







本期内容:
Exactly once
输出不重复
Exactly once
1,事务一定会被处理,且只被处理一次;
2,输出能够输出且只会被输出。
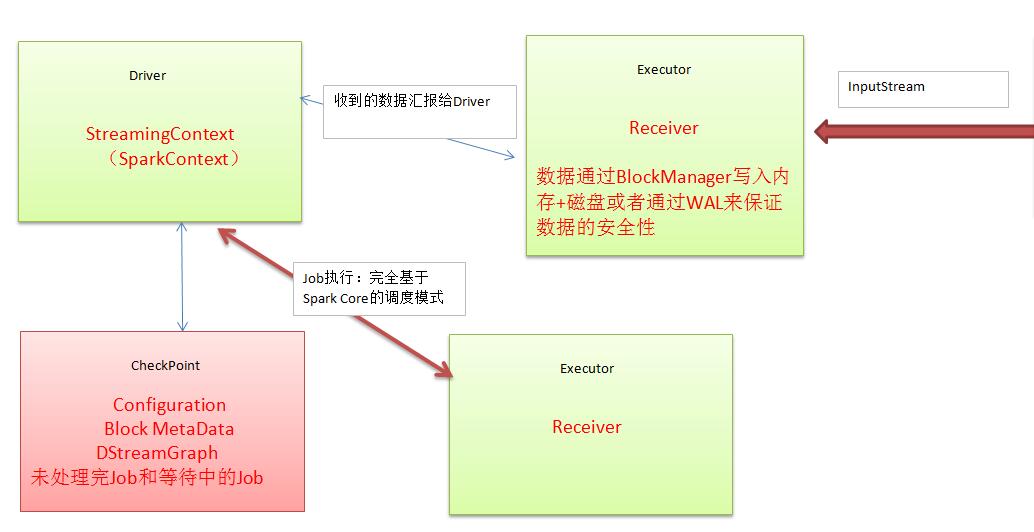
- Receiver:数据通过BlockManager写入内存+磁盘或者通过WAL来保证数据的安全性。
- WAL机制:写数据时先通过WAL写入文件系统然后存储的Executor(存储在内存和磁盘中,由StorageLevel设定),假设前面没有写成功后面一定不会存储在Executor,如不存在Executor中的话,汇报Driver数据一定不被处理。WAL能对要写入的数据,能保证其安全,失败的可能性不大。
- 注意点:Receiver会把数据积累到一定程度才能写入内存磁盘或WAL,如果还没积累到一定程度,Executor或Receiver崩溃了怎么办?答案是数据还是可能会丢失几条。因为尚未做备份,根本没有准备好数据块。
- SparkStreaming说白了就两点:获取数据和产生作业。作业是通过SparkContext来执行的。
- 关于恢复:Driver级别的恢复:直接在Driver进行Checkpoint文件系统把数据读入,内部则重启SparkContext。InputDStream是Driver端产生的(因为是框架调度层面的),这是在逻辑级别而言的。恢复过数据后,重新构建StreamingContext其实也就是构建SparkContext,恢复出的源数据再次产生RDD。恢复时根据上次的Job执行,所以恢复对应的Job,再次提交至Spark集群,再次执行。另一方面,Receiver重新恢复,在以前的数据基础上接收数据,曾经接收的数据根据WAL之类的机制从磁盘中恢复回来。通过这种方式 ,SparkStreaming是个相对可靠的系统,Driver发生故障后重新启动可以在原有基础上继续执行,这样我们就可以继续原有任务而不丢失数据。
- Receiver只接收几条,没有及时WAL其实还是会丢失数据的,这是从整体SparkStreaming考虑而言的;而和Kafka结合的话不会有上面这种问题。
- 我们要做SparkStreaming的话,必须从生产作业流水线考虑输入和输出。外部数据源输入Kafka,然后通过Kafka再交给SparkStreaming,SparkStreaming通过处理后将数据交给离线存储系统或继续交给Kafka或交给实时消费系统。
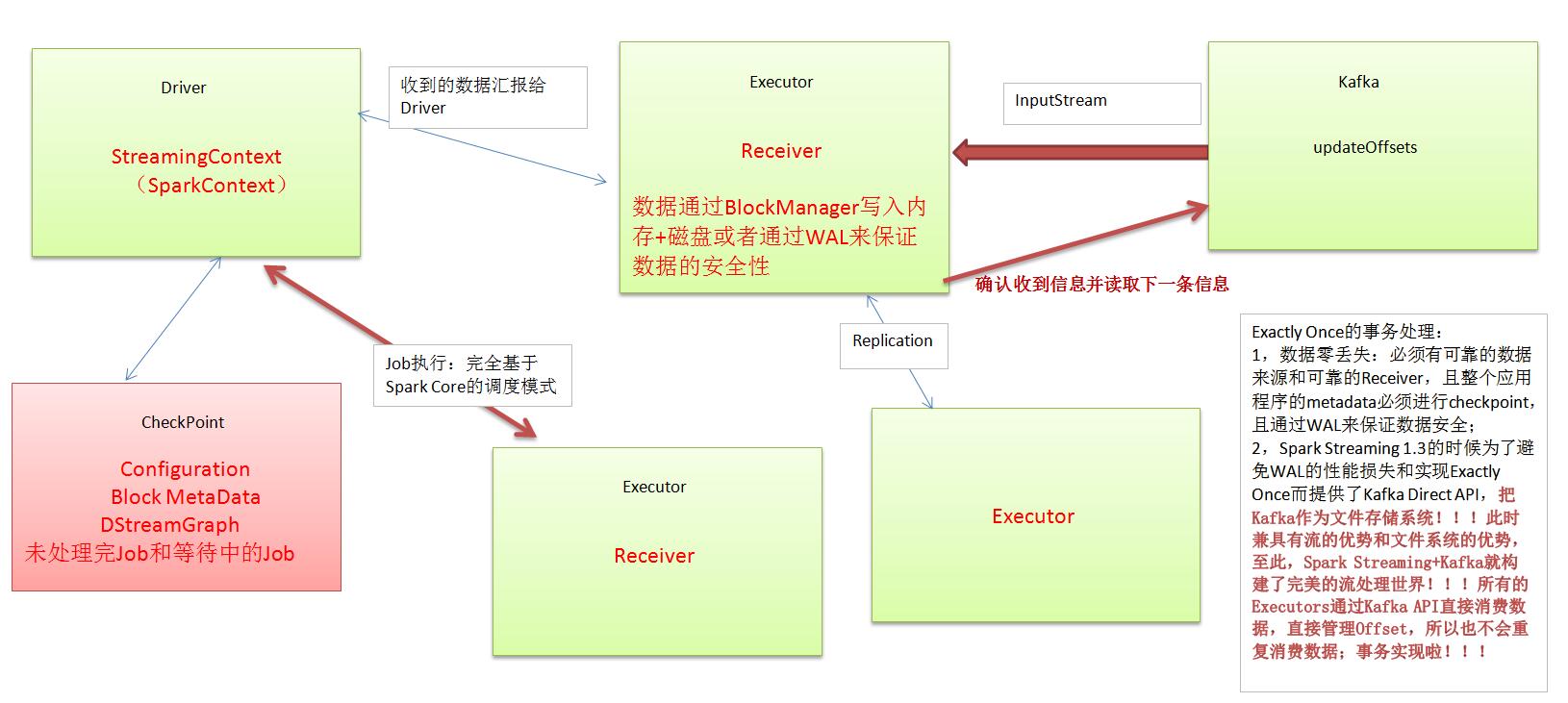
Exactly Once的事务处理:
1,数据零丢失:必须有可靠的数据来源和可靠的Receiver,且整个应用程序的metadata必须进行checkpoint,且通过WAL来保证数据安全;
2,Spark Streaming 1.3的时候为了避免WAL的性能损失和实现Exactly Once而提供了Kafka Direct API,把Kafka作为文件存储系统!!!
此时兼具有流的优势和文件系统的优势,至此,Spark Streaming+Kafka就构建了完美的流处理世界!!!
所有的Executors通过Kafka API直接消费数据,直接管理Offset,所以也不会重复消费数据;事务实现啦!!!
数据丢失及其具体的解决方式:
在Receiver收到数据且通过Driver的调度Executor开始计算数据的时候如果Driver突然崩溃,则此时Executor会被Kill掉,那么Executor中的数据就会丢失,此时就必须通过例如WAL的方式让所有的数据都通过例如HDFS的方式首先进行安全性容错处理,此时如果Executor中的数据丢失的话就可以通过WAL恢复回来;
数据重复读取的情况:
在Receiver收到数据且保存到了HDFS等持久化引擎但是没有来得及进行updateOffsets,此时Receiver崩溃后重新启动就会通过管理Kafka的ZooKeeper中元数据再次重复读取数据,但是此时SparkStreaming认为是成功的,但是Kafka认为是失败的(因为没有更新offset到ZooKeeper中),此时就会导致数据重新消费的情况。
性能损失:
1,通过WAL方式会极大的损伤Spark Streaming中Receivers接受数据的性能;
2,如果通过Kafka的作为数据来源的话,Kafka中有数据,然后Receiver接受的时候又会有数据副本,这个时候其实是存储资源的浪费;
关于Spark Streaming数据输出多次重写及其解决方案:
1,为什么会有这个问题,因为SparkStreaming在计算的时候基于SparkCore,SparkCore天生会做以下事情导致SparkStreaming的结果(部分)重复输出:
Task重试;
慢任务推测;
Stage重复;
Job重试;
2,具体解决方案:
设置spark.task.maxFailures次数为1;
设置spark.speculation为关闭状态(因为慢任务推测其实非常消耗性能,所以关闭后可以显著提高Spark Streaming处理性能)
Spark Streaming on Kafka的话,Job失败后可以设置auto.offset.reset为“largest”的方式。















 754
754

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









