







这一篇博文是【大数据技术●降龙十八掌】系列文章的其中一篇,点击查看目录:
分布式计算是基于分布式存储的,分布式计算框架的算法和设计很多,在Hadoop中,其中一个分布式计算框架就是MapReduce V2。
MapReduce V2使用和借鉴了函数式编程的设计思路,采用了一种分而治之的数据处理模式,将所需进行的数据处理任务分为了Map和Reduce两个过程:即在Map阶段进行数据的读取和预处理,之后将预处理的结果发送给Reduce中进行合并。
1、 执行过程简介
MapReduce过程分为两个阶段:map函数阶段和reduce函数阶段,两个阶段之间有个shuffle。
(1) map函数是数据准备阶段,读取分片内容,并筛选掉非需要的数据,将数据解析为键值对的形式输出,map函数核心目的是形成对数据的索引,以供reduce函数方便对数据进行分析。
(2) reduce函数以Map函数的输出数据为数据源,对数据进行相应的分析,输出结果为最终的目标数据。
(3) 由于map任务的输出结果传递给reduce任务过程中,是在节点间的传输,是占用带宽的,这样带宽就制约了程序执行过程的最大吞吐量,为了减少map和reduce间的数据传输,在map后面添加了combiner函数来就map结果进行预处理,combiner函数是运行在map所在节点的。
下面的示例图描述了整个MapReduce的执行过程:
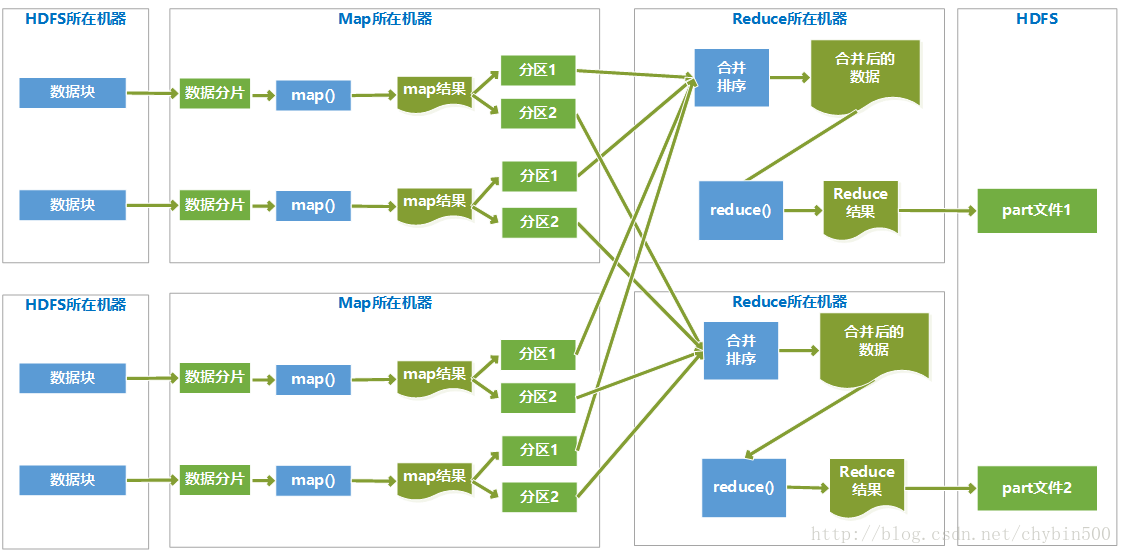
Hadoop将MapReduce输入的数据划分为等长的小分片,一般每个分片在hadoop 2.5中是128M,因为HDFS的每个块是128M。Hadoop 1.X中这个数是64M。
(1) 每个分片数据分配一个map任务,任务内容是用户写的map函数,map函数是尽量运行在数据分片的机器上,这样保证了“数据本地优化”。
(2) map任务的结果是各自排好序的,各个map结果进行再次排序合并后,作为reduce任务的输入。
(3) reduce任务执行reduce函数来处理数据,得到最终结果后,存入HDFS。
(4) 会有多个reduce任务,每个reduce任务的输入都来自于许多map任务,map任务和reduce任务之间是需要传输数据的,占用网络资源,影响效率,为了减少数据传输,可以在map()函数后,添加一个combiner函数来对结果做预处理。
2、 工作机制
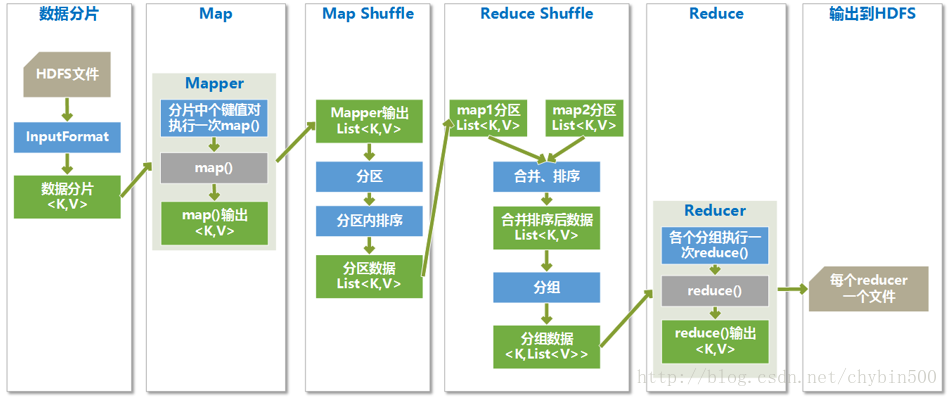
3、 分片
HDFS上的文件要用很多mapper进程处理,而map函数接收的输入是键值对的形式,所以要先将文件进行切分并组织成键值对的形式,这个切分和转换的过程就是数据分片。
在编写MapReduce程序时,可以通过job.setInputFormatClass()方法设置分片规则,如果没有指定默认是用TextInputFormat类。
InputFormat输入格式
(1) InputFormat与分片
在执行Map前需要将处理的数据先进行分片,一个分片对应一个Mapper来处理,分片的依据是根据一个InputFormat类型的类进行的,所有的InputFormat都要继承于InputFormat,InputFormat是个抽象类,它有两个抽象方法:createRecordReader和isSplitable,负责对输入的数据进行分片划分。
一个HDFS文件会被划分为多个分片,一个分片用一个Mapper处理,每个分片又被分成若干个记录,每个记录都是由键值对构成的,每条记录执行一次Map函数
(2) TextInputFormat
TextInputFormat是常用的InputFormat,是Hadoop默认的的输入InputFormat。它继承于FileInputFormat,重写了createRecordReader和isSplitable方法,使用的是reader是LineRecordReader,以回车键(13)或者换行符(10)为行的分隔符。TextInputFormat把数据的每条记录作为一个输入,键是LongWritable类型的,存储的是该行在数据文件中的偏移量,而其对应的值是整个改行的数据。
自定义InputFormat
分片规则是在FileInputFormat类中定义的,可以使用job.setFileInputFormat()方法指定自定义的FileInputFormat。下面是一个自定义InputFormat的例子:
package mapreduce.sort;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FSDataInputStream;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.InputSplit;
import org.apache.hadoop.mapreduce.JobContext;
import org.apache.hadoop.mapreduce.RecordReader;
import org.apache.hadoop.mapreduce.TaskAttemptContext;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.input.FileSplit;
import java.io.IOException;
/**
* Created by 鸣宇淳 on 2017/5/19.
* 自定义输入格式,进行分片
*/
public class MyFileInputFormat extends FileInputFormat<NullWritable, Text> {
public RecordReader<NullWritable, Text> createRecordReader(InputSplit split, TaskAttemptContext context)
throws IOException, InterruptedException {
return new MyRecordReader();
}
/*
确定进行分片处理
*/
@Override
protected boolean isSplitable(JobContext context, Path filename) {
return true;
}
class MyRecordReader extends RecordReader<NullWritable, Text> {
private FileSplit split;//定义分片
private Configuration conf;
private Text value;
private boolean flag;
//public MyRecordReader(InputSplit _split, TaskAttemptContext context) {
// this.split = (FileSplit) _split;//强制类型转换
// this.conf = context.getConfiguration();//获取分片环境
//}
public void initialize(InputSplit split, TaskAttemptContext context) throws IOException, InterruptedException {
}
public NullWritable getCurrentKey() throws IOException, InterruptedException {
return NullWritable.get();//返回空
}
public Text getCurrentValue() throws IOException, InterruptedException {
return null;
}
public float getProgress() throws IOException, InterruptedException {
return 0;//对过程进行监控的方法
}
public void close() throws IOException {
}
public boolean nextKeyValue() throws IOException, InterruptedException {
//获得键值对的方法
if (!flag)//判断是否已经处理完
{
Path file = split.getPath(); //获取分片路径
byte[] fileBuffer = new byte[(int) split.getLength()]; //创建临时用的数组
FileSystem fs = FileSystem.get(conf); //创建文件系统,读取数据
FSDataInputStream input = fs.open(file); //创建输入流
input.read(fileBuffer); //读取数据,存入数组
String str = new String(fileBuffer); //流转为字符串
value = new Text(str); //封装Text,输出为value
flag = true; //标志分片处理完成
return true;
}
return false;
}
}
}
默认的输出格式(OutputFormat)
所有的OutputFormat都必须继承于OutputFormat,并实现其中的getRecordWriter方法。getRecordWriter用于返回一个RecordWriter的实例,RecordWriter中主要是由两个方法构成的:write方法和close方法,write用于将输出的键值对以特定格式写出,close方法用于关闭输出流并做一些后续操作。
默认的输出格式是TextOutputFormat,其作用是将Reduce处理的结果做为文本输出。
自定义OutputFormat输出格式
下面是一个自定义输出格式的例子:
package mapreduce.sort;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FSDataOutputStream;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.mapreduce.RecordWriter;
import org.apache.hadoop.mapreduce.TaskAttemptContext;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import java.io.IOException;
/**
* Created by 鸣宇淳 on 2017/5/23.
*/
public class MyOutputFormat1 extends FileOutputFormat<IntWritable, IntWritable> {
public RecordWriter<IntWritable, IntWritable> getRecordWriter(TaskAttemptContext job)
throws IOException {
return new MyRecordWriter(job);
}
class MyRecordWriter extends RecordWriter<IntWritable, IntWritable> {
TaskAttemptContext job;
FSDataOutputStream fsout;
Configuration conf;
FileSystem fs;
public MyRecordWriter(TaskAttemptContext job) {
this.job = job;
conf = job.getConfiguration();
try {
fs = FileSystem.get(conf);
Path file = getDefaultWorkFile(job, "");
fsout = fs.create(file);
} catch (Exception e) {
}
}
public void write(IntWritable key, IntWritable value) throws IOException, InterruptedException {
fsout.write((String.valueOf(key.get()) + "-" + String.valueOf(value.get())).getBytes("UTF-8"));
fsout.write("\n".getBytes("UTF-8"));
}
public void close(TaskAttemptContext context) throws IOException, InterruptedException {
fsout.close();
}
}
}
4、 Map过程
每个数据分片将启动一个Map进程来处理,分片里的每个键值对运行一次map函数,根据map函数里定义的业务逻辑处理后,得到指定类型的键值对。
5、 Map Shuffle过程
Map过程后要进行Map端的Shuffle阶段,Map端的Shuffle数据处理过程如下图所示:
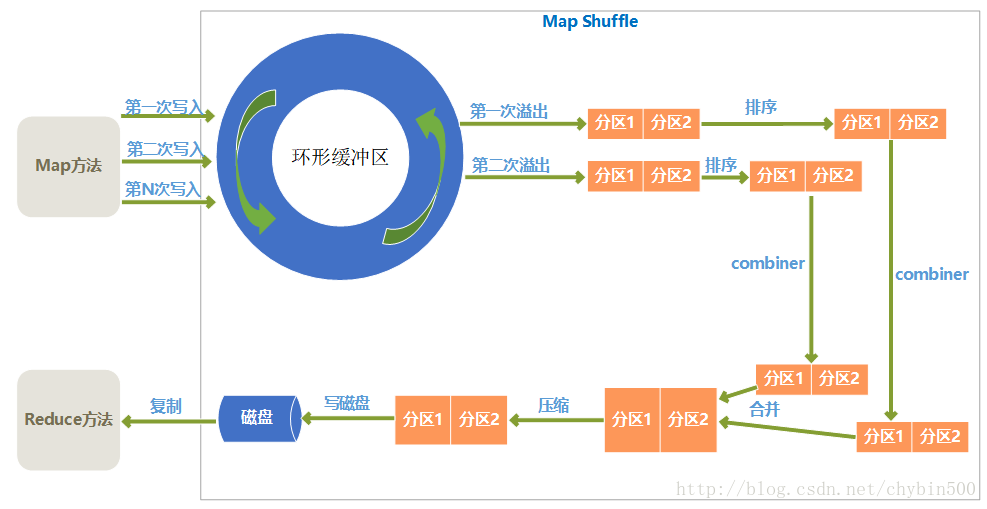
(1) 环形缓冲区
Map输出结果是先放入内存中的一个环形缓冲区,这个环形缓冲区默认大小为100M(这个大小可以在io.sort.mb属性中设置),当环形缓冲区里的数据量达到阀值时(这个值可以在io.sort.spill.percent属性中设置)就会溢出写入到磁盘,环形缓冲区是遵循先进先出原则,Map输出一直不停地写入,一个后台进程不时地读取后写入磁盘,如果写入速度快于读取速度导致环形缓冲区里满了时,map输出会被阻塞直到写磁盘过程结束。
(2) 分区
从环形缓冲区溢出到磁盘过程,是将数据写入mapred.local.dir属性指定目录下的特定子目录的过程。
但是在真正写入磁盘之前,要进行一系列的操作,首先就是对于每个键,根据规则计算出来将来要输出到哪个reduce,根据reduce不同分不同的区,分区是在内存里分的,分区的个数和将来的reduce个数是一致的。
可以自定义分区,如下例子所示:
package mapreduce.sort;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.mapreduce.Partitioner;
/**
* Created by 鸣宇淳 on 2017/5/18.
* 自定义分区类
*/
public class MyPartitioner extends Partitioner<MyDataTypeWritable, IntWritable> {
public int getPartition(MyDataTypeWritable key, IntWritable value, int numPartitions) {
//根据first分区,保证first相同的分到一个分区里。
//因为first都是370000、110000类似的数据,前两位相同就是同一个省份,所以实际上是按照省份分区
//return (key.getFirst()/10000) % numPartitions;
//return Integer.valueOf(key.getFirst().toString().substring(0,1));
return (key.getFirst()/100000) ;
}
}
(3) 排序
在每个分区上,会根据键进行排序。
可以自定义排序,下面是个例子:
package mapreduce.sort;
import org.apache.hadoop.io.WritableComparable;
import org.apache.hadoop.io.WritableComparator;
/**
* Created by 鸣宇淳 on 2017/5/18.
* 自定义比较
*/
public class MyKeySortComparator extends WritableComparator {
public MyKeySortComparator() {
super(MyDataTypeWritable.class, true);
}
@Override
public int compare(WritableComparable a, WritableComparable b) {
//按照first降序,如果first相同就按照second升序
MyDataTypeWritable p1 = (MyDataTypeWritable) a;
MyDataTypeWritable p2 = (MyDataTypeWritable) b;
if (p1.getFirst().equals(p2.getFirst())) {
return p1.getSecond().compareTo(p2.getSecond());
} else {
return p1.getFirst().compareTo(p2.getFirst()) * -1;
}
}
@Override
public int compare(byte[] b1, int s1, int l1, byte[] b2, int s2, int l2) {
return super.compare(b1, s1, l1, b2, s2, l2);
}
}
-
(4) Combiner
-
combiner方法是对于map输出的结果按照业务逻辑预先进行处理,目的是对数据进行合并,减少map输出的数据量。
排序后,如果指定了Combiner方法,就运行Combiner方法使得map的结果更紧凑,从而减少写入磁盘和将来网络传输的数据量。
(5) 合并溢出文件
-
环形缓冲区每次溢出,都会生成一个文件,所以在map任务全部完成之前,会进行合并成为一个溢出文件,每次溢出的各个文件都是按照分区进行排好序的,所以在合并文件过程中,也要进行分区和排序,最终形成一个已经分区和排好序的map输出文件。
在合并文件时,如果文件个数大于某个指定的数量(可以在min.num.spills.for.combine属性设置),就会进再次combiner操作,如果文件太少,效果和效率上,就不值得花时间再去执行combiner来减少数据量了。
(6) 压缩
-
Map输出结果在进行了一系列的分区、排序、combiner合并、合并溢出文件后,得到一个map最终的结果后,就应该真正存储这个结果了,在存储之前,可以对最终结果数据进行压缩,一是可以节约磁盘空间,而是可以减少传递给reduce时的网络传输数据量。
默认是不进行压缩的,可以在mapred.compress.map.output属性设置为true就启用了压缩,而压缩的算法有很多,可以在mapred.map.output.compression.codec属性中指定采用的压缩算法,具体压缩详情,可以看本文的后面部分的介绍。
6、 Reduce Shuffle过程
Map端Shuffle完成后,将处理结果存入磁盘,然后通过网络传输到Reduce节点上,Reduce端首先对各个Map传递过来的数据进行Reduce 端的Shuffle操作,Reduce端的Shuffle过程如下所示:
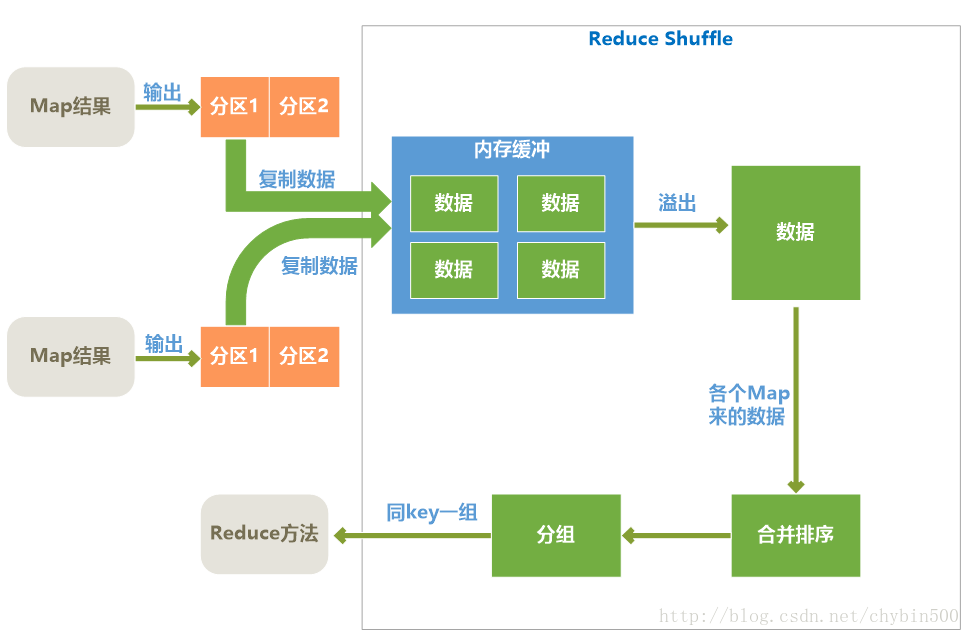
-
(1) 复制数据
-
各个map完成时间肯定是不同的,只要有一个map执行完成,reduce就开始去从已完成的map节点上复制输出文件中属于它的分区中的数据,reduce端是多线程并行来复制各个map节点的输出文件的,线程数可以在mapred.reduce.parallel.copies属性中设置。
reduce将复制来的数据放入内存缓冲区(缓冲区大小可以在mapred.job.shuffle.input.buffer.percent属性中设置)。当内存缓冲区中数据达到阀值大小或者达到map输出阀值,就会溢写到磁盘。
写入磁盘之前,会对各个map节点来的数据进行合并排序,合并时如果指定了combiner,则会再次执行combiner以尽量减少写入磁盘的数据量。为了合并,如果map输出是压缩过的,要在内存中先解压缩后合并。
(2) 合并排序
- 合并排序其实是和复制文件同时并行执行的,最终目的是将来自各个map节点的数据合并并排序后,形成一个文件。
(3) 分组
分组是将相同key的键值对分为一组,一组是一个列表,列表中每一组在一次reduce方法中处理。
可以自定义分组,下面是一个自定义分组的例子:
package mapreduce.sort;
import org.apache.hadoop.io.WritableComparable;
import org.apache.hadoop.io.WritableComparator;
/**
* Created by 鸣宇淳 on 2017/5/18.
* 自定义分组,在reduceshuffle阶段,相同分组的组成一个Iterable列表
*/
public class MyGrouping1Comparator extends WritableComparator {
public MyGrouping1Comparator()
{
super(MyDataTypeWritable.class,true);
}
@Override
public int compare(WritableComparable a, WritableComparable b) {
MyDataTypeWritable p1=(MyDataTypeWritable)a;
MyDataTypeWritable p2=(MyDataTypeWritable)b;
return p1.toString().compareTo(p2.toString());
}
}
-
(4) 执行Reduce方法
- Reduce端的Shuffle完成后,就交由reduce方法来进行处理了。
7、 Reduce过程
Reduce端的Shuffle过程后,最终形成了分好组的键值对列表,相同键的数据分为一组,分组的键是分组的键,值是原来值得列表,然后每一个分组执行一次reduce函数,根据reduce函数里的业务逻辑处理后,生成指定格式的键值对。
这一篇博文是【大数据技术●降龙十八掌】系列文章的其中一篇,点击查看目录:















 569
569

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









