







参考译本,第四章:Solver
第一节
作用:
协调Net的前向推断计算和反向梯度计算,更新参数,从而减小loss。
(Net具有计算的作用,Solver定义了用什么方法优化整个网络。)
3点应用:
(1)记录优化过程;(快照)
(2)创建训练网络;(学习)
(3)创建测试网络;(评估)
6个支持:
SGD, AdaDelta, AdaGrad, Adam, Nesterov, RMSProp
每次迭代过程中:
(1)调用Net的Forward和Backword,计算该计算的,输出、loss(Forword),梯度▽(Backword loss对权中w和偏置b求导)。
(2)更新参数,更新solver状态。
第二节
Solver的trick
mini-batch近似代替平均损失L(W):
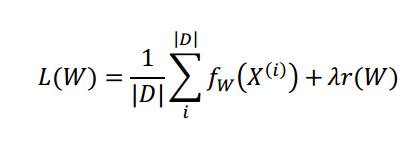
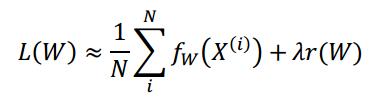
N是随机子集,N远远小于|D|。
第三节
SGD
1.SGD的出发点;
2.各种SGD的家族成员;
3.稀疏(Sparsity)提高效率,但要改公式;
4.大杀器,Krizhevsky如何设置参数,学习率变化因子。
5.基本原则
官方译本中的重要段落:

学习率α 和动量μ 要怎么设?参见待会儿的第4点,这里先形象的说下SGD的概念。
1.SGD的出发点
GD就是梯度下降,SGD就是GD的无偏估计。所谓无偏估计就是当样本数量足够大,估计值求出来就等于期望值。
GD和SGD的对比:
GD: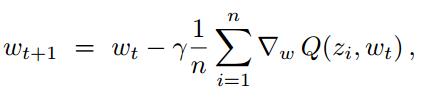
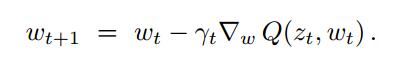
Q(z,w)函数里z是样本,w是权值,z包括x(输入)和y(label),Q就是损失函数(代价函数);
这里是用损失函数的导数,也就是梯度来更新w,这个就是最速下降的出发点了。在w的域中,找到最能减少损失函数Q(z,w)的方向,然后往这个方向走,直到求得一个理想中很小的Q(z,w),停下来此时的w就是一个理想的W,但不一定是最优的W。理想和最优有一个误差error_opt,通过增加运行时间可以减少它。
SGD的特点是每次更新只需要单个样本zt 就能完成,也就是利用了无偏估计,这里可以细细想一想,博主也是只可意会,而写不出公式(摊手~)。这样能大大减少每次迭代的时间,不用再循环整个样本集了。
2.SGD的家族成员
(1)应用L2正则化:
形式:
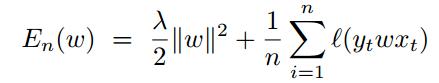
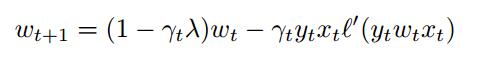
上式就是代价函数,求导丢到等号右边,Wt+1 = Wt - 右边,整理得到得到下式。
其中y=±1, l(m)是凸函数, w正则化以后,保证En(w)也是凸函数。
(2)ASGD 平均随机梯度下降:
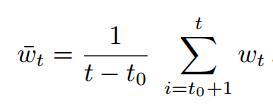
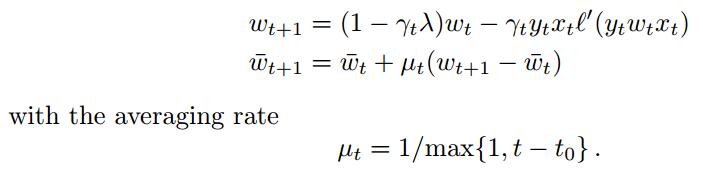
这个平均权值是在迭代一定次数后开始计算的,博主有点不明具体操作,权当一种优化思路。
初始化的Trick:
这里μt 才有这种方法初始化,d是样本维度,n是样本集大小,是因为无法确定t0的值, 所以这用了经验值。
3.稀疏(Sparsity)
稀疏能加快输入x 相关的计算,思路是用st Wt代替wt , 如下:
SGD的稀疏变化:
原本形式:
稀疏形式:
我们看到Wt+1的右边只有和xt 相关的乘积运算,而减少了上式(1-γtλ)wt 的乘积,这样就能利用稀疏,大大减少运算量。
ASGD同理:
替换后:
对应命名的含义:
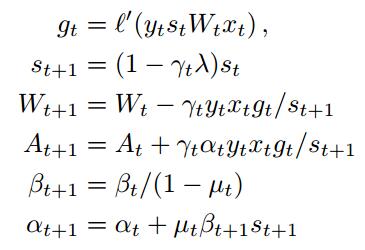
4.Trick相关,Krizevsky的做法
我们面对Caffe的solver配置是这样的:

理解每一项为什么这么设,首先参考:
A. Krizhevsky, I. Sutskever, and G. Hinton. ImageNet Classification with Deep Convolutional Neural Networks Advances in Neural Information Processing Systems, 2012.
第5节 Detail of learning中说到 weight decay这个秘密, caffe提供并且实现了,就是solver prototxt中的gamma,官方译本给的就是论文中说的设置:
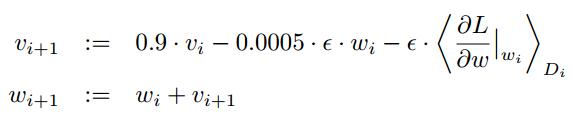
学习率是如何设置的?在稍后第5节中说到。
5. 基本原则
来自 Leon Bottou 论文 L. Bottou. Stochastic Gradient Descent Tricks. Neural Networks: Tricks of the Trade: Springer, 2012
(1)准备数据
①打乱样本顺序
②预处理避免调入局部而死机
(2)监测、调试
③学习时(训练时)周期性地检查验证集上的误差和训练集的代价。
④用程序检查梯度是否计算准确,而不是肉眼去看。
⑤用小数据去检查γt 学习率是否合适。由于小样本集跑出的学习率γ可以当作大样本集的无偏估计,所以先用小样本跑出学习率,再设一个稍微小一点的学习率作为大样本的学习率的初始值。
完,希望能给读者带来启发。














 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









