







以下都是类比官方指南去处理自己的图片和model:
http://caffe.berkeleyvision.org/gathered/examples/imagenet.html
前期处理
首先,整理一下自己的图片,把格式统一。
然后,如果有强迫症的话(比如我),可以把图片转换成 名字+序号的样子,当然不这么做也无大碍,就是难看些。
train.txt和val.txt的生成
这个shell会生成示例的train.txt 和val.txt,你只需要仿照它类似生成格式为:文件名+标签 的文件
./data/ilsvrc12/get_ilsvrc_aux.sh生成lmdb文件
仿写:examples/imagenet/create_imagenet.sh
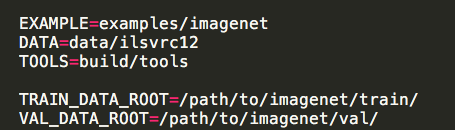
首先,需要在data下创建你的文件夹xxx,里面包含文件夹train(含有用作train的图片),val(含有用作validation的图片),train.txt和val.txt
然后,把DATA修改成data/xxx; TRAIN_DATA_ROOT=data/xxx/train; VAL_DATA_ROOT=data/xxx/val
最后在example创建同名xxx并把create_xxx.sh放在里面
Ps 记得把图片resize一下
运行之后便会在examples/xxx/中生成对应的lmdb文件
执行
./examples/xxx/create_xxx.sh生成mean文件
类比:make_imagenet_mean.sh 与上面修改并执行,在DATA中生成相应的mean文件
EXAMPLE=examples/imagenet
DATA=data/ilsvrc12
TOOLS=build/tools
$TOOLS/compute_image_mean $EXAMPLE/ilsvrc12_train_lmdb \
$DATA/imagenet_mean.binaryproto
echo "Done."执行
./examples/xxx/make_xxx_mean.shtrain
OG是以models/bvlc_reference_caffer为示例,在这个文件夹下修改sovler.prototxt和train_val.txt即可,这里没什么难点就不赘述了。
执行
./build/tools/caffe train --solver=models/bvlc_reference_caffenet/solver.prototxt如果一次执行不完,可以继续模型
./build/tools/caffe train --solver=models/bvlc_reference_caffenet/solver.prototxt --snapshot=models/bvlc_reference_caffenet/caffenet_train_iter_10000.solverstate仿照以上流程很容易就可以DIY了















 262
262

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









