







 本文是PRML读书笔记的第一部分,介绍机器学习的基础概念,如训练集、学习过程、预处理、监督学习和非监督学习。通过多项式拟合的例子,探讨了模型的生成能力、过拟合及其解决方案,如正则化,并从概率、决策和信息论三个角度理解模型选择和优化问题。
本文是PRML读书笔记的第一部分,介绍机器学习的基础概念,如训练集、学习过程、预处理、监督学习和非监督学习。通过多项式拟合的例子,探讨了模型的生成能力、过拟合及其解决方案,如正则化,并从概率、决策和信息论三个角度理解模型选择和优化问题。
打算去读PRML这本书,用两遍来读完,第一遍弄懂基本思想,以便看其他任何相关文献能够明白他们在说什么;第二遍细看,重点要做书后面的习题,弄清每个知识点的细节部分。第二遍可能不会连续,甚至会挑选部分章节重点研究,但是第一遍需要坚持。近期的博文就是记录自己看到的关键知识概念,到时碰到不懂的时候,再去google查找进一步的解析。行文都依照原作者书中介绍的顺序,希望这些概念能够将整体知识串接起来……
------------------分割线----------------------
训练集(training set):用来训练模型的观察数据{
 },有的时候会带上目标向量
},有的时候会带上目标向量
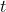 ;
;
训练(training)或者学习(learning):寻找一个最优函数
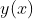 ,使其能够与
尽可能接近。
,使其能够与
尽可能接近。
有时需要对数据进行预处理(preprocessed),比如一幅图像有很多像素点组成,我们不需要将这些数据全部输入模型,而是先进行一个特征提取的工作(feature extraction),这是计算机视觉领域一个很重要的工作。同样,新的需要被预测的数据也要进行同样的预处理工作。
当训练好一个模型后,这个模型预测新的数据的能力就称为生成能力(generalization),当
为离散值的时候,称为分类问题(classification),如果是连续值,就是回归问题(regression)。在训练学习过程中,有
值就称为监督学习(supervised learning),如果没有就是非监督学习(unsupervised learning),前面提到的分类、回归问题就属于监督学习范畴,非监督学习包括聚类(clustering)、数据概率分布估计(density estimation)等。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 2060
2060

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









