






泛型算法總共把它分為四個部分,分別是:1.非變異算法2.變異算法3.排序4.泛型數值算法
因為這些都是算法,而算法是無窮盡的,因為算法是依照你的需求就可以造出你所要的計算方式,所以沒有辦法做大的講解,所以就把每個部份的定義寫出,然後在帶一個例子說明
(一)非變異算法
非變異算法就是在計算過程中,不改變容器內的數據與數值,就是說在放入算法前與算法後他的數據都是不會變的,所以就叫非變異算法,比如說:查找,排序,統計等
for_each,count,find,find_if等
find:
<span style="font-size:18px;"><span style="font-size:18px;"><span style="font-size:18px;"><span style="font-size:18px;">template<class _Init,class _Ty>inline
_Ty for_each(_Init _First,_Init _Last,const _Ty& _Val)
{
......................
}
int element[]={1,2,3,4,5,6};
std::vector<int> v(element,element+6);
std::vector<int>::iterator it=std::find(v.begin(),v.end(),9);
if(it!=v.end())
{
cout<<"you find";
}</span></span></span></span>(二)變異算法
非變異算法就是在計算過程中,會改變容器內的數據與數值,就是說在放入算法前與算法後他的數據是會變的,所以就叫變異算法,比如說:copy,trasform,unique,replace等
copy
<span style="font-size:18px;"><span style="font-size:18px;"><span style="font-size:18px;"><span style="font-size:18px;">template<class _Init,class _Outit>inline
_Outit copy(_Init _First,_Init _Last,_Outit _Dest)
{
..................
}
int element[]={1,2,3,4,5,6};
std::vector<int> v(element,element+6);
std::vector<int> v2(v.size());
std::copy(v.begin(),v,end(),v2.begin());
std::copy(v2.begin()+2,v2.end(),v2.begin());</span></span></span></span>copy是將對象從[_First,_Last)copy至[_Dest,_DestLast),其中_DestLast=_Dest+(_Last-_First),按順序copy:_First,_First+1,......
copy原本是做本身的容器中的數據是不改變的,但是我是將他的copy的目的地設地在自己身上的話,就會出現數據一位的現象,我們就如代碼中的最後一行就是把數據左移兩個位置
copy_back
<span style="font-size:18px;"><span style="font-size:18px;"><span style="font-size:18px;"><span style="font-size:18px;">template<class _Init1,class Init2>inline
_Outit copy_back(_Init1 _First,_Init1 _Last,_Init2 _Dest)
{
..................
}
int element[]={1,2,3,4,5,6};
std::vector<int> v(element,element+6);
std::copy_back(v.begin(),v.end()-2,v.end())</span></span></span></span>在上述代碼中,把容器對象左移兩個單位,但是雖然是右移了,最做邊的兩的單位還是沒有消失,依然是不變的,因為這是複製,而不是取出
(三)排序
(1)一般排序
排序,有點像是容器中的默認仿函數,因為它實際上不是仿函數,他是一種算法,是他一個容器中的數據進行排序
<span style="font-size:18px;"><span style="font-size:18px;"><span style="font-size:18px;">template<class _Ranit>inline
void sort(_Ranit _First,_Ranit _Last)
{
............
}
int element[]={1,5,68,4,8,2};
std::vector<int> v(element,element+6);
std::sort(v.begin(),v.end());</span></span></span>(2)基於排序集合的算法
基於排序集合的這種算法,我理解為她把兩個容器數據做一個集合式的比較,是一個整體的數據比較,而不像是一個一個數據比較,下面利用include解釋:
<span style="font-size:18px;"><span style="font-size:18px;"><span style="font-size:18px;">template<class _Init1,class _Init2>inline
bool include(_Init1 _First1,_Init1 _Last,_Init2 _First2,_Init2 _Last2)
{
...............
}
int element1[]={1,2,3,4,5,6,7}; std::vector<int> v1(element,element);
int element2[]={1,4,7}; std::vector<int> v2(element,element);
int element3[]={2,7,9}; std::vector<int> v3(element,element);
int element4[]={1,1,2,3,5,8,13,21};std::vector<int> v4(element,element);
int element5[]={1,2,13,13}; std::vector<int> v5(element,element);
int element6[]={1,1,3,21}; std::vector<int> v6(element,element);</span></span></span><span style="font-size:18px;"><span style="font-size:18px;"><span style="font-size:18px;">std::include(v1.begin(),v1.end(),v2.begin(),v2.end());//true</span></span></span>

<span style="font-size:18px;"><span style="font-size:18px;"><span style="font-size:18px;">std::include(v4.begin(),v4.end(),v5.begin(),v5.end());//false</span></span></span>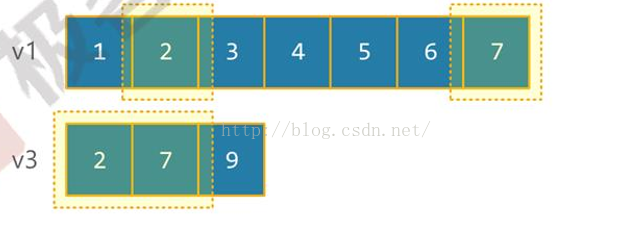
<span style="font-size:18px;"><span style="font-size:18px;"><span style="font-size:18px;">std::include(v1.begin(),v1.end(),v3.begin(),v3.end());//false</span></span></span>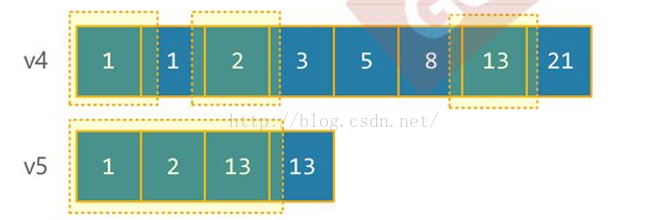
<span style="font-size:18px;"><span style="font-size:18px;"><span style="font-size:18px;">std::include(v4.begin(),v4.end(),v6.begin(),v6.end());//true</span></span></span>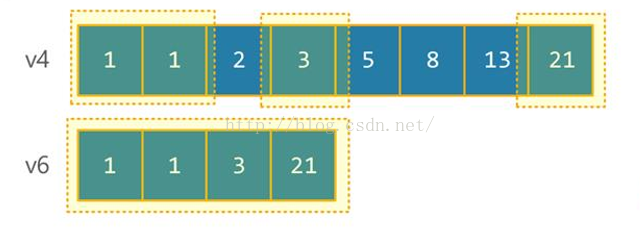
我們可以看到在這五個試驗代碼中,以及他們的示意圖,我們可以知道他是把整個容器的數據都拿來做算法運算,也就是不只是檢的的查找,還要把全部的數據一一驗證
(2)基於堆的算法
基於堆的算法,意思是他是將一個數組將其以堆的方式分配,下面會以圖形表示
make_heap:
<span style="font-size:18px;"><span style="font-size:18px;">template<class _Ranit>inline
void make_heap(_Ranit _First,_Ranit _Last)
int element[]={1,4,200,8,100,5,7};
std::make_heap(element,element+7);</span></span>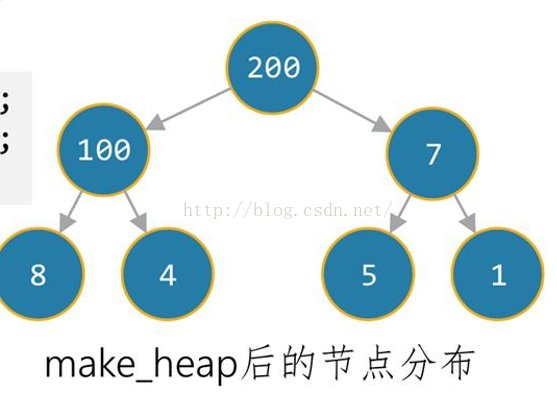
就是將區間[_First,_Last)轉成一個堆,結構採用默認的max_heap結構,維持平衡二叉數
(四)泛型數值算法
泛型數值算法,我的理解是,他的算法中是以容器的數值做主要的運算目標的,而且因為有泛化,他有一個默認的算法,也可以自己特化為自定義計算方式
<span style="font-size:18px;">template<class _Init,class _Ty>inline
_Ty accumulate(_Init _First,_Init _Last,_Ty _Val)
{
.......
}
std::vector<int> v(100);
std::iota(v.begin(),v.end(),1);
int sum=std::accumulate(v.begin(),v.end(),0);</span><span style="font-size:18px;">template<class _Init,class _Ty,class _Fn>inline
_Ty accumulate(_Init _First,_Init _Last,_Ty _Val,_Fn _Func)
{
.......
}
std::vector<int> v(100);
std::iota(v.begin(),v.end(),1);
int sum=std::accumulate(v.begin(),v.end(),1,std::multiplies<int>());</span>














 389
389











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









