







Evaluating a Learning Algorithm
先来看一个有正则的线性回归例子:

当在预测时,有很大的误差,该如何处理?

1.得到更多的训练样本
2.选取少量的特征
3.得到更多的特征项
4.加入特征多项式
5.减少正则项系数 λ
6.增加正则项系数 λ
很多人,在遇到预测结果并不理想的时候,会凭着感觉在上面的6个方案中选取一个进行,但是往往花费了大量时间却得不到改进。
于是引入了机器学习诊断,在后面会详细阐述,

怎样用你学过的算法来评估假设函数 ,讨论如何避免 过拟合和欠拟合的问题。
对于这个简单的例子,我们可以对假设函数 hθ(x) 进行画图 ,然后观察图形趋势, 但对于特征变量不止一个的这种一般情况 ,还有像有很多特征变量的问题 想要通过画出假设函数来进行观察,就会变得很难甚至是不可能实现。因此, 我们需要另一种方法来评估我们的假设函数 。
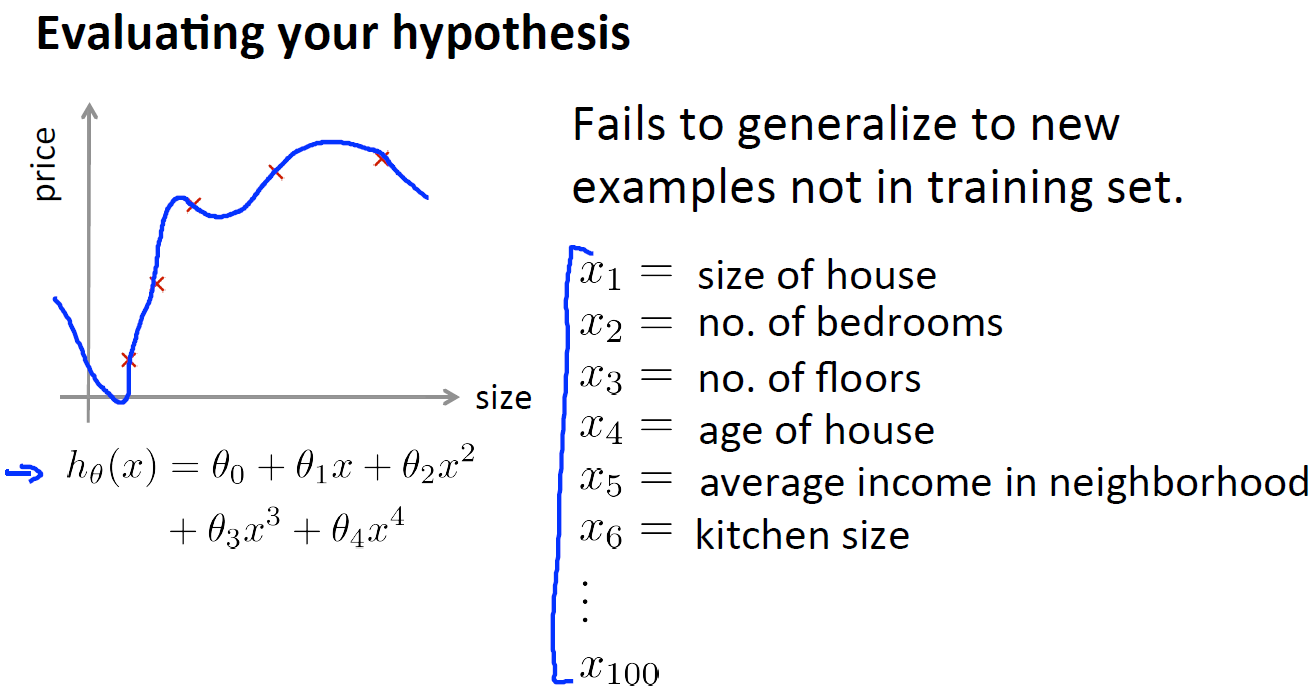
如下,给出了一种评估假设函数的标准方法:
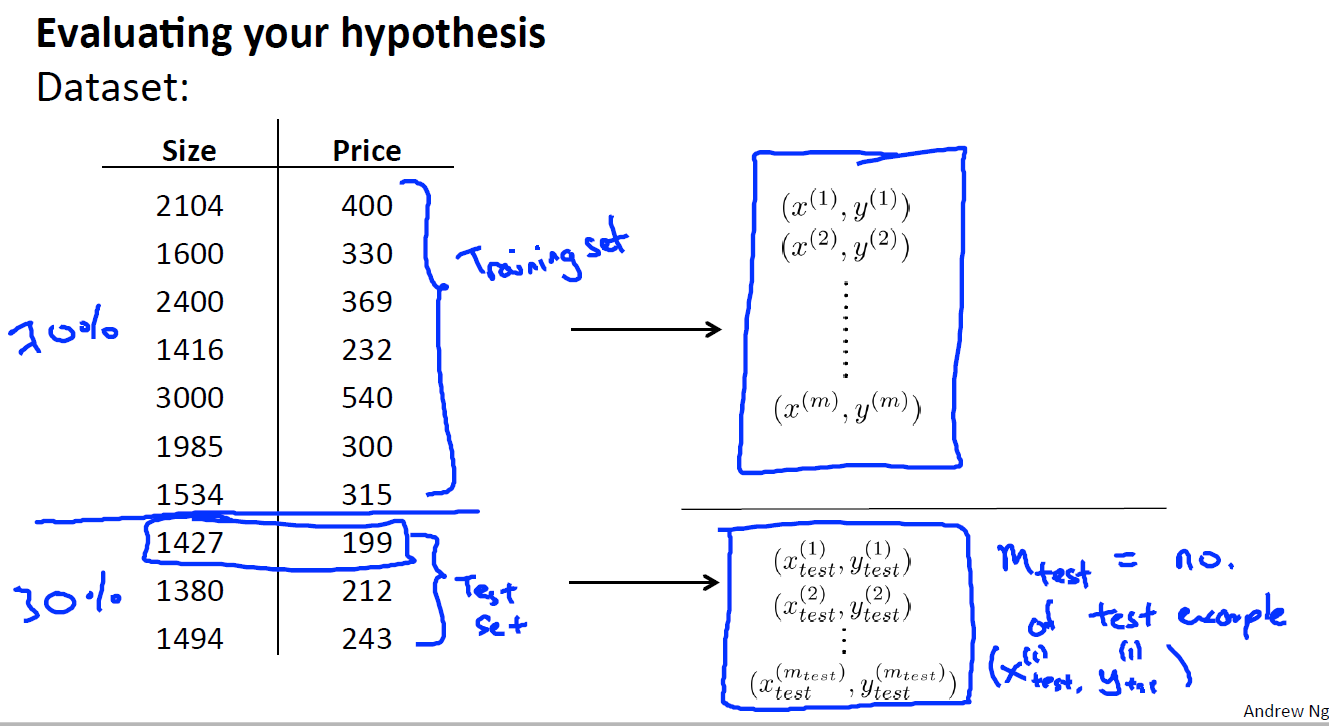
将这些数据集分为两个部分:Training set 和 Test set, 即是 训练集和测试集,
其中一种典型的分割方法是, 按照7:3的比例 ,将70%的数据作为训练集, 30%的数据作为测试集 。
PS:如果数据集是有顺序的话,那么最好还是随机取样。比如说上图的例子中,如果price或者size是按递增或者递减排列的话,那么就应该随机取样本,而不是将前70%作为训练集,后30%作为测试集了。
接下来 这里展示了一种典型的方法,你可以按照这些步骤训练和测试你的学习算法 比如线性回归算法 。首先 ,你需要对训练集进行学习得到参数 θ , 具体来讲就是最小化训练误差 J(θ) ,这里的 J(θ) 是使用那70%数据 来定义得到的,也就是仅仅是训练数据 。接下来,你要计算出测试误差,用 Jtest(θ) 来表示测试误差, 那么你要做的就是 取出你之前从训练集(Training set)中学习得到的参数 θ 放在这里, 来计算你的测试误差 Jtest(θ)

Jtest(θ) 分为Linear Regreesion与Logistic Regression:
Linear Regreesion error:
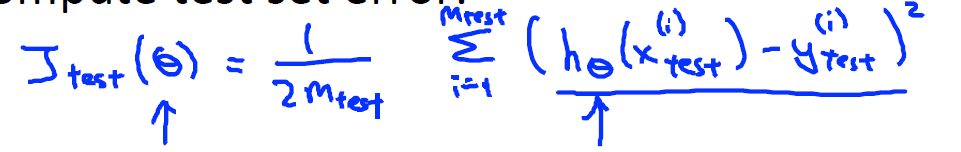
Logistic Regression error:
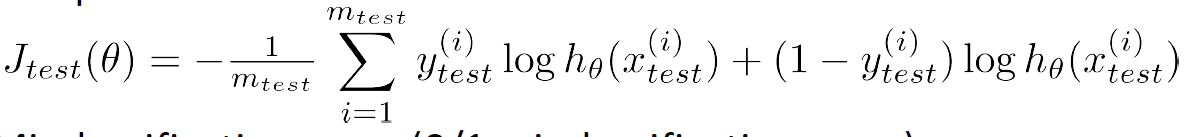
假如你想要确定对于某组数据, 最合适的多项式次数是几次 ?怎样选用正确的特征来构造学习算法 或者假如你需要正确选择 学习算法中的正则化参数λ ,你应该怎样做呢?
Model Selection:
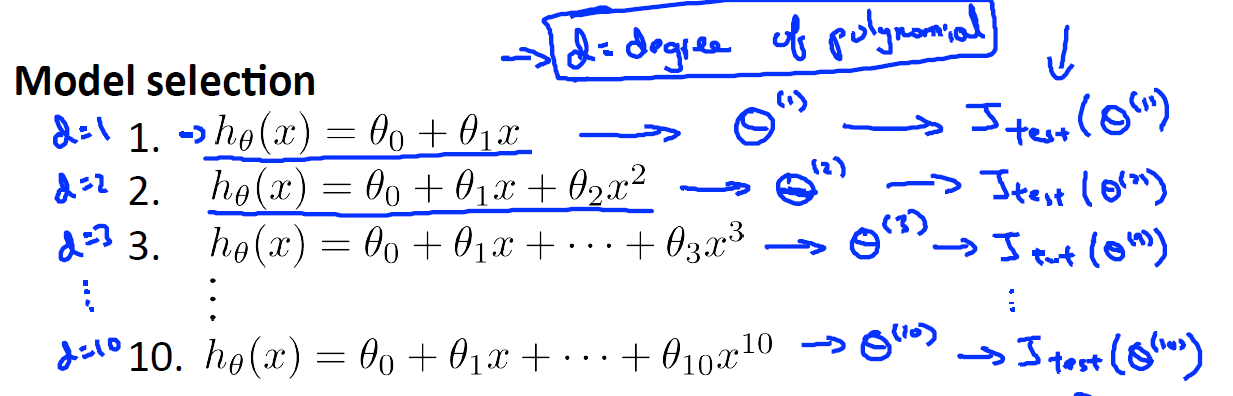
1.首先,建立d个model 假设(图中有10个,d表示其id),分别在training set 上求使其training error最小的θ向量,那么得到d个 θ
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 4628
4628











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









