







https://antkillerfarm.github.io/
粗看起来,这类恒等变换没有太大意义。然而这类恒等变换之所以能够成立,最根本的地方在于,隐藏层的神经元具有表达输出样本的能力,也就是用低维表达高维的能力。反过来,我们就可以利用这一点,实现数据的降维操作。
但是,不是所有的数据都能够降维,而这种情况通常会导致Autoencoder的训练失败。
和Autoencoder类似的神经网络还有:Denoising Autoencoder(DAE)、Variational Autoencoder(VAE)、Sparse Autoencoder(SAE)。
参考:
http://ufldl.stanford.edu/tutorial/unsupervised/Autoencoders/
http://blog.csdn.net/changyuanchn/article/details/15681853
深度学习之autoencoder
http://www.cnblogs.com/neopenx/p/4370350.html
降噪自动编码器(Denoising Autoencoder)
https://zhuanlan.zhihu.com/p/27549418
花式解释AutoEncoder与VAE
https://mp.weixin.qq.com/s/lODy8ucB3Bw9Y1sy1NxTJg
无监督学习中的两个非概率模型:稀疏编码与自编码器
词向量
One-hot Representation
NLP是ML和DL的重要研究领域。但是多数的ML或DL算法都是针对数值进行计算的,因此如何将自然语言中的文本表示为数值,就成为了一个重要的基础问题。
词向量顾名思义就是单词的向量化表示。最简单的词向量表示法当属One-hot Representation:
假设语料库的单词表中有N个单词,则词向量可表示为N维向量 [0,…,0,1,0,…,0]
这种表示法由于N维向量中只有一个非零元素,故名。该非零元素的序号,就是所表示的单词在单词表中的序号。
One-hot Representation的缺点在于:
1.该表示法中,由于任意两个单词的词向量都是正交的,因此无法反映单词之间的语义相似度。
2.一个词库的大小是 105 以上的量级。维度过高,会妨碍神经网络学习到稀疏特征。
Word Embedding
针对One-hot Representation的不足,Bengio提出了Distributed Representation,也称为Word Embedding。
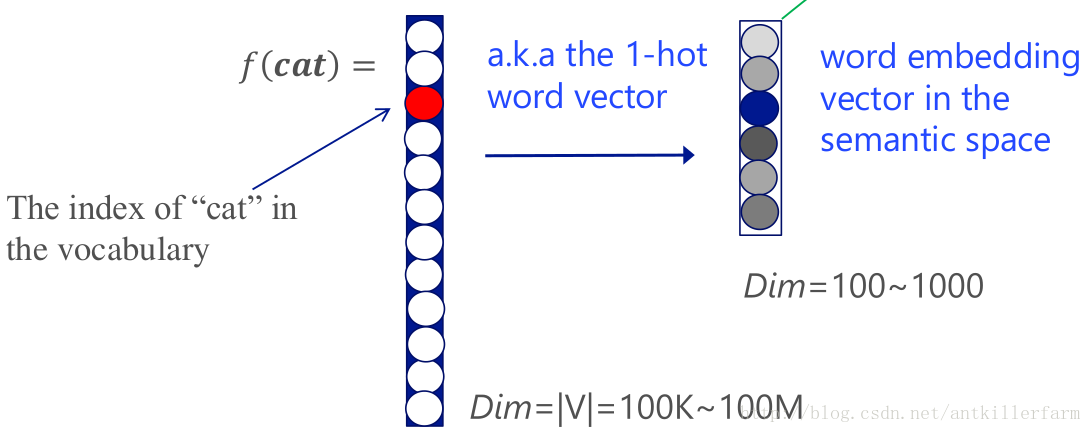
Word Embedding的思路如上图所示,即想办法将高维的One-hot词向量映射到低维的语义空间中。
Bengio自己提出了一种基于神经网络的Word Embedding的方案,然而由于计算量过大,目前已经被淘汰了。
参考:
http://www.cnblogs.com/neopenx/p/4570648.html
词向量概况
word2vec
除了Bengio方案之外,早期人们还尝试过基于共生矩阵(Co-occurrence Matrix)SVD分解的Word Embedding方案。该方案对于少量语料有不错的效果,但一旦语料增大,计算量即呈指数级上升。
这类方案的典型是Latent Semantic Analysis(LSA)。参见《机器学习(二十一)》。
Tomas Mikolov于2013年对Bengio方案进行了简化改进,提出了目前最为常用的word2vec方案。
介绍word2vec的数学原理比较好的有:
《Deep Learning实战之word2vec》,网易有道的邓澍军、陆光明、夏龙著。
《word2vec中的数学》,peghoty著。该书的网页版:
http://blog.csdn.net/itplus/article/details/37969519
老惯例这里只对最重要的内容进行摘要。
CBOW & Skip-gram
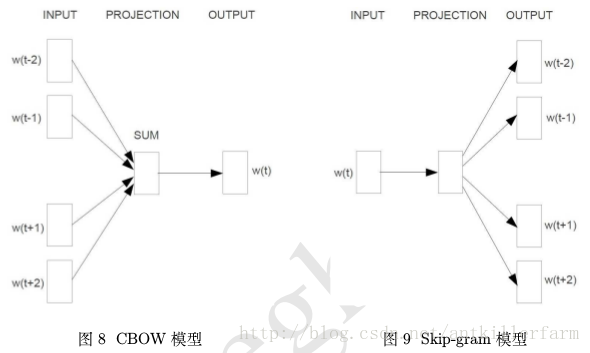
上图是word2vec中使用到的两种模型的示意图。
从图中可知,word2vec虽然使用了神经网络,但是从层数来说,只有3层而已,还谈不上是Deep Learning。但是考虑到DL,基本就是神经网络的同义词,因此这里仍然将word2vec归为DL的范畴。
注:深度学习不全是神经网络,周志华教授提出的gcForest就是一个有益的另类尝试。
研究一个神经网络模型,最重要的除了神经元之间的连接关系之外,就是神经网络的输入输出了。
CBOW(Continuous Bag-of-Words Model)模型和Skip-gram(Continuous Skip-gram Model)模型脱胎于n-gram模型,即一个词出现的概率只与它前后的n个词有关。这里的n也被称为窗口大小.
上图中,窗口大小为5,即一个中心词 {wt} +前面的两个词 {wt−1,wt−2} +后面的两个词 {wt+1,wt+2} 。
| 名称 | CBOW | Skip-gram |
|---|---|---|
| 输入 |
{wt−1,wt−2,wt+1,wt+2}
|
{wt}
|
| 输出 |
{wt}
|
{wt−1,wt−2,wt+1,wt+2}
|
| 目标 | 在输入确定的情况下,最大化输出值的概率。 | 在输入确定的情况下,最大化输出值的概率。 |
Hierarchical Softmax
word2vec的输出层有两种模型:Hierarchical Softmax和Negative Sampling。
Softmax是DL中常用的输出层结构,它表征多分类中的每一个分类所对应的概率。
然而在这里,每个分类表示一个单词,即:分类的个数=词汇表的单词个数。如此众多的分类直接映射到隐层,显然并不容易训练出有效特征。
Hierarchical Softmax是Softmax的一个变种。这时的输出层不再是一个扁平的多分类层,而变成了一个层次化的二分类层。
Hierarchical Softmax一般基于Huffman编码构建。在本例中,我们首先统计词频,以获得每个词所对应的Huffman编码,然后输出层会利用Huffman编码所对应的层次二叉树的路径来计算每个词的概率,并逆传播到隐藏层。
由Huffman编码的特性可知,Hierarchical Softmax的计算量要小于一般的Softmax。
Negative Sampling
在CBOW模型中,已知w的上下文Context(w)需要预测w,则w就是正样本,而其他词是负样本。
负样本那么多,该如何选取呢?Negative Sampling就是一种对负样本采样的方法。
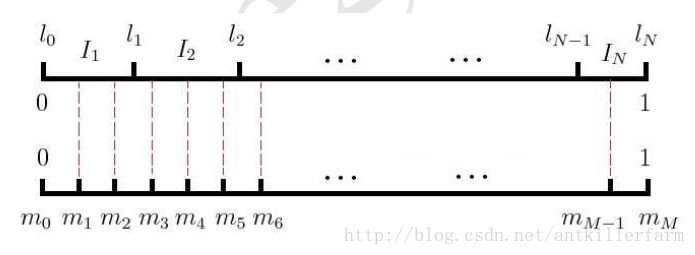
上图是Negative Sampling的原理图。L轴表示的是词频分布,很明显这是一个非等距剖分。而M轴是一个等距剖分。
每次生成一个M轴上的随机数,将之映射到L轴上的一个单词。映射方法如上图中的虚线所示。
除了word2vec之外,类似的Word Embedding方案还有SENNA、RNN-LM、Glove等。但影响力仍以word2vec最大。
Skip-Gram Negative Sampling,又被简称为SGNS。
doc2vec
我们知道,word是sentence的基本组成单位。一个最简单也是最直接得到sentence embedding的方法是将组成sentence的所有word的embedding向量全部加起来。
显然,这种简单粗暴的方法会丢失很多信息。
doc2vec是Mikolov在word2vec的基础上提出的一种生成句子向量的方法。
论文:
《Distributed Representations of Sentences and Documents》
http://cs.stanford.edu/~quocle/paragraph_vector.pdf
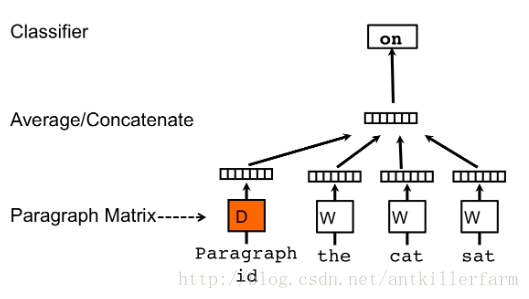
上图是doc2vec的框架图,可以看出doc2vec的原理与word2vec基本一致,区别仅在于前者多出来一个Paragraph Vector参与CBOW或Skip-gram的训练。
Paragraph Vector可以和Word Vector一起生成,也可以单独生成,也就是训练时,采用预训练的Word Vector,并只改变Paragraph Vector的值。
https://www.zhihu.com/question/33952003
如何通过词向量技术来计算2个文档的相似度?
FastText
Word2Vec作者Mikolov加盟Facebook之后,提出了文本分类新作FastText。
FastText模型架构和Word2Vec中的CBOW模型很类似。不同之处在于,FastText预测标签,而CBOW模型预测中间词。
http://www.algorithmdog.com/fast-fasttext
Github:
https://github.com/facebookresearch/fastText
Item2Vec
本质上,word2vec模型是在word-context的co-occurrence矩阵基础上建立起来的。因此,任何基于co-occurrence矩阵的算法模型,都可以套用word2vec算法的思路加以改进。
比如,推荐系统领域的协同过滤算法。
协同过滤算法是建立在一个user-item的co-occurrence矩阵的基础上,通过行向量或列向量的相似性进行推荐。如果我们将同一个user购买的item视为一个context,就可以建立一个item-context的矩阵。进一步的,可以在这个矩阵上借鉴CBoW模型或Skip-gram模型计算出item的向量表达,在更高阶上计算item间的相似度。
论文:
《Item2Vec: Neural Item Embedding for Collaborative Filtering》
word2vec/doc2vec的缺点
1.word2vec/doc2vec基于BOW(Bag Of Word,词袋)模型。该模型的特点是忽略词序,因此对于那些交换词序会改变含义的句子,无法准确评估它们的区别。














 162
162











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









