





为什么使用深层网络
对于人脸识别等应用,神经网络的第一层从原始图片中提取人脸的轮廓和边缘,每个神经元学习到不同边缘的信息;网络的第二层将第一层学得的边缘信息组合起来,形成人脸的一些局部的特征,例如眼睛、嘴巴等;后面的几层逐步将上一层的特征组合起来,形成人脸的模样。随着神经网络层数的增加,特征也从原来的边缘逐步扩展为人脸的整体,由整体到局部,由简单到复杂。层数越多,那么模型学习的效果也就越精确。
通过例子可以看到,随着神经网络的深度加深,模型能学习到更加复杂的问题,功能也更加强大。
1. 深层神经网络表示
1.1 什么是深层网络?
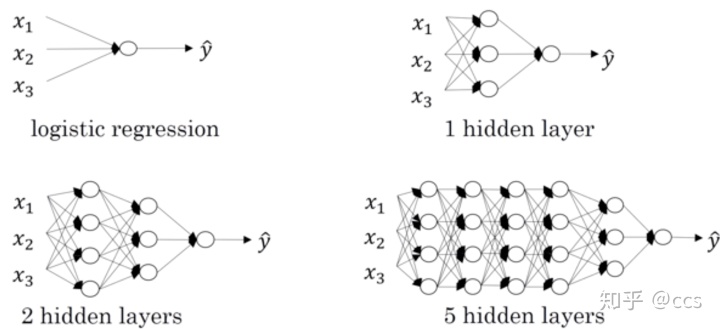
使用浅层网络的时候很多分类等问题得不到很好的解决,所以需要深层的网络。
2. 四层网络的前向传播与反向传播
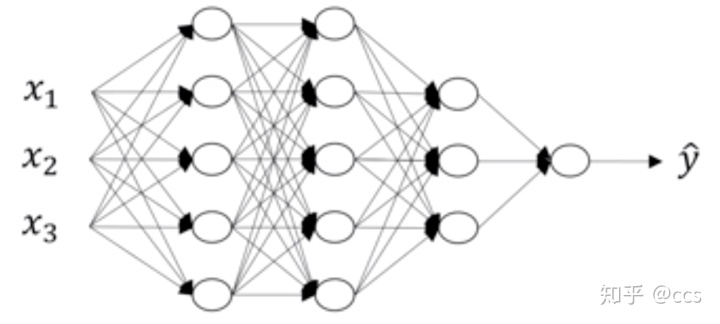
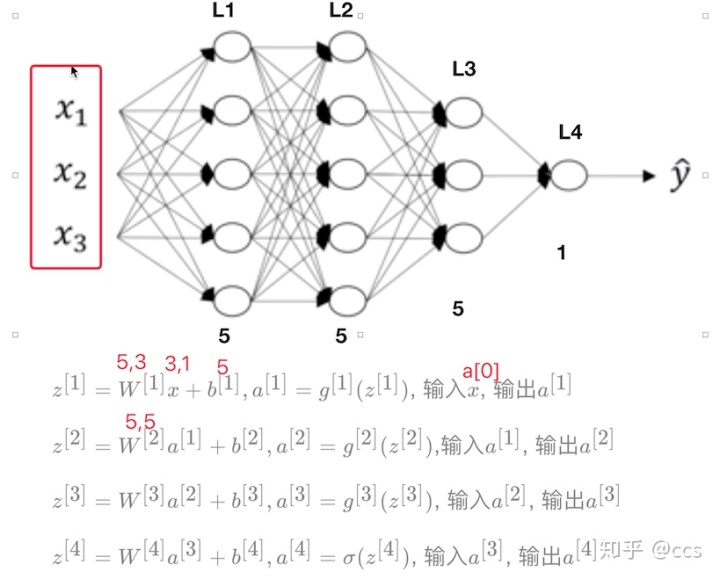
在这里首先对每层的符号进行一个确定,我们设置L为第几层,n为每一层的个数,
2.1 前向传播
首先还是以单个样本来进行表示,每层经过线性计算和激活函数两步计算
, 输入
, 输出
![]()
,输入
, 输出
![]()
,输入
, 输出
![]()
,输入
, 输出
![]()
我们将上式简单的用通用公式表达出来,
, 输入
, 输出
![]()
- m个样本的向量表示
![]()
输入
, 输出
![]()
理解
2.1 反向传播
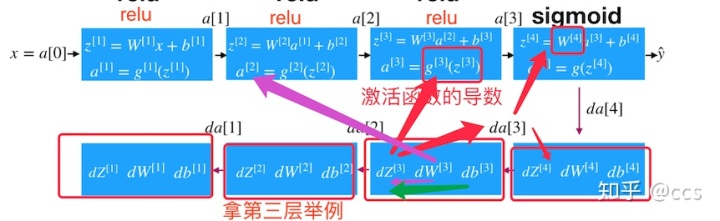
因为涉及到的层数较多,所以我们通过一个图来表示反向的过程
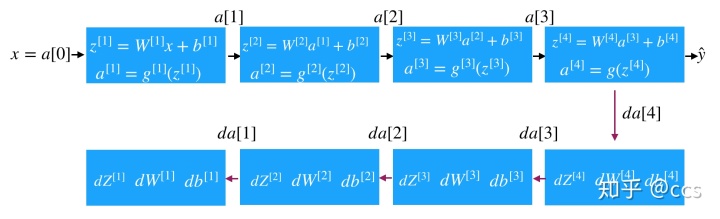
- 反向传播的结果(理解)
单个样本的反向传播:
多个样本的反向传播
![]()
![]()
![]()
![]()
理解
3. 参数与超参数
3.1 参数
参数即是我们在过程中想要模型学习到的信息(模型自己能计算出来的),例如
3.2 超参数
典型的超参数有:
- 学习速率:
- 迭代次数:
- 隐藏层的层数:
- 每一层的神经元个数:
- 激活函数
的选择
当开发新应用时,预先很难准确知道超参数的最优值应该是什么。因此,通常需要尝试很多不同的值。应用深度学习领域是一个很大程度基于经验的过程。
3.3 参数初始化
- 为什么要随机初始化权重
如果在初始时将两个隐藏神经元的参数设置为相同的大小,那么两个隐藏神经元对输出单元的影响也是相同的,通过反向梯度下降去进行计算的时候,会得到同样的梯度大小,所以在经过多次迭代后,两个隐藏层单位仍然是对称的。无论设置多少个隐藏单元,其最终的影响都是相同的,那么多个隐藏神经元就没有了意义。
在初始化的时候,W 参数要进行随机初始化,不可以设置为 0。b 因为不存在上述问题,可以设置为 0。
理解

以 2 个输入,2 个隐藏神经元为例:
W = np.random.rand(2,2)* 0.01
b = np.zeros((2,1))- 初始化权重的值选择
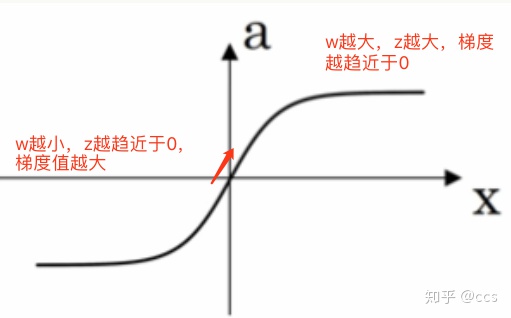
这里将 W 的值乘以 0.01(或者其他的常数值)的原因是为了使得权重 W 初始化为较小的值,这是因为使用 sigmoid 函数或者 tanh 函数作为激活函数时,W 比较小,则 Z=WX+b 所得的值趋近于 0,梯度较大,能够提高算法的更新速度。而如果 W 设置的太大的话,得到的梯度较小,训练过程因此会变得很慢。
理解
ReLU 和 Leaky ReLU 作为激活函数时不存在这种问题,因为在大于 0 的时候,梯度均为 1。















 889
889











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









