 理解GBDT:从概念到优化目标
理解GBDT:从概念到优化目标





 GBDT(Gradient Boosting Decision Tree)是一种回归树,用于分类和回归任务。它由多棵小决策树组成,每棵树修正前一棵树的残差。GBDT通过梯度提升逐步逼近损失函数的最小值,每次迭代选择负梯度方向的基函数。这种方法能防止过拟合,并通过残差计算增加错误实例的权重。在R语言中,gbm包可用于实现GBDT,重要参数包括损失函数、迭代次数、学习速率等。
GBDT(Gradient Boosting Decision Tree)是一种回归树,用于分类和回归任务。它由多棵小决策树组成,每棵树修正前一棵树的残差。GBDT通过梯度提升逐步逼近损失函数的最小值,每次迭代选择负梯度方向的基函数。这种方法能防止过拟合,并通过残差计算增加错误实例的权重。在R语言中,gbm包可用于实现GBDT,重要参数包括损失函数、迭代次数、学习速率等。
GBDT,全称Gradient Boosting Decision Tree,叫法比较多,如Treelink、 GBRT(Gradient Boost Regression Tree)、Tree Net、MART(Multiple Additive Regression Tree)等。GBDT是决策树中的回归树,决策树分为回归树和分类树,分类树的衡量标准是最大熵,而回归树的衡量标准是最小化均方差。GBDT可以用来做分类、回归。GBDT由多棵决策树构成,通常都是上百棵树,而且每棵树规模都较小(即树的深度会比较浅)。模型预测的时候,对于输入的一个样本实例,然后会遍历每一棵决策树,每棵树都会对预测值进行调整修正,最后得到预测的结果。
为了搞明白GBDT,下面先解释Gradient Boosting(GB,梯度提升)。
Boosting是利用一些弱分类器的组合来构造一个强分类器。与Boosting相比,GB通过迭代选择一个目标损失函数的负梯度方向上的基函数来逐渐逼近局部极小值。
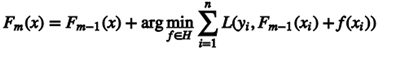
还是不太明白?想想在线性回归中,我们希望找到一组参数使得模型的残差最小化。如果只使用一次项来解释二次曲线,那么就会存有大量残差,此时就可以用二次项来继续解释残差,所以可在模型中加入这个二次项。同样的,GB是先根据初始模型计算伪残差,之后建立一个学习器来解释伪残差,该学习器是在梯度方向上减少残差。再将该学习器乘上权重系数(学习速率)和原来的模型进行线性组合形成新的模型。这样反复迭代就可以找到一个使损失函数的期望达到最小的模型。
借用刘贺博客中的形式化描述:

GBDT的每一棵树学的是之前所有树结论和的残差,这个残差就是一个加预测值后能得真实值的累加量。比如A的真实年龄是18岁,但第一棵树的预测年龄是12岁,差了6岁,即残差为6岁。那么在第二棵树里我们把A的年龄设为6岁去学习。如果第二棵树真的能把A分到6岁的叶子节点,那累加两棵树的结论就是A的真实年龄。如果第二棵树的结论是5岁,则A仍然存在1岁的残差,第三棵树里A的年龄就变成1岁,继续学习。
概括GBDT:先构造一个(决策)树,然后不断在已有模型和实际样本输出的残差上再构造一颗树,依次迭代。
借用刘贺博客中的形式化描述:
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 336
336

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









