







斯坦福公开课Machine Learning笔记(二)–Classification and Logistic Regression
这系列笔记其实已经手写好, 现在一次性发上来, 主要是怕丢. 内容以Andrew Ng的讲义为主,主要以公式推导与理解为主,引入和介绍省略.对于最后的Reinforcement Learning部分, 由于没有讲义以及对其实在不熟悉, 就没有笔记了(主要还是因为没有讲义).
1. Logistic Regression
线性回归比较适合预测的问题,对于分类问题,Logistic Regression用的就非常广泛了.
训练集:
X={x(1),x(2),...,x(m)}
y={y(1),y(2),...,y(m)}
,
y∈{0,1}
LR其实是在线性回归的基础上再加上一个非线性函数
sigmoid
函数,让其更好的适应分类问题,其函数图象如下:
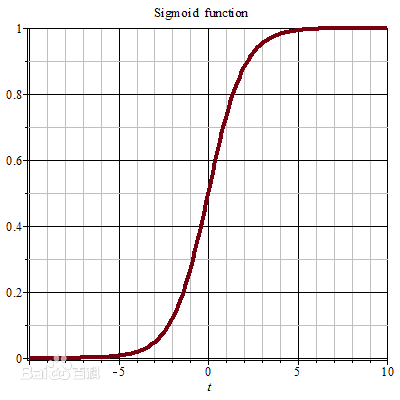
∴LR的预测函数为:
hθ(x)=g(θTx)=11+e−θTx
其中 g(z)=11+e−z
当 z→+∞ 时, g(z)=1 , 当 z→−∞ 时, g(z)=0
∴g(z) 可以看做是概率,可以比较好的适应分类问题.
∴P(y=1|x;θ)=hθ(x)
P(y=0|x;θ)=1−hθ(x)
∴P(y|x;θ)=hyθ(1−hθ)1−y
∴似然函数:
L(θ)=P(y⃗ |x;θ)=∏i=1mP(y(i)|x(i);θ)=∏i=1mhyθ(1−hθ)1−y
∴对数似然函数:
l(θ)=logL(θ)=∑i=1m(yiloghθ(x(i))+(1−y(i))log(1−hθ(x(i))))
然后可以使用梯度下降法或者随机梯度下降法优化问题:
θj:=θj−α∂∂θjl(θ)
其中:
∂∂θjl(θ)=(y1g(θTx)−(1−y)11−g(θTx))∂∂θjg(θTx)=(y1g(θTx)−(1−y)11−g(θTx))g(θTx)(1−g(θTx))∂∂θjθTx=(y(1−g(θTx))−(1−y)g(θTx))xj=(y−hθ(x))xj
∴θj:=θj−α(y(i)−hθ(x))x(i)j
2. The perceptron learning algrithm
感知器算法与LR类似,同样是在线性上加上一个非线性的函数,但是比LR简单.
g(z)={10z≥0z<0
再简单列出迭代函数:
θj:=θj−α(hθ(x(i))−y(i))x(i)j
3.Another algorithm for optimizing (牛顿法)
这里Ng没有讲的特别详细,主要讲解了牛顿法的思想以及推广.
牛顿法:
θ:=θ−l′(θ)l′′(θ)
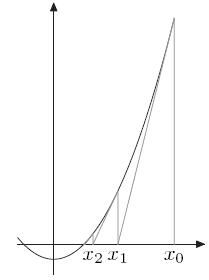
其基本思想就是:
最优化问题中,可以令 f′(x)=0 ,这样可以求得极大极小值。举个栗子,上图就是 f′(x) 的图像。然后通过某个点的导数,快速得到 f′(x)=0 的点。 其实就是通过二阶导数来快速得到 f(x) 的极值。
而使用泰勒展开式展开到二阶:
f(x+Δx)=f(x)+f′(x)Δx+f′′(x)Δx2
当且仅当 Δx 无限趋向于0时成立。
∴f′(x)Δx+f′′(x)Δx2=0 与上式等价。
∴Δx=−f′(x)f′′(x)
∴θ:=θ−l′(θ)l′′(θ)
以上是二维的情况,推广到高维:
θ:=θ−H−1∂∂θl(θ)
其中
Hij=∂2l(θ)∂θi∂θj
牛顿法与梯度下降法相比,收敛会快很多,毕竟是通过二阶导数来求极值。但是计算代价要高很多,因为要计算
H
和














 714
714











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









