







 本文介绍了深度神经网络在有道云笔记文档扫描功能中的应用,主要使用全卷积网络(FCN)进行文档区域识别。通过调整损失函数解决类别不平衡问题,并分享了数据筛选、模型训练和移动端实现的策略。最终在移动端实现了高效且准确的文档扫描功能。
本文介绍了深度神经网络在有道云笔记文档扫描功能中的应用,主要使用全卷积网络(FCN)进行文档区域识别。通过调整损失函数解决类别不平衡问题,并分享了数据筛选、模型训练和移动端实现的策略。最终在移动端实现了高效且准确的文档扫描功能。
声明:本文来自有道技术团队的投稿,交流可致邮:ydtech@rd.netease.com
责编:钱曙光(qianshg@csdn.net)
欢迎加入CSDN人工智能技术交流QQ群(群号:299059314),内涵大量学习材料。
随着深度学习算法在图像领域中的成功运用,学术界的目光重新回到神经网络上;而随着 AlphaGo 在围棋领域制造的大新闻,全科技界的目光都聚焦在“深度学习”、“神经网络”这些关键词上。与大众的印象不完全一致的是,神经网络算法并不算是十分高深晦涩的算法;相对于机器学习中某一些数学味很强的算法来说,神经网络算法甚至可以算得上是“简单粗暴”。只是,在神经网络的训练过程中,以及算法的实际运用中,存在着许多困难,和一些经验,这些经验是比较有技巧性的。
有道云笔记不久前更新的文档扫描功能中使用了神经网络算法。本文试图以文档扫描算法中所运用的神经网络算法为线索,聊一聊神经网络算法的原理,以及其在工程中的应用。
背景篇
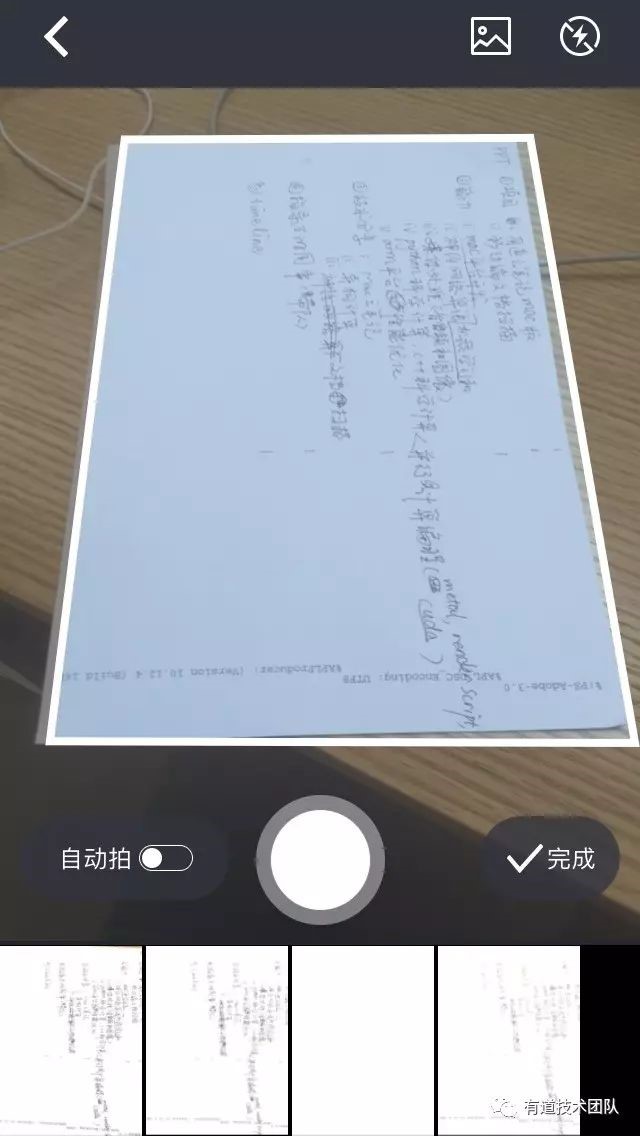
首先介绍一下什么是文档扫描功能。文档扫描功能希望能在用户拍摄的照片中,识别出文档所在的区域,进行拉伸(比例还原),识别出其中的文字,最终得到一张干净的图片或是一篇带有格式的文字版笔记。实现这个功能需要以下这些步骤:
- 识别文档区域
将文档从背景中找出来,确定文档的四个角; - 拉伸文档区域,还原宽高比
根据文档四个角的坐标,根据透视原理,计算出文档原始宽高比,并将文档区域拉伸还原成矩形。这是所有步骤中唯一具有解析算法的步骤; - 色彩增强
根据文档的类型,选择不同的色彩增强方法,将文档图片的色彩变得干净清洁; - 布局识别
理解文档图片的布局,找出文档的文字部分; - OCR
将图片形式的“文字”识别成可编码的文字; - 生成笔记
根据文档图片的布局,从 OCR 的结果中生成带有格式的笔记。

在上述这些步骤中,“拉伸文档区域”和“生成笔记”是有解析算法或明确规则的,不需要机器学习处理。剩下的步骤中都含有机器学习算法。其中“文档区域识别”和“OCR”这两个步骤我们是采用深度神经网络算法来完成的。
之所以在这两个步骤选择深度神经网络算法,是考虑到其他算法很难满足我们的需求:
- 场景复杂,浅层学习很难很好的学习推广;
同时,深度神经网络的一些难点在这两个步骤中相对不那么困难
- 属于深度神经网络算法所擅长的图像和时序领域;
- 能够获取到大量的数据。能够对这些数据进行明确的标注。
接下来的内容中,我们将展开讲讲“文档区域识别”步骤中的神经网络算法。
算法篇
文档区域识别中使用的神经网络算法主要是全卷积网络(FCN)[1]。在介绍 FCN 前,首先简单介绍一下 FCN 的基础,卷积神经网络(这里假设读者对人工神经网络有最基本的了解)。
卷积神经网络(CNN, Convolutional Neural Networks)
卷积神经网络(CNN)早在 1962 年就被提出[2],而目前最广泛应用的结构大概是 LeCun 在 1998 年提出的[3]。CNN 和普通神经网络一样,由输入、输出层和若干隐层组成。CNN 的每一层并不是一维的,而是有(长, 宽, 通道数)三个维度,例如输入层为一张 rgb 图片,则其输入层三个维度分别是(图片高度, 图片宽度, 3)。
与普通神经网络相比,CNN 有如下特点:
- 第 n 层的某个节点并不和第
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 7228
7228

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









