







1 梯度下降法GD
梯度下降法(Gradient descent )是一个一阶最优化算法,通常也称为最陡下降法 ,要使用梯度下降法找到一个函数的局部极小值 ,必须向函数上当前点对应梯度(或者是近似梯度)的反方向的规定步长距离点进行迭代搜索。 如果相反地向梯度正方向迭代进行搜索,则会接近函数的局部极大值点;这个过程则被称为梯度上升法 ,相反则称之为梯度下降法。计算公式如下:
θ=θ−α∗∇J(θ)
缺点:
(1)传统的梯度下降将计算整个数据集梯度,但只会进行一次更新,因此在处理大型数据集时速度很慢且难以控制,甚至导致内存溢出。
(2)权重更新的快慢是由学习率η决定的,并且可以在凸面误差曲面中收敛到全局最优值,在非凸曲面中可能趋于局部最优值。
(3)使用标准形式的批量梯度下降还有一个问题,就是在训练大型数据集时存在冗余的权重更新。
2 随机梯度下降法 SGD
优点:
随机梯度下降对每个训练样本进行参数更新,每次执行都进行一次更新,且执行速度更快。频繁的更新使得参数间具有高方差,损失函数会以不同的强度波动。这实际上是一件好事,因为它有助于我们发现新的和可能更优的局部最小值,而标准梯度下降将只会收敛到某个局部最优值。
缺点:
如图所示,每个训练样本中高方差的参数更新会导致损失函数大幅波动,因此我们可能无法获得给出损失函数的最小值。只能获得在一定区间波动的损失值。

需要注意的是有必要随迭代步数,逐渐降低学习率。一种常见从做法是线性衰减学习率,直到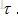
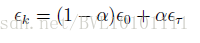
其中 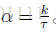
3 批量梯度下降
为了避免方法12下降中存在的问题,一个改进方法为小批量梯度下降(Mini Batch Gradient Descent),对每个批次中的n个训练样本执行一次更新(mini-batch本质上使用的也是SGD)。
优点:
(1)可以减少参数更新的波动,最终得到效果更好和更稳定的收敛。
(2)可以使用最新的深层学习库中通用的矩阵优化方法,使计算小批量数据的梯度更加高效。在训练神经网络时,通常都会选择小批量梯度下降算法。
(3)通常来说,小批量样本的大小范围是从50到256,可以根据实际问题而有所不同。
使用梯度下降及其变体时面临的挑战
(1)很难选择出合适的学习率。太小的学习率会导致网络收敛过于缓慢,而学习率太大可能会影响收敛,并导致损失函数在最小值上波动,甚至出现梯度发散。
(2)相同的学习率并不适用于所有的参数更新。如果训练集数据很稀疏,且特征频率非常不同,则不应该将其全部更新到相同的程度,但是对于很少出现的特征,应使用更大的更新率。
(3)在神经网络中,最小化非凸误差函数的另一个关键挑战是避免陷于多个其他局部最小值中。实际上,问题并非源于局部极小值,而是来自鞍点,即一个维度向上倾斜且另一维度向下倾斜的点。这些鞍点通常被相同误差值的平面所包围,这使得SGD算法很难脱离出来,因为梯度在所有维度上接近于零。
Batch-Size选择
Batch 的选择,首先决定的是下降的方向。如果数据集比较小,完全可以采用全数据集 ( Full Batch Learning )的形式,这样做至少有 2 个好处:其一,由全数据集确定的方向能够更好地代表样本总体,从而更准确地朝向极值所在的方向。其二,由于不同权重的梯度值差别巨大,因此选取一个全局的学习率很困难。 Full Batch Learning 可以使用 Rprop 只基于梯度符号并且针对性单独更新各权值。
对于更大的数据集,以上 2 个好处又变成了 2 个坏处:其一,随着数据集的海量增长和内存限制,一次性载入所有的数据进来变得越来越不可行。其二,以 Rprop 的方式迭代,会由于各个 Batch 之间的采样差异性,各次梯度修正值相互抵消,无法修正。这才有了后来 RMSProp 的妥协方案。
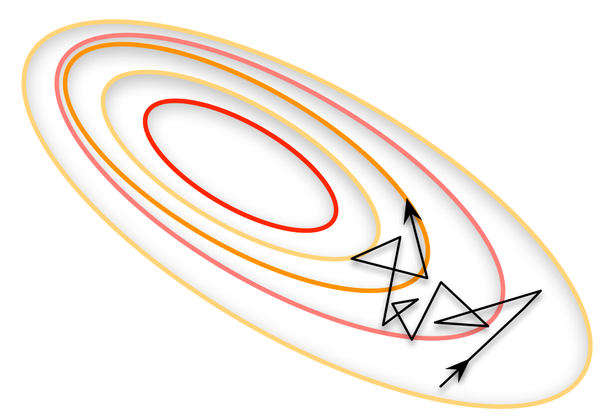
Full Batch Learning ,并不适合大数据集,如果走向另一个极端,就是每次只训练一个样本,即 Batch_Size = 1。就退化到了SGD算法,这就是在线学习(Online Learning)。线性神经元在均方误差代价函数的错误面是一个抛物面,横截面是椭圆。对于多层神经元、非线性网络,在局部依然近似是抛物面。使用在线学习,每次修正方向以各自样本的梯度方向修正,横冲直撞各自为政,难以达到收敛。如图所示:
4 动量梯度下降法
动量梯度下降法运行速度几乎总是快于标准的梯度下降算法。例如,如果你要优化成本函数,函数形状如下图,红点代表最小值的位置,假设你从这里(蓝色点)开始梯度下降法,如果进行梯度下降法的一次迭代,无论是batch或mini-batch下降法,最后会指向这里红色点,但你会发现梯度下降法要走很多步骤?

如果你要用较大的学习率(紫色箭头),结果可能会偏离函数的范围,为了避免摆动过大,你要用一个较小的学习率。另一个看待问题的角度是,在纵轴上,你希望学习慢一点,因为你不想要这些摆动,但是在横轴上,你希望加快学习,你希望快速从左向右移,移向最小值,移向红点。
SGD方法中的高方差振荡使得网络很难稳定收敛,所以有研究者提出了一种称为动量(Momentum)的技术,通过优化相关方向的训练和弱化无关方向的振荡(上图中就是强化横轴方向训练),来加速SGD训练。动量算法引入了变量 v 充当速度角色——它代表参数在参数空间移动的方向和速率。速度被设为负梯度的指数衰减平均。名称动量(momentum)。


5 Nesterov梯度加速法
一位名叫Yurii Nesterov研究员,认为动量方法存在一个问题:
如果一个滚下山坡的球,盲目沿着斜坡下滑,这是非常不合适的。一个更聪明的球应该要注意到它将要去哪,因此在上坡再次向上倾斜时小球应该进行减速。
实际上,当小球达到曲线上的最低点时,动量相当高。由于高动量可能会导致其完全地错过最小值,因此小球不知道何时进行减速,故继续向上移动。
Yurii Nesterov在1983年发表了一篇关于解决动量问题的论文,因此,我们把这种方法叫做Nestrov梯度加速法。
在该方法中,他提出先根据之前的动量进行大步跳跃,然后计算梯度进行校正,从而实现参数更新。这种预更新方法能防止大幅振荡,不会错过最小值,并对参数更新更加敏感。
Nesterov梯度加速法(NAG)是一种赋予了动量项预知能力的方法,通过使用动量项γV(t−1)来更改参数θ。通过计算θ−γV(t−1),得到下一位置的参数近似值,这里的参数是一个粗略的概念。因此,我们不是通过计算当前参数θ的梯度值,而是通过相关参数的大致未来位置,来有效地预知未来:
方法4:V(t)=γV(t−1)+η∇(θ)J(θ),然后使用θ=θ−V(t)来更新参数。
方法5:V(t)=γV(t−1)+η∇(θ)J( θ−γV(t−1) ),然后使用θ=θ−V(t)来更新参数。
现在,我们通过使网络更新与误差函数的斜率相适应,并依次加速SGD,也可根据每个参数的重要性来调整和更新对应参数,以执行更大或更小的更新幅度。
1.Nesterov是Momentum的变种。
2.与Momentum唯一区别就是,计算梯度的不同,Nesterov先用当前的速度v更新一遍参数,在用更新的临时参数计算梯度。
3.相当于添加了矫正因子的Momentum。
4.在GD下,Nesterov将误差收敛从O(1/k),改进到O(1/k^2)
5.然而在SGD下,Nesterov并没有任何改进

6 Adagrad
Adagrad方法是通过历史梯度平方和来调整合适的学习率η,对稀疏参数进行大幅更新和对频繁参数进行小幅更新。因此,Adagrad方法非常适合处理稀疏数据。

Adagrad方法是在每个时间步中,根据过往已计算的参数梯度,来为每个参数θ(i)修改对应的学习率η。
Adagrad方法的主要好处是,不需要手工来调整学习率。大多数参数使用了默认值0.01,且保持不变。
Adagrad方法的主要缺点是,学习率η总是在降低和衰减。
因为每个附加项都是正的,在分母中累积了多个平方梯度值,故累积的总和在训练期间保持增长。这反过来又导致学习率下降,变为很小数量级的数字,该模型完全停止学习,停止获取新的额外知识。
因为随着学习速度的越来越小,模型的学习能力迅速降低,而且收敛速度非常慢,需要很长的训练和学习,即学习速度降低。 另一个叫做Adadelta的算法改善了这个学习率不断衰减的问题。
AdaGrad算法实现步骤:
 7 RMSProp
7 RMSProp
先抛出AdaGrad算法:
1.AdaGrad算法的改进。鉴于神经网络都是非凸条件下的,RMSProp在非凸条件下结果更好,改变梯度累积为指数衰减的移动平均以丢弃遥远的过去历史。
2.经验上,RMSProp被证明有效且实用的深度学习网络优化算法。
相比于AdaGrad的历史梯度:

RMSProp增加了一个衰减系数来控制历史信息的获取多少:


直观理解作用
简单来讲,设置全局学习率之后,每次通过,全局学习率逐参数的除以经过衰减系数控制的历史梯度平方和的平方根,使得每个参数的学习率不同
那么它起到的作用是什么呢?
起到的效果是在参数空间更为平缓的方向,会取得更大的进步(因为平缓,所以历史梯度平方和较小,对应学习下降的幅度较小),并且能够使得陡峭的方向变得平缓,从而加快训练速度。
下面通过例子讲解一下:
假设我们现在采用的优化算法是最普通的梯度下降法mini-batch。它的移动方向如下面蓝色所示:

假设我们现在就只有两个参数w,b,我们从图中可以看到在b方向走的比较陡峭,这影响了优化速度。
而我们采取AdaGrad算法之后,我们在算法中使用了累积平方梯度:

从上图可以看出在b方向上的梯度g要大于在w方向上的梯度。
那么在下次计算更新的时候,r是作为分母出现的,越大的反而更新越小,越小的值反而更新越大,那么后面的更新则会像下面绿色线更新一样,明显就会好于蓝色更新曲线。

在参数空间更为平缓的方向,会取得更大的进步(因为平缓,所以历史梯度平方和较小,对应学习下降的幅度较小),并且能够使得陡峭的方向变得平缓,从而加快训练速度。
这就是RMSProp优化算法的直观好处。
再看看结合Nesterov动量的RMSProp,直观上理解就是:
RMSProp改变了学习率,Nesterov引入动量改变了梯度,从两方面改进更新方式。
7 AdaDelta方法
这是一个AdaGrad的延伸方法,它倾向于解决其学习率衰减的问题。Adadelta不是累积所有之前的平方梯度,而是将累积之前梯度的窗口限制到某个固定大小w。
与之前无效地存储w先前的平方梯度不同,梯度的和被递归地定义为所有先前平方梯度的衰减平均值。作为与动量项相似的分数γ,在t时刻的滑动平均值Eg²仅仅取决于先前的平均值和当前梯度值。
Eg²=γ.Eg²+(1−γ).g²(t),其中γ设置为与动量项相近的值,约为0.9。
Δθ(t)=−η⋅g(t,i).
θ(t+1)=θ(t)+Δθ(t)

图4:参数更新的最终公式
AdaDelta方法的另一个优点是,已经不需要设置一个默认的学习率。
目前已完成的改进
1) 为每个参数计算出不同学习率;
2) 也计算了动量项momentum;
3) 防止学习率衰减或梯度消失等问题的出现。
还可以做什么改进?
在之前的方法中计算了每个参数的对应学习率,但是为什么不计算每个参数的对应动量变化并独立存储呢?这就是Adam算法提出的改良点。
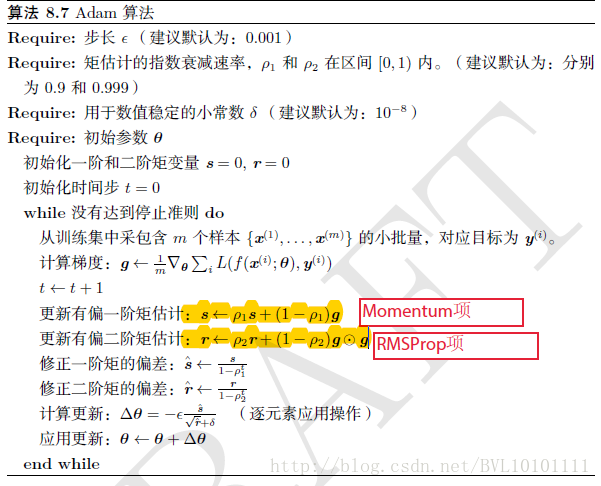
7 Adam
先上结论:
1.Adam算法可以看做是修正后的Momentum+RMSProp算法
2.动量直接并入梯度一阶矩估计中(指数加权)
3.Adam通常被认为对超参数的选择相当鲁棒
4.学习率建议为0.001
再看算法:其实就是Momentum+RMSProp的结合,然后再修正其偏差。
对优化算法进行可视化

从上面的动画可以看出,自适应算法能很快收敛,并快速找到参数更新中正确的目标方向;而标准的SGD、NAG和动量项等方法收敛缓慢,且很难找到正确的方向。
结论
我们应该使用哪种优化器?
在构建神经网络模型时,选择出最佳的优化器,以便快速收敛并正确学习,同时调整内部参数,最大程度地最小化损失函数。
Adam在实际应用中效果良好,超过了其他的自适应技术。
如果输入数据集比较稀疏,SGD、NAG和动量项等方法可能效果不好。因此对于稀疏数据集,应该使用某种自适应学习率的方法,且另一好处为不需要人为调整学习率,使用默认参数就可能获得最优值。
如果想使训练深层网络模型快速收敛或所构建的神经网络较为复杂,则应该使用Adam或其他自适应学习速率的方法,因为这些方法的实际效果更优。














 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









