






GANs系列
最近在调研自动生成文本方面的内容,这里我将参考了一些资料并对这些知识点进行了整理总结,初步总结如下:
目录
GANs
生成对抗网络是一种生成模型(Generative Model),其背后基本思想是从训练库里获取很多训练样本,从而学习这些训练案例生成的概率分布。
Ian Goodfellow 是对抗生成网络之父。生成对抗模型拆开来是两个东西:一个是判别模型,一个是生成模型。
简单打个比方就是:
(1)两个人比赛,看是 A 的矛厉害,还是 B 的盾厉害。比如,我们有一些真实数据,同时也有一把乱七八糟的假数据。A 拼命地把随手拿过来的假数据模仿成真实数据,并揉进真实数据里。B 则拼命地想把真实数据和假数据区分开。这里,A 就是一个生成模型,类似于卖假货的,一个劲儿地学习如何骗过 B。而 B 则是一个判别模型,类似于警察叔叔,一个劲儿地学习如何分辨出 A 的骗人技巧。如此这般,随着 B 的鉴别技巧的越来越牛,A 的骗人技巧也是越来越纯熟。一个造假一流的 A,就是我们想要的生成模型!
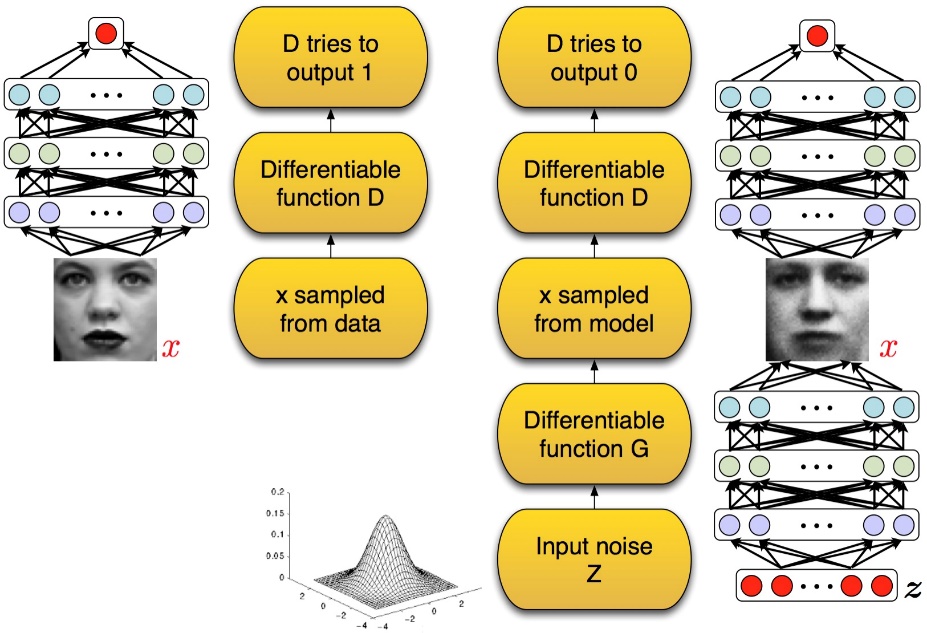
(2)在二人零和博弈中,两位博弈方的利益之和为零或一个常数,即一方有所得,另一方必有所失。GAN模型中的两位博弈方分别由生成式模型(generative model)和判别式模型(discriminative model)充当。生成模型G捕捉样本数据的分布,判别模型是一个二分类器,估计一个样本来自于训练数据(而非生成数据)的概率。G和D一般都是非线性映射函数,例如多层感知机、卷积神经网络等。左图是一个判别式模型,当输入训练数据x时,期待输出高概率(接近1);右图下半部分是生成模型,输入是一些服从某一简单分布(例如高斯分布)的随机噪声z,输出是与训练图像相同尺寸的生成图像。向判别模型D输入生成样本,对于D来说期望输出低概率(判断为生成样本),对于生成模型G来说要尽量欺骗D,使判别模型输出高概率(误判为真实样本),从而形成竞争与对抗。
生成式对抗网络有以下四个优势
(1)根据实际的结果,它们看上去可以比其它模型产生了更好的样本(图像更锐利、清晰)。
(2)生成对抗式网络框架能训练任何一种生成器网络(理论上-实践中,用 REINFORCE 来训练带有离散输出的生成网络非常困难)。大部分其他的框架需要该生成器网络有一些特定的函数形式,比如输出层是高斯的。重要的是所有其他的框架需要生成器网络遍布非零质量(non-zero mass)。生成对抗式网络能学习可以仅在与数据接近的细流形(thin manifold)上生成点。
(3)不需要设计遵循任何种类的因式分解的模型,任何生成器网络和任何鉴别器都会有用。
(4)无需利用马尔科夫链反复采样,无需在学习过程中进行推断(Inference),回避了近似计算棘手的概率的难题。
与PixelRNN相比,生成一个样本的运行时间更小。GAN 每次能产生一个样本,而 PixelRNN 需要一次产生一个像素来生成样本。
与VAE 相比,它没有变化的下限。如果鉴别器网络能完美适合,那么这个生成器网络会完美地恢复训练分布。换句话说,各种对抗式生成网络会渐进一致(asymptotically consistent),而 VAE 有一定偏置。
与深度玻尔兹曼机相比,既没有一个变化的下限,也没有棘手的分区函数。它的样本可以一次性生成,而不是通过反复应用马尔可夫链运算器(Markov chain operator)。
与 GSN 相比,它的样本可以一次生成,而不是通过反复应用马尔可夫链运算器。
与NICE 和 Real NVE 相比,在 latent code 的大小上没有限制。
GAN目前存在的主要问题:
(1)解决不收敛(non-convergence)的问题。
目前面临的基本问题是:所有的理论都认为 GAN 应该在纳什均衡(Nash equilibrium)上有卓越的表现,但梯度下降只有在凸函数的情况下才能保证实现纳什均衡。当博弈双方都由神经网络表示时,在没有实际达到均衡的情况下,让它们永远保持对自己策略的调整是可能的【OpenAI Ian Goodfellow的Quora】。
(2)难以训练:崩溃问题(collapse problem)
GAN模型被定义为极小极大问题,没有损失函数,在训练过程中很难区分是否正在取得进展。GAN的学习过程可能发生崩溃问题(collapse problem),生成器开始退化,总是生成同样的样本点,无法继续学习。当生成模型崩溃时,判别模型也会对相似的样本点指向相似的方向,训练无法继续。【Improved Techniques for Training GANs】
(3)无需预先建模,模型过于自由不可控。
与其他生成式模型相比,GAN这种竞争的方式不再要求一个假设的数据分布,即不需要formulate p(x),而是使用一种分布直接进行采样sampling,从而真正达到理论上可以完全逼近真实数据,这也是GAN最大的优势。然而,这种不需要预先建模的方法缺点是太过自由了,对于较大的图片,较多的 pixel的情形,基于简单 GAN 的方式就不太可控了。在GAN[Goodfellow Ian, Pouget-Abadie J] 中,每次学习参数的更新过程,被设为D更新k回,G才更新1回,也是出于类似的考虑。
DCGAN
WGAN
参考资料:
http://it.sohu.com/20161210/n475485860.shtml
http://blog.csdn.net/solomon1558/article/details/52537114
http://blog.csdn.net/solomon1558/article/details/52549409















 2万+
2万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









