









简单介绍:
这次我们要爬的网页是:Kindle商店中的今日特价书,其中每周/每月特价书同理,就不再重复了
选择这个网页的原因有两个:
一是实用,很多人都会经常去看看Kindle特价书有没有自己喜欢的;
二是简单,不需要分析JS脚本
这次我们学习的基本内容涉及:
urllib2获取网页、re正则表达式、图像获取
阅读前的建议:
- 必备条件:Python的基础知识,学习网站:Python 2.7教程 - 廖雪峰的官方网站
- 建议学习正则表达式
- 更完整的爬虫教程:静觅
- 文章中注释用灰色表示,对代码的理解用深青色,正则表达式相关内容用淡钢蓝
- urllib2对亚马逊的访问并不稳定,有时会出现httplib错误,重新运行即可
开发工具
- IDE: PyDev(Eclipse的一个插件) 或者 PyCharm(JetBrain公司的IDE)[我用的是PyCharm,平时也用PyDev]
- 编辑器:Sublime Text3
- 浏览器:Chrome或者360极速浏览器
正文:
看起来有那么一点奇怪,联想到这个页面是每日更新的,所以我怀疑这个URL每天都会不同,因此我们不能直接访问这个URL。
那么现在我们就应该找一个固定的URL作为起点,然后进行抓取;Kindle商店的URL好像也是不固定的,看起来唯一的选择是亚马逊首页了
我们的思路可以基本捋出来了:
1. 访问亚马逊首页,获取Kindle商店 URL
2. 访问Kindle商店,获取“今日特价书”URL
3. 分析今日特价书的页面,获取书的详细信息
4. 图片的获取
访问亚马逊首页
Python自带了一个名叫urllib2的库,专门用于从网页中获取信息
我们想要获取一个网页的源码,最简单的方式就是:
import urllib2
url = 'https://www.amazon.cn/'
response = urllib2.urlopen(url) # response即是网页返回的内容
print response.read() # 调用read()方法将网页源码转换为字符串我对于这段代码的理解是:
urllib2的urlopen方法将网页的响应封装成类似文件的结构,我们要读取里面的内容时直接read()就好
网页获取的基本知识:
1. GET / POST
访问网页的方式有两种,一种是GET,另一种是POST
GET方法直接请求服务器的网址
POST方法则向服务器发送信息并接收服务器的响应
具体在urllib2中,GET就是简单的urllib2.urlopen(url)
POST则需要将需要提交的表单的所有信息封装成字典values = {'name': 'value', 'name':'value',...}
并且使用postdata = urllib.urlencode(values)
然后才能urllib2.urlopen(url, postdata)
POST适用于访问需要简单的登陆的网站如大多数学校的教务处
2. headers
有些网页为了防止爬虫采用验证浏览器头的方法,所以我们有时候需要改变浏览器头:
headers = {'User-Agent' : user_agent}
request = urllib2.Request(url, headers=headers)
response = urllib2.urlopen(amazonRequest)
在这里我们构建了一个Request,并且用urlopen发送(如果需要POST可以在构建时加上data=postdata)
那么现在,我们就获得了亚马逊首页的源码,但是在PyCharm的控制台太难分析页面了,所以我们将源码复制一下,放到sublime里面,然后我们如图选择语法格式,代码颜色就会显示出来。然后按下代码格式化快捷键Ctrl+Alt+F,代码就好看多啦!
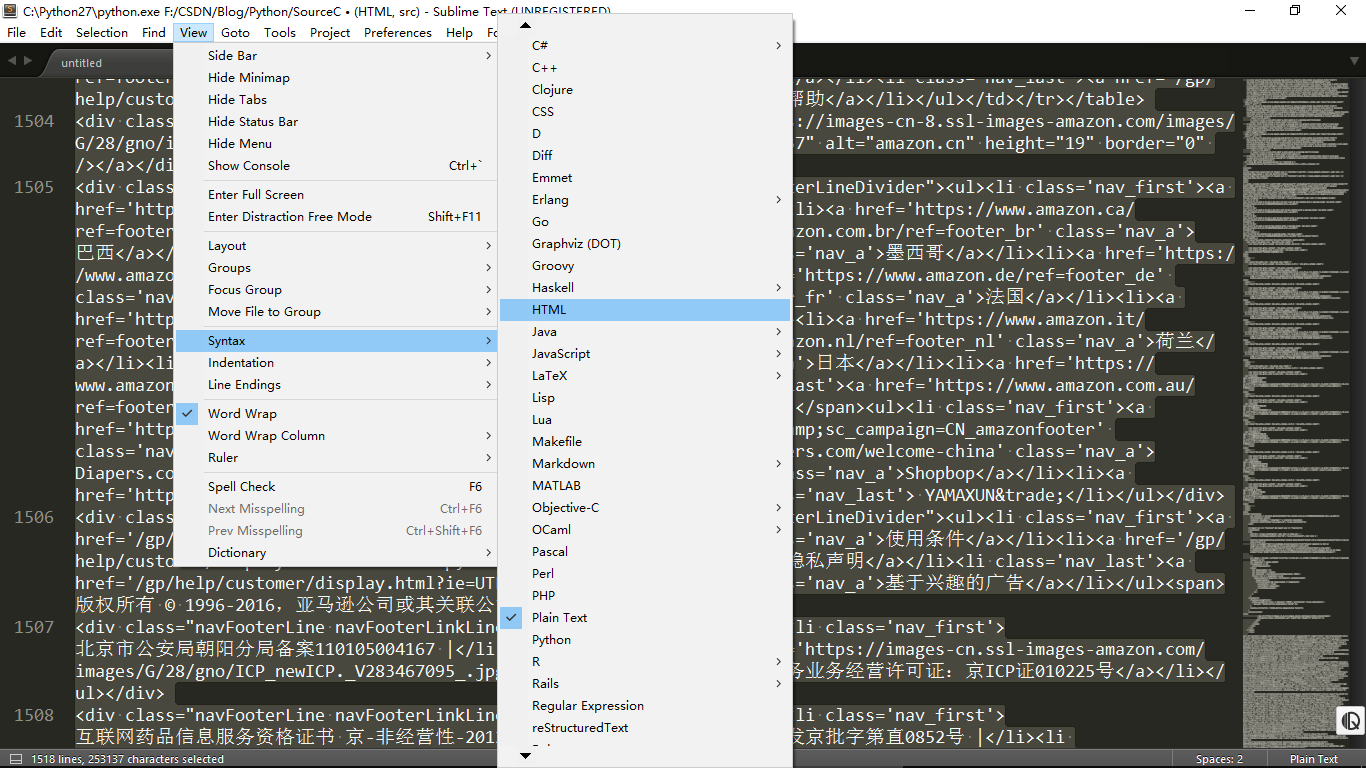
接着就是关键的一步了,用正则表达式获取Kindle商店的URL。
我们先来看看亚马逊首页,我们在首页是这样访问Kindle商店的:

所以我们直接在sublime里面搜索“Kindle 商店”(注意中间的空格不能少),然后我们来到这里:
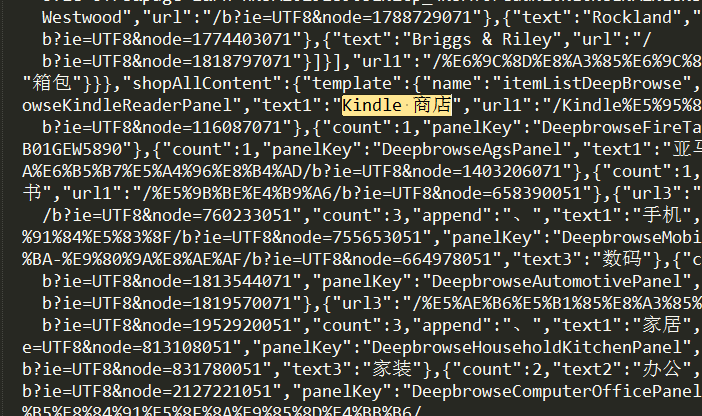
我们获取的就是后面“url1”的内容,所以我们写如下正则表达式:
Python的正则表达式很简单:
1. re.compile(string, flags)创建模式,pattern一般用re.S(多行选择)
2. re.search(pattern, string)根据模式在string中匹配到则停止
3. re.findall(pattern, string)返回一个List,里面包含所有符合的子字符串
4. 常用的字符: “.”代表任意字符, “*”代表个数为任意个, “?”代表零次或一次匹配前面的字符或子表达式, 括号”()”内的则为返回内容
# -*-coding:utf-8-*-
import urllib2
import re # Python 中正则表达式模块
url = 'https://www.amazon.cn/'
response = urllib2.urlopen(url)
# 创建模板,并且使用re.S即多行匹配
KindlePattern = re.compile('Kindle 商店.*?url1":"(.*?)"', re.S)
# 使用re.search(pattern, string)在string中寻找pattern匹配的内容
# 注意group(1) 下面会有详细的解释
KindleURL = url + re.search(KindlePattern, response.read()).group(1)
print KindleURLgroup(): 仅在search后有效,findall无group()
group(0)表示匹配到的所有内容
group(1)表示第一个(.*?)所返回的内容,2则表示第二个,依此类推
response = urllib2.urlopen(url)
KindlePattern = re.compile('Kindle 商店.*?url1":"(.*?)"', re.S)
info = re.search(KindlePattern, response.read())
print info.group(0)访问Kindle商店,获取“今日特价书”URL
上面我们知道了Kindle商店的URL,现在我们来获取今日特价书的URL
response = urllib2.urlopen(KindleURL)
print response.read()然后继续上面的步骤,将网页源码放入sumlime,搜索“今日特价书”,然后发现得到一个<a>标签:
<a href="/gp/feature.html?ie=UTF8&docId=126758">今日特价书</a>
我们来提取一下
KindleURL = url + re.search(KindlePattern, response.read()).group(1)
response = urllib2.urlopen(KindleURL)
discountPattern = re.compile('什么值得读.*?href="(.*?)">今日特价书', re.S)
bookURL = url + re.search(discountPattern, response.read()).group(1)
print bookURL很好,我们要爬的页面终于出来了:
https://www.amazon.cn//gp/feature.html?ie=UTF8&docId=126758
等等, 这里的URL好像有点不对…cn后面怎么是"//"?
原来我们的变量url多了一个"/"把url末尾的斜杠删除就好了,不过删不删除问题不大,毕竟不影响访问
分析今日特价书的页面,获取书的详细信息
老方法获取页面的源码:
response = urllib2.urlopen(bookURL)
print response.read()然后使用sublime分析页面,再用sublime查找,写出正则表达式
infoPattern = re.compile('productImage">.*?href="(.*?)".*?src="(.*?)".*?productTitle">.*?>(.*?)<.*?productByLine">(.*?)<.*?a-color-price">(.*?)<',re.S)
infos = re.findall(infoPattern, response.read())
for info in infos:
print '链接:' + url + info[0].strip('\n')
print '图片地址:' + info[1].strip('\n')
print '书名:' + info[2].strip('\n')
print '作者:' + info[3].strip('\n')
print '价格: ' + info[4].strip('\n')strip表示去掉特定字符
我们得到的结果是:
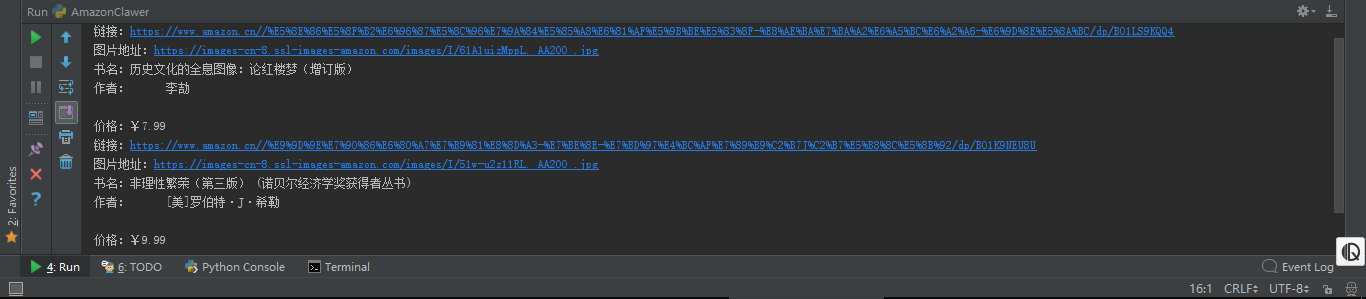
看起来有点丑, 原因是在response.read()中,记录了作者的相应源码是这样的(未经过sublime格式化)
<div class="productByLine">
[美]罗伯特·J·希勒
</div>我们想要获得纯文本,就要将选择作者的正则进行修改了。
\S表示非空白文本,\s表示空白文本。
+表示匹配前一个字符1-∞次
修改的片段:
productByLine">\s+(.*?)\s*?<.*?a-color-price"图片的获取
在上面我们已经得到书本图片的URL,接下来要做的就是把图片保存
urllib2将网页封装成类似文件的格式,所以图片保存的过程就像从一个文件中读取然后打开另一个文件写入一样简单
在for循环后插入这段代码
imgURL = info[1].strip('\n') # 获得图片链接
imgNamePattern = re.compile('/I/(.*?)jpg',re.S) # 用正则表达式提取图片名称
imgName = re.search(imgNamePattern, imgURL) # 提取图片名称
response = urllib2.urlopen(imgURL) # 打开图片链接
with open(imgName.group(1)+'jpg', 'wb') as file: # 以二进制写方式打开
file.write(response.read()) # 写入文件可能你已经注意到了,为什么要用'/I/(.?)jpg'作为正则模板?为什么不能直接用'I/(.?)'
正则表达式中不能直接提取到字符串结束,否则会报错,这是刚刚在写这段代码的时候发现的,所以我们选择jpg为终结标志
现在去文件夹看看,发现两本书的图片都已经有了

开发环境:
- Python2.7
- Windows10















 639
639

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









