




 本文探讨了深层神经网络训练困难的原因,主要聚焦于消失梯度和梯度不稳定性问题。通过分析梯度消失和梯度爆炸现象,揭示了深层网络中学习速度不一致的根本原因。此外,还提到了深度学习面临的其他障碍,如激活函数选择、权重初始化和优化算法的影响。
本文探讨了深层神经网络训练困难的原因,主要聚焦于消失梯度和梯度不稳定性问题。通过分析梯度消失和梯度爆炸现象,揭示了深层网络中学习速度不一致的根本原因。此外,还提到了深度学习面临的其他障碍,如激活函数选择、权重初始化和优化算法的影响。
Chapter5 为什么深层神经网络难以训练
Intuitively we’d expect networks with many more hidden layers to be more powerful.
原文链接:http://neuralnetworksanddeeplearning.com/chap5.html
一、消失的梯度
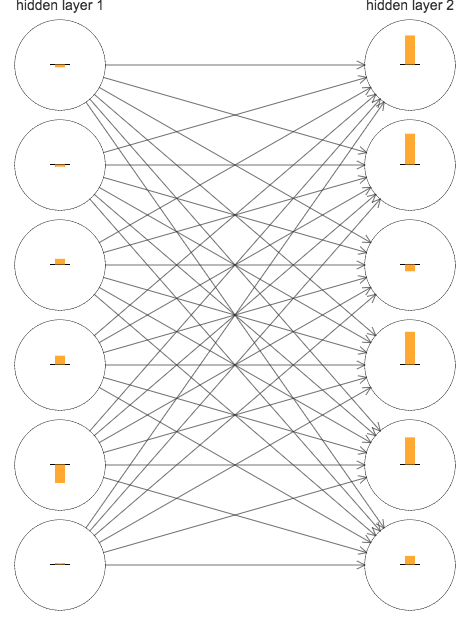
这些条表示了每个神经元上的dC/db,也就是代价函数关于神经元的偏差更变的速率(作为学习速率的一种衡量)。

前面的隐藏层的学习速度要低于后面的隐藏层(hard to train),这个现象也被称作是消失的梯度问题(vanishing gradient problem)。
二、神经网络中的梯度不稳定性
1.梯度消失问题
极简单的深度神经网络(3个隐藏层):

分析可得:
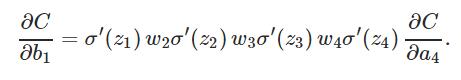
除了最后一项,该表达式是一系列形如 wjσ′(zj) 的乘积。为了理解每个项的行为,画出 σ′(z) 图像如下:
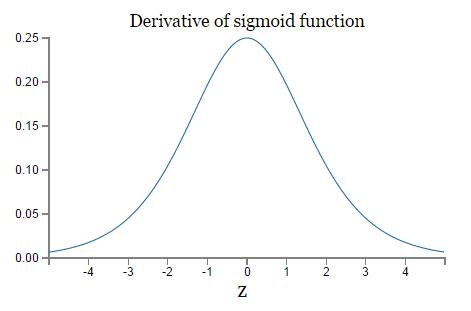
导数最大值: σ′(0)=1/4 ,初始化权重: |wj|<1
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1499
1499

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









