







设计要求:对于任意输入的一个LL(1)文法,构造其预测分析表,并对指定输入串分析其是否为该文法的句子。
思路:首先实现集合FIRST(X)构造算法和集合FOLLOW(A)构造算法,再根据FIRST和FOLLOW集合构造出预测分析表,并对指定的句子打印出分析栈的分析过程,判断是否为该文法的句子。
指定文法:
- //文法
- E->TK
- K->+TK
- K->$
- T->FM
- M->*FM
- M->$
- F->i
- F->(E)
对于输入串i+i*i# ,这里我们先给出实验结果截图:
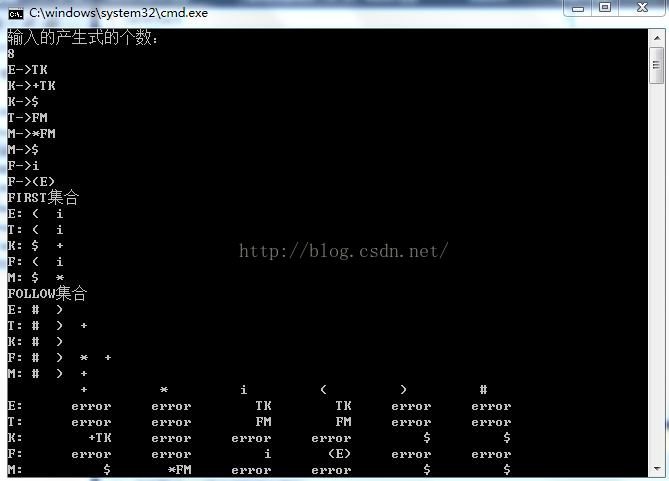
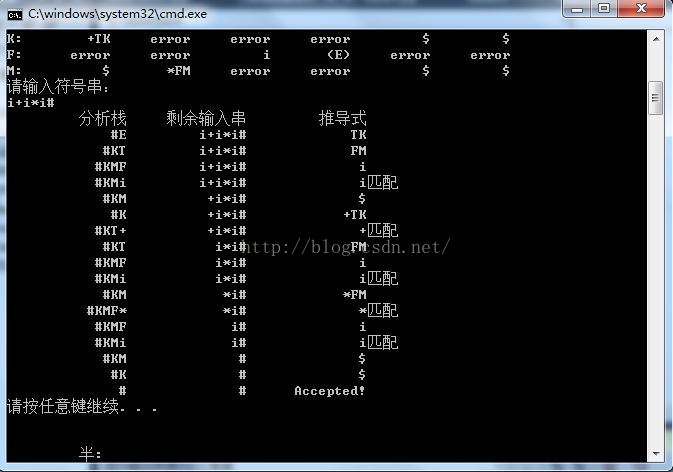
这个实验花了我一天的时间,主要难点在于first集和follow集中的递归判断部分,其他的只要按照下面的判断流程走就可以了。
(1)求FIRST集的算法思想
如果产生式右部第一个字符为终结符,则将其计入左部first集
如果产生式右部第一个字符为非终结符
->求该非终结符的first集
->将该非终结符的非$first集计入左部的first集
->若存在$,则将指向产生式的指针右移
->若不存在$,则停止遍历该产生式,进入下一个产生式
->若已经到达产生式的最右部的非终结符,则将$加入左部的first集
处理数组中重复的first集中的终结符
(2)求FOLLOW集的算法思想
对于文法G中每个非终结符A构造FOLLOW(A)的办法是,连续使用下面的规则,直到每个FOLLOW不在增大为止.
(1) 对于文法的开始符号S,置#于FOLLOW(S)中;
(2) 若A->aBb是一个产生式,则把FIRST(b)\{ε}加至FOLLOW(B)中;
(3) 若A->aB是一个产生式,或A->aBb是一个产生式而b=>ε(即ε∈FIRST(b))则把FOLLOW(A)加至FOLLOW(B)中
(3)生成预测分析表的算法思想
构造分析表M的算法是:
(1) 对文法G的每个产生式A->a执行第二步和第三步;
(2) 对每个终结符a∈FIRST(a),把A->a加至M[A,a]中;
(3) 若ε∈FIRST(a),则把任何b∈FOLLOW(A)把A->a加至M[A,b]中;
(4) 把所有无定义的M[A,a]标上出错标志.
(4)对符号串的分析过程
预测分析程序的总控程序在任何时候都是按STACK栈顶符号X和当前的输入符号行事的,对于任何(X,a),总控程序
每次都执行下述三种可能的动作之一;
(1) 若X=a=”#”,则宣布分析成功,停止分析过程.
(2) 若X=a≠”#”,则把X从STACK栈顶逐出,让a指向下一个输入符号.
(3) 若X是一个非终结符,则查看分析表M,若M[A,a]中存放着关于X的一个产生式,那么,首先把X逐出STACK栈顶,然后
把产生式的右部符号串按反序一一推进STACK栈(若右部符号为ε,则意味着不推什么东西进栈).在把产生式的右部
符号推进栈的同时应做这个产生式相应得语义动作,若M[A,a]中存放着”出错标志”,则调用出错诊察程序ERROR.
在我的程序中,Base类为基类,负责求出FIRST和FOLLOW集;TableStack继承Base类,求出预测分析表和显示符号串的分析过程。
Base.h
- struct node
- {
- char left;
- string right;
- };
- class Base
- {
- protected:
- int T;
- node analy_str[100]; //输入文法解析
- set<char> first_set[100];//first集
- set<char> follow_set[100];//follow集
- vector<char> ter_copy; //去$终结符
- vector<char> ter_colt;//终结符
- vector<char> non_colt;//非终结符
- public:
- Base() :T(0){}
- bool isNotSymbol(char c);
- int get_index(char target);//获得在终结符集合中的下标
- int get_nindex(char target);//获得在非终结符集合中的下标
- void get_first(char target); //得到first集合
- void get_follow(char target);//得到follow集合
- void inputAndSolve(); //处理得到first和follow
- void display(); //显示
- };
TableStack.h
- class TableStack :public Base
- {
- protected:
- vector<char> to_any; //分析栈
- vector<char> left_any;//剩余输入串
- int tableMap[100][100];//预测表
- public:
- TableStack(){ memset(tableMap, -1, sizeof(tableMap)); }
- void get_table(); //得到预测表
- void analyExp(string s); //分析栈的处理
- void print_out();//输出
- void getAns(); //结合处理
- };
接下来只列出FIRST集中的核心递归过程,有详细注释:
- void Base::get_first(char target)
- {
- int tag = 0;
- int flag = 0;
- for (int i = 0; i<T; i++)
- {
- if (analy_str[i].left == target)//匹配产生式左部
- {
- if (!isNotSymbol(analy_str[i].right[0]))//对于终结符,直接加入first
- {
- first_set[get_index(target)].insert(analy_str[i].right[0]);
- }
- else
- {
- for (int j = 0; j<analy_str[i].right.length(); j++)
- {
- if (!isNotSymbol(analy_str[i].right[j]))//终结符结束
- {
- first_set[get_index(target)].insert(analy_str[i].right[j]);
- break;
- }
- get_first(analy_str[i].right[j]);//递归
- // cout<<"curr :"<<analy_str[i].right[j];
- set<char>::iterator it;
- for (it = first_set[get_index(analy_str[i].right[j])].begin(); it != first_set[get_index(analy_str[i].right[j])].end(); it++)
- {
- if (*it == '$')
- flag = 1;
- else
- first_set[get_index(target)].insert(*it);//将FIRST(Y)中的非$就加入FIRST(X)
- }
- if (flag == 0)
- break;
- else
- {
- tag += flag;
- flag = 0;
- }
- }
- if (tag == analy_str[i].right.length())//所有右部first(Y)都有$,将$加入FIRST(X)中
- first_set[get_index(target)].insert('$');
- }
- }
- }
- }
这个语法分析的全部工程代码在我的 Github 上,欢迎大家star学习,希望可以给大家带来帮助。















 387
387

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









