




 本文探讨了HDFS的磁盘选择策略,包括RoundRobinVolumeChoosingPolicy和AvailableSpaceVolumeChoosingPolicy的优缺点,并提出自定义的ReferenceCountVolumeChoosingPolicy,该策略考虑了磁盘的引用计数以优化写入性能。
本文探讨了HDFS的磁盘选择策略,包括RoundRobinVolumeChoosingPolicy和AvailableSpaceVolumeChoosingPolicy的优缺点,并提出自定义的ReferenceCountVolumeChoosingPolicy,该策略考虑了磁盘的引用计数以优化写入性能。
前言
在HDFS中,所有的数据都是存在各个DataNode上的.而这些DataNode上的数据都是存放于节点机器上的各个目录中的,而一般每个目录我们会对应到1个独立的盘,以便我们把机器的存储空间基本用上.这么多的节点,这么多块盘,HDFS在进行写操作时如何进行有效的磁盘选择呢,选择不当必然造成写性能下降,从而影响集群整体的性能.本文来讨论一下目前HDFS中存在的几个磁盘选择策略的特点和不足,然后针对其不足,自定义1个新的磁盘选择策略.
HDFS现有磁盘选择策略
上文前言中提到,随着节点数的扩增,磁盘数也会跟着线性变化,这么的磁盘,会造成1个问题,数据不均衡现象,这个是最容易发生的.原因可能有下面2个:
1.HDFS写操作不当导致.
2.新老机器上线使用时间不同,造成新机器数据少,老机器数据多的问题.
第二点这个通过Balancer操作可以解决.第一个问题才是最根本的,为了解决磁盘数据空间不均衡的现象,HDFS目前的2套磁盘选择策略都是围绕着"数据均衡"的目标设计的.下面介绍这2个磁盘选择策略.
一.RoundRobinVolumeChoosingPolicy
上面这个比较长的类名称可以拆成2个单词,RoundRobin和VolumeChoosingPolicy,VolumeChoosingPolicy理解为磁盘选择策略,RoundRobin这个是一个专业术语,叫做"轮询",类似的还有一些别的类似的术语,Round-Robin Scheduling(轮询调度),Round-Robin 算法等.RoundRobin轮询的意思用最简单的方式翻译就是一个一个的去遍历,到尾巴了,再从头开始.下面是一张解释图:
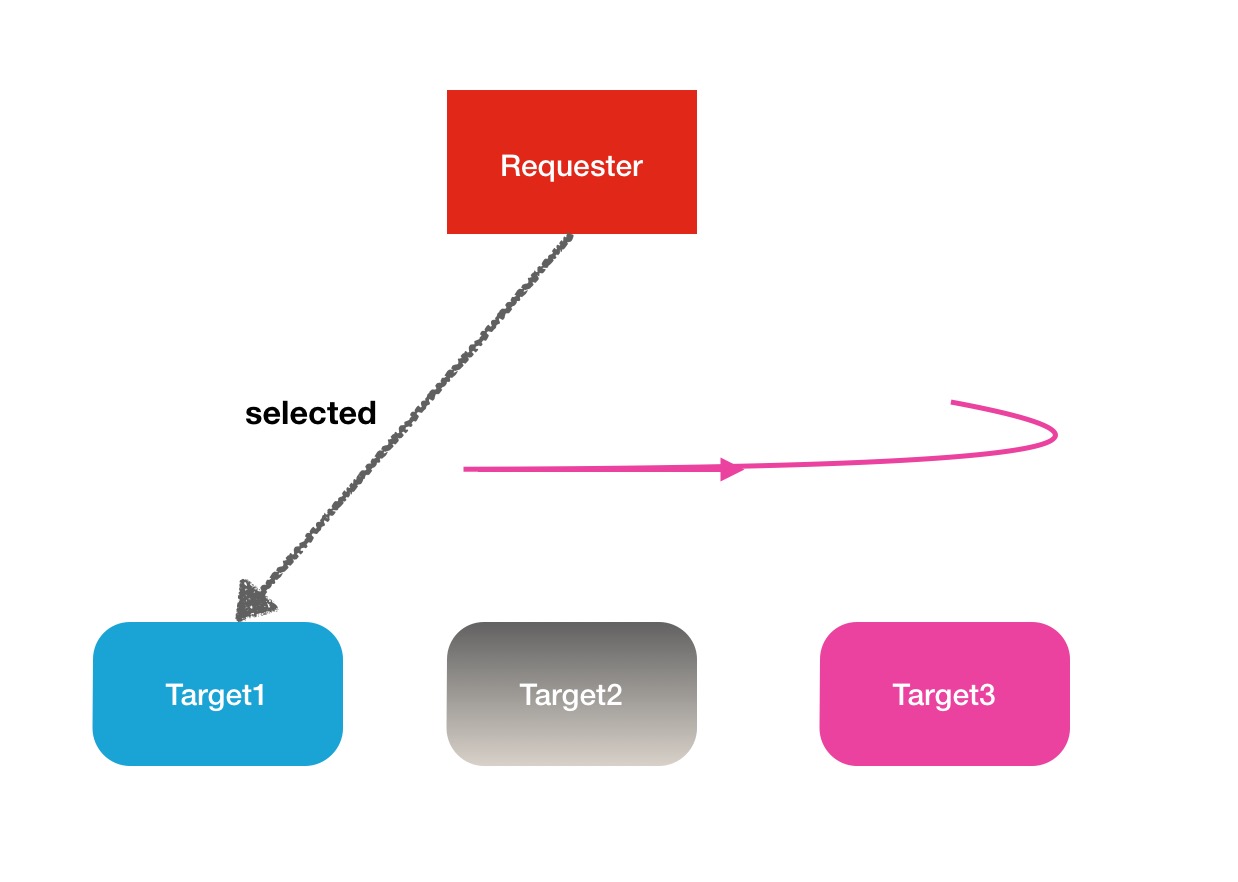
下面给出在HDFS中他的核心代码如下,我加了注释上去,帮助大家理解:
/**
* Choose volumes in round-robin order.
*/
public class RoundRobinVolumeChoosingPolicy<V extends FsVolumeSpi>
implements VolumeChoosingPolicy<V> {
public static final Log LOG = LogFactory.getLog(RoundRobinVolumeChoosingPolicy.class);
private int curVolume = 0;
@Override
public synchronized V chooseVolume(final List<V> volumes, long blockSize)
throws IOException {
//如果磁盘数目小于1个,则抛异常
if(volumes.size() < 1) {
throw new DiskOutOfSpaceException("No more available volumes");
}
//如果由于失败磁盘导致当前磁盘下标越界了,则将下标置为0
// since volumes could've been removed because of the failure
// make sure we are not out of bounds
if(curVolume >= volumes.size()) {
curVolume = 0;
}
//赋值开始下标
int startVolume = curVolume;
long maxAvailable = 0;
while (true) {
//获取当前所下标所代表的磁盘
final V volume = volumes.get(curVolume);
//下标递增
curVolume = (curVolume + 1) % volumes.size();
//获取当前选中磁盘的可用剩余空间
long availableVolumeSize = volume.getAvailable();
//如果可用空间满足所需要的副本块大小,则直接返回这块盘
if (availableVolumeSize > blockSize) {
return volume;
}
//更新最大可用空间值
if (availableVolumeSize > maxAvailable) {
maxAvailable = availableVolumeSize;
}
//如果当前指标又回到了起始下标位置,说明已经遍历完整个磁盘列
//没有找到符合可用空间要求的磁盘
if (curVolume == startVolume) {
throw new DiskOutOfSpaceException("Out of space: "
+ "The volume with the most available space (=" + maxAvailable
+ " B) is less than the block size (=" + blockSize + " B).");
}
}
}
}理论上来说这种策略是蛮符合数据均衡的目标的,因为一个个的写吗,每块盘写入的次数都差不多,不存在哪块盘多写少写的现象,但是唯一的不足之处在于每次写入的数据量是
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1375
1375

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









