







 本文深入解析HDFS的Quorum Journal Manager (QJM)机制,从Active/Standby NameNode的editlog读写、QJM的RPC调用过程以及JournalNode的同步与恢复三个方面进行详细分析,帮助理解QJM在源码层面的实现。
本文深入解析HDFS的Quorum Journal Manager (QJM)机制,从Active/Standby NameNode的editlog读写、QJM的RPC调用过程以及JournalNode的同步与恢复三个方面进行详细分析,帮助理解QJM在源码层面的实现。
前言
上周写了一篇译文专门从结构设计的层面来分析HDFS的QJM的架构设计,总体而言,文章偏重理论介绍.本文将继续围绕QJM机制展开分析,但是不同点在于,本文将会从更细粒度的层面来分析这套机制,帮助大家从源代码层面理解QJM的具体实现.本文将从Active/Standby的editlog读写,QJM的RPC调用过程以及JournalNode的同步/恢复三方面进行具体的分析.
Active/Standby的editlog读写
更直接地来说,此标题所表示的意思其实是Active/Standby的NameNode之间的数据同步,通过的”媒介信息”就是editlog.下面用一句话来概况这个过程,如下:
ANN写editlog到各个JN上,然后SNN再从这些JN上以流式的方式读取editlog,然后load到自己的内存中,以此保证自身与ANN上数据的一致性.
当然,上述过程中会有少许的延时,因为SNN做tail editlog动作是周期性的执行,并不是实时的.至于SNN具体如何去读edilog的过程,后面将会提到.
下面这张非常经典的HDFS的HA模式图直观地展示了上面所说的过程(请关注中间那块区域):
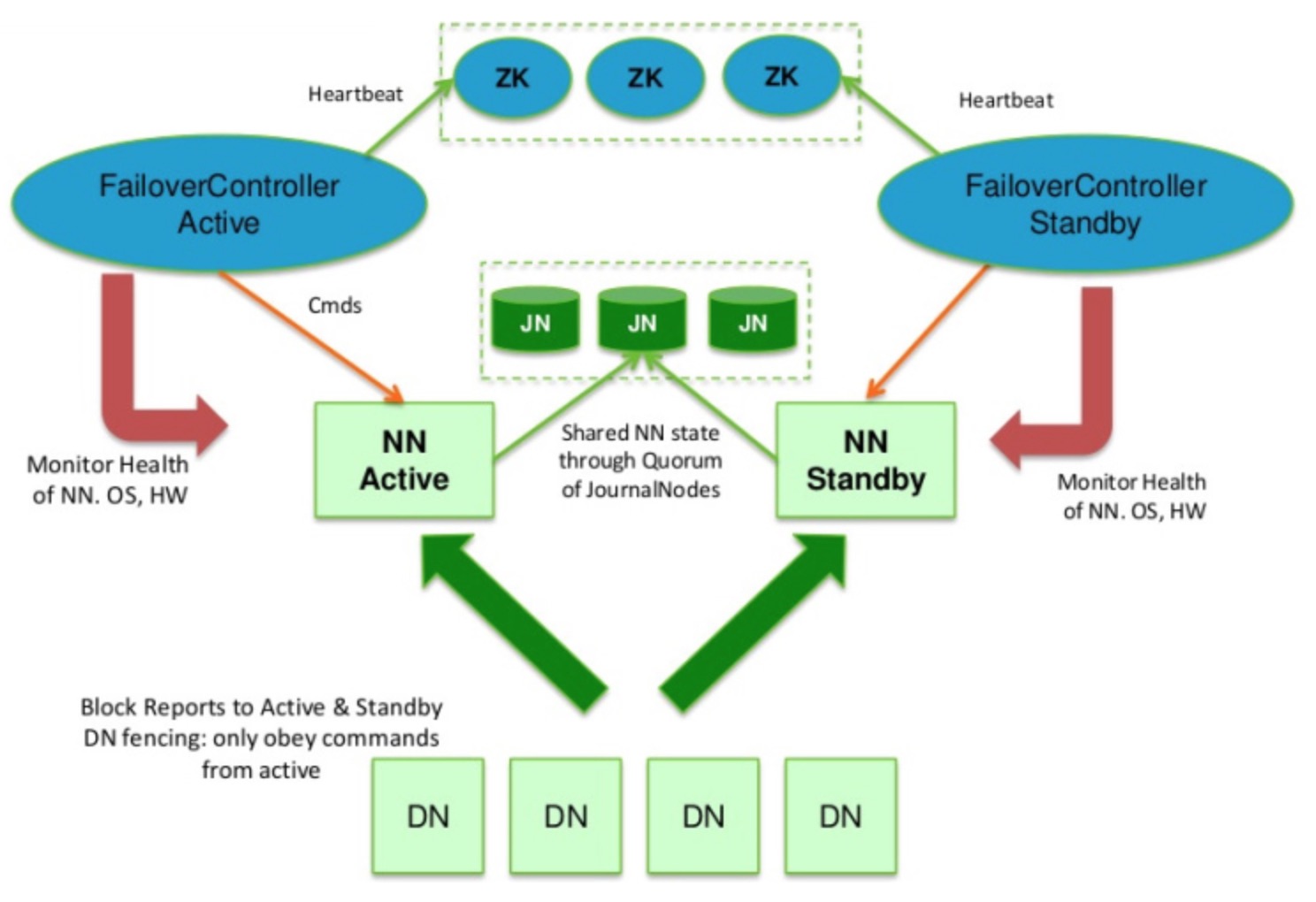
图 1-1 HDFS HA模式
ANN如何向各个JN写edlitlog的过程在下文中将会提到,所以此部分主要来讨论讨论SNN如何做定期的editlog-tail的动作.实现这个功能的核心类叫做EditLogTailer,下面我们直接进入此类.
这是源码中对此类功能的介绍:
EditLogTailer represents a thread which periodically reads from edits journals and applies the transactions contained within to a given FSNamesystem.
这里就不做解释了.下面再来看看几个主要周期时间的定义:
- 1.logRollPeriodMs:ANN写入新editlog的最长容忍时间,如果距离上次写完的时间已经超过此间隔时间,则会触发ANN做一次rollEditLog的动作,此配置项由dfs.ha.log-roll.period所控制,默认时间120s.
- 2.sleepTimeMs:SNN同步editlog日志的周期时间,由配置项dfs.ha.tail-edits.period所控制,默认时间60s.也就是说,SNN会每隔60s,从JN节点中读取新写入的editlog.
上述2个参数刚好是一个控制写速率,另一个控制读速率,通过调整这2个参数值,在一定程度上可以控制ANN与SNN之间元数据的同步速率.而在EditLogTailer中最主要的操作则是在EditLogTailerThread,上面定义的2个关键的时间变量也是在此线程中被调用.
private class EditLogTailerThread extends Thread {
private volatile boolean shouldRun = true;
...
@Override
public void run() {
SecurityUtil.doAsLoginUserOrFatal(
new PrivilegedAction<Object>() {
@Override
public Object run() {
// 执行doWork主操作方法
doWork();
return null;
}
});
}在doWork方法中,将会进行定期的tail editlog的操作.
private void doWork() {
while (shouldRun) {
try {
// There's no point in triggering a log roll if the Standby hasn't 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章

















 3638
3638

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









