0.2930285 0.46291 -0.2535463
9 -1.5788192 -1.3349078 -0.46291 -0.2535463
10 0.1372886 -0.6837333 0.46291 -1.5212777
#未对其进行转化前A的协方差矩阵如下,对角线上的值均为1,而协方差各异,
#因而不好估量每个维度所包含的信息
> var(A)
Sepal.Length Sepal.Width Petal.Length Petal.Width
Sepal.Length 1.0000000 0.7872066 0.6002160 0.3770977
Sepal.Width 0.7872066 1.0000000 0.5191385 0.6787563
Petal.Length 0.6002160 0.5191385 1.0000000 0.5216405
Petal.Width 0.3770977 0.6787563 0.5216405 1.0000000
#利用内置svd函数队矩阵t(A)进行分解,t(A)即A的转置,转置后变成4x10的矩阵,
#与文中一致。其中,得到的矩阵s$u即为文中的矩阵V
> s <- svd(t(A))
> s$u
[,1] [,2] [,3] [,4]
[1,] -0.5088012 0.60992283 -0.19490104 -0.5754381
[2,] -0.5486817 0.02313419 -0.49127967 0.6760603
[3,] -0.4747485 0.08790411 0.84594304 0.2264225
[4,] -0.4633397 -0.78723048 -0.07098059 -0.4006822
#利用t(V)%*%t(A)原矩阵进行转换,再看一下转换后矩阵的协方差矩阵,这里保留两位小数
> AA <- t(s$u) %*% t(A)
> round(var(t(AA)), 2)
[,1] [,2] [,3] [,4]
[1,] 2.75 0.00 0.00 0.0
[2,] 0.00 0.63 0.00 0.0
[3,] 0.00 0.00 0.52 0.0
[4,] 0.00 0.00 0.00 0.1
#可以看到,转换后矩阵各维度之间相互独立,并且可以知道每个矩阵包含了多少信息。
#假如我们取前三个纬度,则可以包含97.5%的信息,(2.75+0.63+0.53)/( 2.75+0.63+0.53+0.1)=0.975。
这里我们使用R中内置的函数SVD,来实现PCA的算法。实际情况中,我们常常可以看到SVD和批PCA在一起被提到,它们之间又有什么关系。感兴趣的话,可以看看我的下一篇blog:SVD与PCA详解。

















 1442
1442

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









