







目录
前言
经过初赛的筛选后,我们就进入了复赛(名副其实的废话)。接下来我简单介绍下我们队伍参加复赛一些情况吧。复赛相对初赛而言题目针对性比较强,所以对于比赛之外的人而言没啥可以学习的地方。因此我这里只记录一些开发过程中的一些体会,至于我们队伍的代码上的一些细节(处理流程、索引结构等),有兴趣的可以直接去看源码,这样会更清楚些。
正文
题目分析
复赛的任务就是对几个淘宝的订单文件建立索引,最后实现几个查询接口,索引构建过程、索引的结构、查询的过程以及缓存策略都是自己来控制。可以参考开源的Nosql数据库的设计,但不能直接使用非工具类的第三方库。
程序的运行分为两个阶段,准备阶段与查询阶段, 每个阶段各限时一小时。
业务方需要选手支持下面几种查询方法:
- 提供交易ID,查询某次交易的某些属性
- 查询某位买家某个时间范围内的所有交易 信息,输出结果按交易时间从大到小排列
- 查询某个商品的全部交易订单,输出结果 按交易订单号从小到大排序
- 对某个商品的所有交易信息进行求和
索引设计
我们队伍最终使用的是二级索引,由于内容较多,在此只列出orderid的索引结构图:
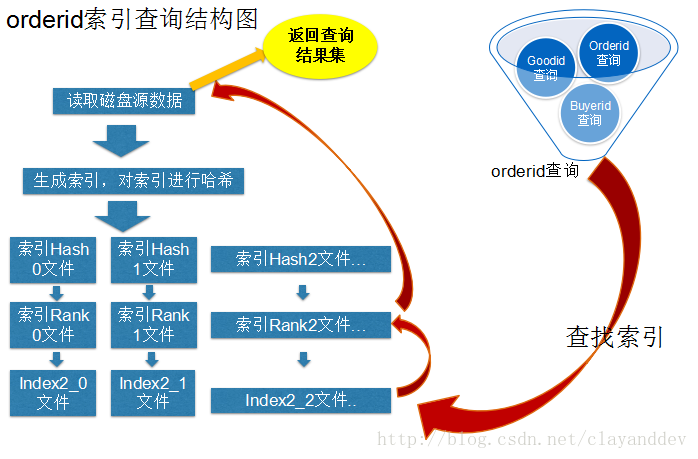
对此感兴趣的朋友可以直接去看我们队伍的答辩ppt,里边就有详细的介绍。
代码展示
详见代码仓库
关键优化
- 索引构建过程中,单线程读写->多线程读写->读写分离
- 不对原始文件hash,而是只对索引进行hash(性能提高了5倍左右,达到了一个新的里程碑
) - 加快范围查询
- 一、二级索引放磁盘 =》二级索引存Cache =》二级索引treemap格式存Cache =》根据hash后文件排序
- 优化一级索引查询
- 缩减为一次读盘
- 源数据的cache选择
为了减少询盘,充分利用内存 : FIFO策略 =》无替换cache good表 =》无替换cache buyer表
- 其他一些优化手段
- 使用stringtokennizer代替split
- 优化RandomAccessFile的readline方法,减少硬盘io
- 压缩重复数据,减少对内存的占用
后记
感悟:
- 抓住主要瓶颈点,再去优化细节,往往解决一个大的瓶颈点,便是一个里程碑。而细节则会起到锦上添花的作用。
- 复赛在最后一刻冲到了第一的位置,然后在答辩时却被复赛第二名的队伍反超,只获得了亚军。虽然没能拿到“全场最佳”,但对于这样的结果我也已经很满意了。冠军队伍确实厉害,对赛题进行了系统的分析与架构设计,而我们的大部分代码都是跟着感觉走,这应该就是我们两队的差距了。所以从这次比赛中,我最大的感悟就是码代码真的不能再只跟着感觉走了,一定要系统地进行分析,充分利用所有能够利用的资源,这样的码代码姿势才是最正确的。















 4814
4814

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









