







 本文介绍了CGAN(条件生成对抗网络)的基本原理,旨在解决原始GAN生成图像不可预测的问题,通过引入条件信息实现对生成图像的控制。CGAN将无监督学习转化为有监督学习,允许网络在类别标签等条件约束下生成数据。文章讨论了CGAN的模型结构,展示了如何在生成器和判别器中加入条件信息,并提到了CGAN在图像生成和多模态学习中的应用。尽管存在图像质量等问题,CGAN为后续的pix2pixGAN和CycleGAN奠定了基础。最后,文章提供了使用PyTorch实现CGAN生成MNIST手写数字的代码实践。
本文介绍了CGAN(条件生成对抗网络)的基本原理,旨在解决原始GAN生成图像不可预测的问题,通过引入条件信息实现对生成图像的控制。CGAN将无监督学习转化为有监督学习,允许网络在类别标签等条件约束下生成数据。文章讨论了CGAN的模型结构,展示了如何在生成器和判别器中加入条件信息,并提到了CGAN在图像生成和多模态学习中的应用。尽管存在图像质量等问题,CGAN为后续的pix2pixGAN和CycleGAN奠定了基础。最后,文章提供了使用PyTorch实现CGAN生成MNIST手写数字的代码实践。

一、原始GAN的缺点
生成的图像是随机的,不可预测的,无法控制网络输出特定的图片,生成目标不明确,可控性不强。针对原始GAN不能生成具有特定属性的图片的问题, Mehdi Mirza等人提出了cGAN,其核心在于将属性信息y 融入生成器G和判别器D中,属性y可以是任何标签信息, 例如图像的类别、人脸图像的面部表情等。
二、CGAN的基本原理
cGAN的中心思想是希望 可以控制 GAN 生成的图片,而不 是单纯的随机生成图片。 具体来说,Conditional GAN 在生成器和判别器的输入中 增加了额外的 条件信息,生成器生成的图片只有足够真实 且与条件相符,才能够通过判别器。
实际上 , 在无条件约束的生成模型中 , 没法控制数据生成的模式。然而,通过额外的信息对模型进行约束,有可能指导数据生成的过程。条件约束可以是类标签 , 可以是图像修补的部分数据, 甚至是来自不同模态的数据
cGAN将 无监督学习 转为 有监督学习 使得网络可以更好地在我们的掌控下进行学习!
从公式看,cgan相当于在原始GAN的基础上对生成器部分 和判别器部分都加了一个条件
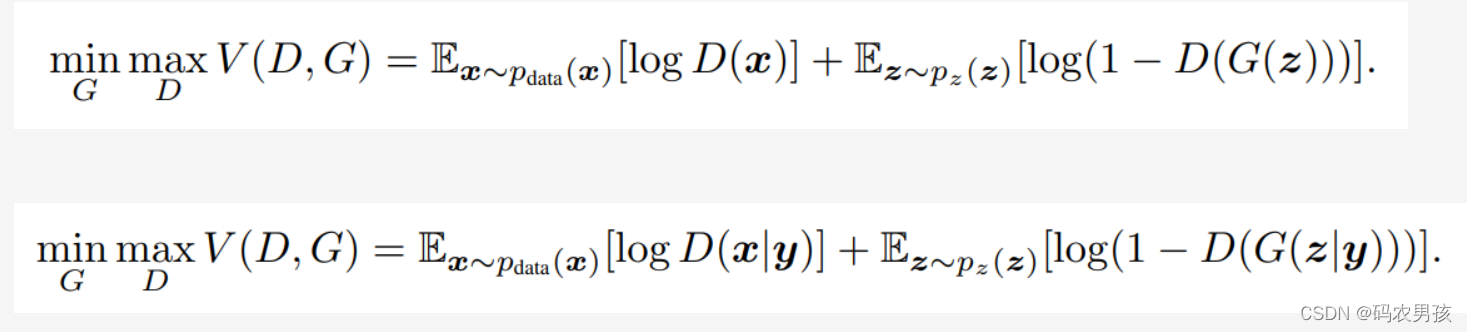
三、CGAN模型
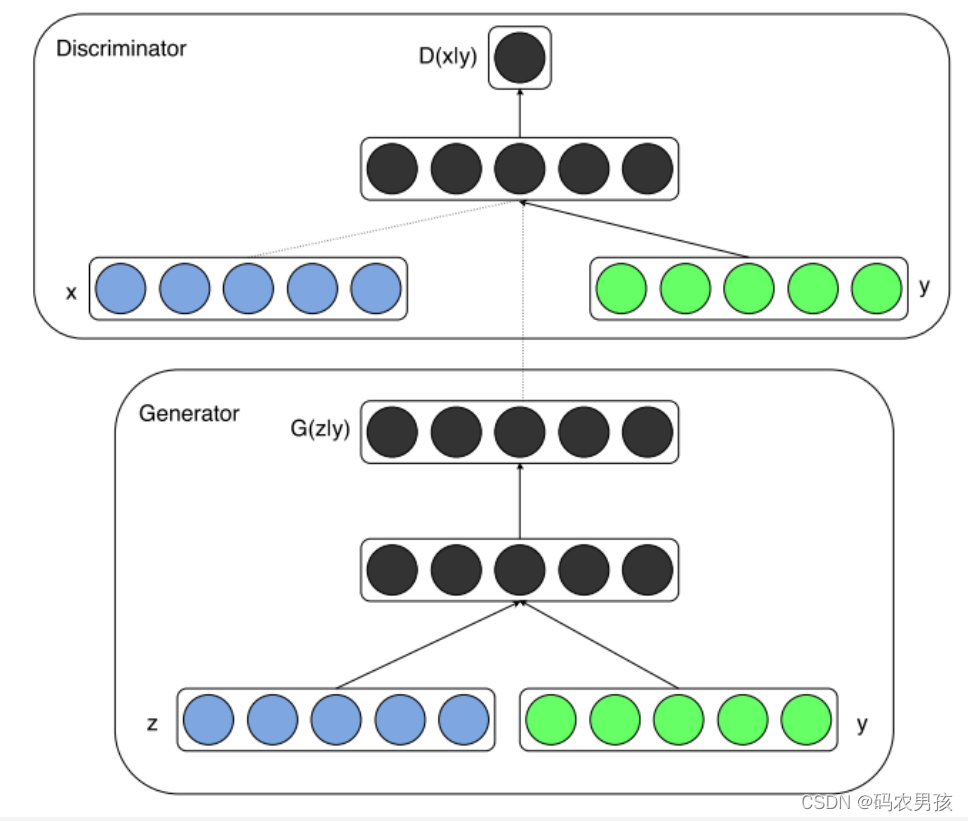
如果将上图绿色部分的y去掉,就是GAN的原理图。
四、CGAN结构
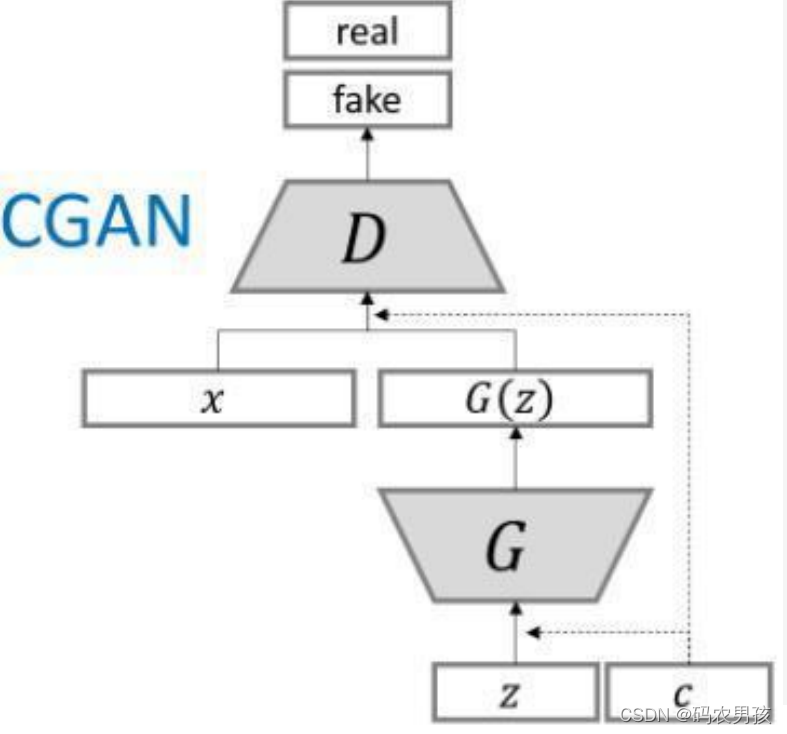
为了实现条件GAN的目的,生成网络和判别网络的原理和 训练方式均要有所改变。
模型部分,在判别器和生成器中都添加了额外信息 y,y 可 以是类别标签或者是其他类型的数据,可以将 y 作为一个 额外的输入层丢入判别器和生成器。
在生成器中,作者将输入噪声 z 和 y 连在一起隐含表示, 带条件约束这个简单直接的改进被证明非常有效,并广泛用 于后续的相关工作中。论文是在MNIST数据集上以类别标 签为条件变量,生成指定类别的图像。作者还探索了CGAN 在用于图像自动标注的多模态学习上的应用,在MIR Flickr25000数据集上,以图像特
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 1406
1406

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











