







梯度下降法通常分为三类:
(1)批量梯度下降法:每次训练输入全部数据,能够考虑全部样本的梯度,获取到准确的梯度,但比较耗时,并且输入全部数据,可能内存或GPU装不下;
(2)随机梯度下降法:每次随机选择一个样本进行训练,使用一个样本的梯度进行下降。比(1)快很多,也不占内存,但可能不会收敛;
(3)mini-batch梯度下降法:为了每次训练尽可能的多输入一些样本,同时又不会太耗时和超内存,mini-batch将训练样本分为多个批次,一个一个的输入,最后将多个输入的结果进行平均,即得到一次完整训练的梯度。
这里:常见的iteration就是指分批的数量,batch_size就是每批的大小,epochs是指训练的轮数。
batch_size是不是越大越好?
结论:不是。
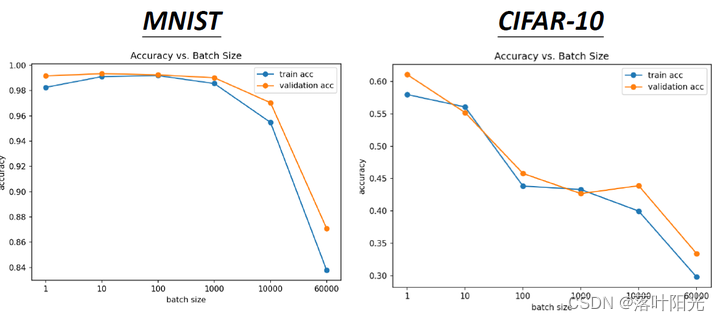
原因:
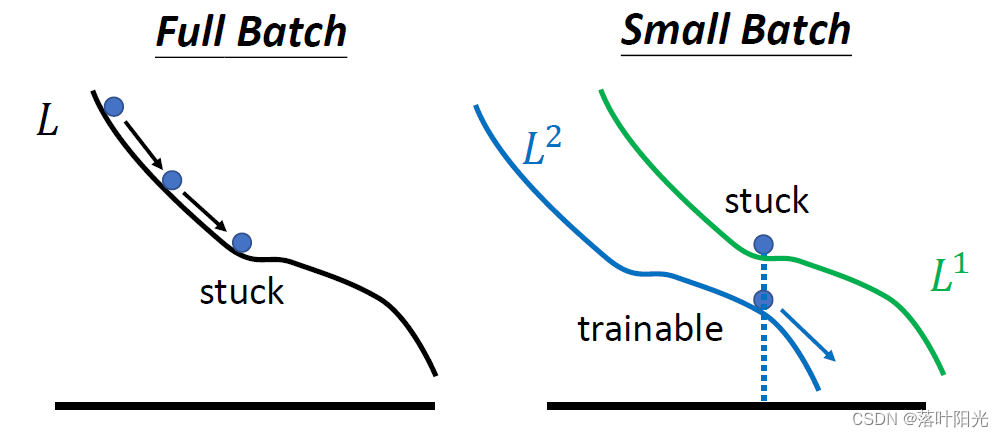
越大的batch可能导致算法训练约容易陷入鞍点,而稍微小一点batch_size的数据可以使loss走出鞍点,进行继续训练。
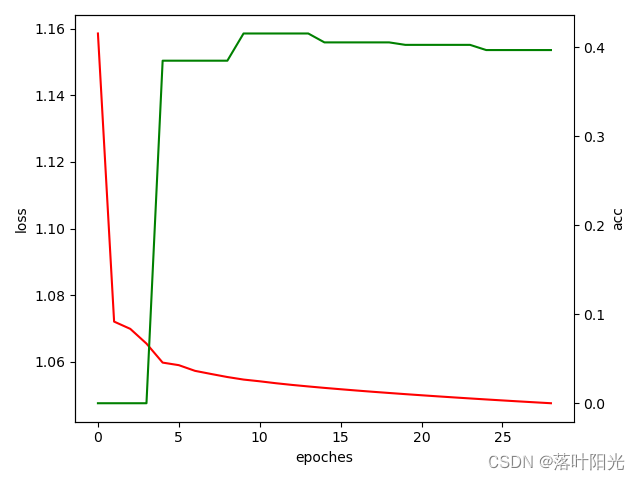
实例:
batch_size=2512:,此时GPU利用7.3G/8G,对GPU的利用率非常高,训练也很快,可以看到算法训练已经开始在收敛了,而此时的loss还是比较高的,而ACC比较低。判断算法训练陷入了鞍点。
batch_size=1024
batch_size=512
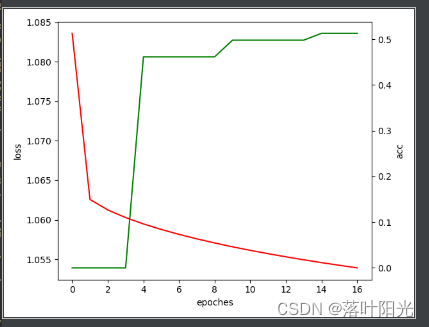
batch_size=176,算法训练还未收敛,而此时模型性能还在提升。
batch_size设置多大合适?
batch_size
个人经验是根据一轮训练数据的大小来定:首先的一个原则就是选择2的倍数,如常见的256,1024,2048,4056,8192,16384,32768,65536,原因似乎是GPU或内存对2的倍数处理更高效一些。
另一个原则是从大到小的进行挑选,同时保证全部批次能够尽可能的用到全部数据,为什么说尽可能,就是说,可能训练数据会多出一部分,而这部分又不够一批,所以,这部分的数据是训练不到的。
举例:对于数量为1127762的训练数据,若采用batch_size=65536,那么可以分为17批,还有13650的数据训练不到。若采用batch_size=8192,则可以分为137批,剩5438个。(选择batch_size时都可以这样算一下)
可能你也看出来了,batch_size越大,批次越少,训练时间会更快一点,但可能造成数据的很大浪费;而batch_size越小,对数据的利用越充分,浪费的数据量越少,但批次会很大,训练会更耗时。
所以,第三个原则就是,数据量非常大时,选择比较大的batch_size,注意不要超出内存限制;数据量比较少的,则选择小一点的batch_size。















 13万+
13万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









