







此系列为 Coursera 网站Andrew Ng机器学习课程个人学习笔记(仅供参考)
课程网址:https://www.coursera.org/learn/machine-learning
Week 6 —— 应用机器学习的建议和机器学习系统设计
目录
一 算法改进
1-1 评价算法
1-1-1 模型诊断
对于正则化线性回归,其代价函数为:
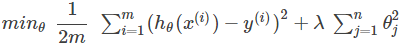
当面对测试集,你的算法效果不佳时,你一般会怎么做?
- 获得更多的训练样本?
- 尝试更少的特征?
- 尝试获取附加的特征?
- 尝试增加多项式的特征?
- 尝试增加λ?
- 尝试减小λ?
具体的情况要具体分析,方法不能乱用 ,机器学习(算法)诊断(Diagnostic)是一种测试方法,使你能对一种学习算法进行深入的认识,知道什么能运行,什么不能运行,并且能指导你如何最大限度的提高学习算法的性能。
诊断测试虽然需要一些时间来实现,但是这样做可以更有效的利用你的时间。
通常的解决办法是:
将数据集分成训练集和测试集, 将训练集训练出的参数用测试集数据测试性能。
通常情况下,训练集包含70%的数据,测试集是剩下的30%。
1-1-2模型选择,validation
只是因为学习算法很好地适合训练集,这并不意味着这是一个很好的假设。它可能会过于合适,因此您对测试集的预测会很差。假设您在训练参数的数据集上测量的假设的误差将低于任何其他数据集上的误差。
给定许多具有不同多项式度的模型,我们可以用系统的方法来确定“最佳”函数。为了选择你的假设的模型,你可以测试每个多项式的程度,看看错误的结果。比如在多项式回归时,我们该怎么选择次数作为我们的假设模型呢?
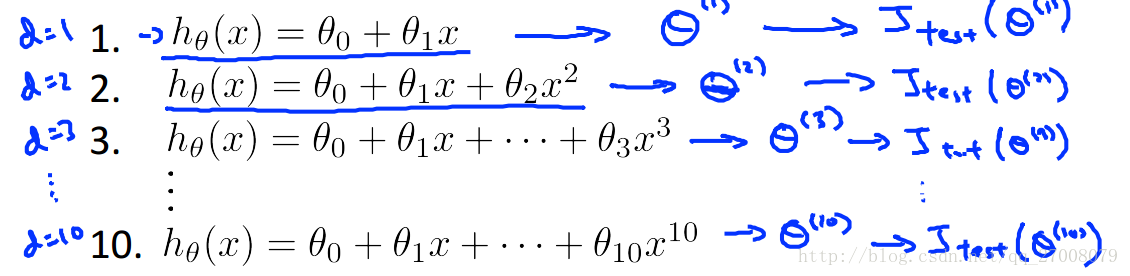
我们可以把数据集分为三类,训练集,交叉验证集和测试集,
- 训练集:60%
- 交叉验证集:20%
- 测试集:20%
用交叉验证集来作为评判选择的标准,选择合适的模型,而测试集则是作为算法性能的评判。
现在我们可以使用以下方法为三个不同的集合计算三个单独的错误值:
- 使用每个多项式的训练集来优化Θ中的参数。
- 使用交叉验证集找出具有最小误差的多项式度d(确定合适的模型)。
- 使用带有Jtest的测试集(Θ(d))估计泛化误差,(d =具有较低误差的多项式的theta);(评价模型)
为啥要设置 “交叉验证集”呢?
一般的数据集都是分为trainning set, cross validation set, test set.
当然, 也有只分为training set和test set的分法
(1)对第二种分法来说,取得min(Err(test_set))的model作为最佳model,但是我们并不能评价选出来的这个model的性能,如果就将Err(test_set)的值当作这个model的评价的话,这是不公正的,因为这个model本来就是最满足test_set的model
(2)相反,第一种方法取得min(Err(cv_set))的model作为最佳model,对其进行评价的时候,使用剩下的test_set对其进行评价 而不是使用Err(cv_set))的值
1-2 偏差和方差
1-2-1 诊断偏差和方差
在本节中,我们考察多项式d的程度与假设的不合适或过拟合之间的关系。
我们需要区分是否偏差bias 或方差variance 是造成不良预测的问题。
高偏差是不足的,高方差是过度拟合。理想的情况下,我们需要找到这两者之间的中庸之道。
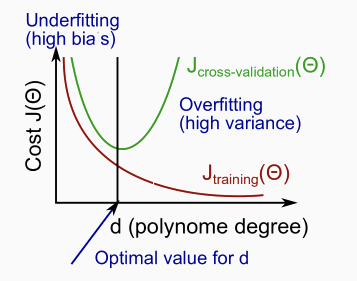
随着我们增加多项式的阶数d,训练误差将趋于减小。
与此同时,交叉验证误差会随着我们将d增加到一个点而降低,然后随d的增加而增加,形成一个凸曲线。
- 高偏差(underfitting):Jtrain(Θ)和JCV(Θ)都很高。而且,JCV(Θ)≈Jtrain(Θ)。
- 高方差(overfitting):Jtrain(Θ)将是低的,JCV(Θ)将比Jtrain(Θ)大得多。
1-2-2 正则化方差与偏差
算法正则化可以有效地防止过拟合, 但正则化跟算法的偏差和方差 又有什么关系呢?
根据λ大小画出的拟合曲线如下:
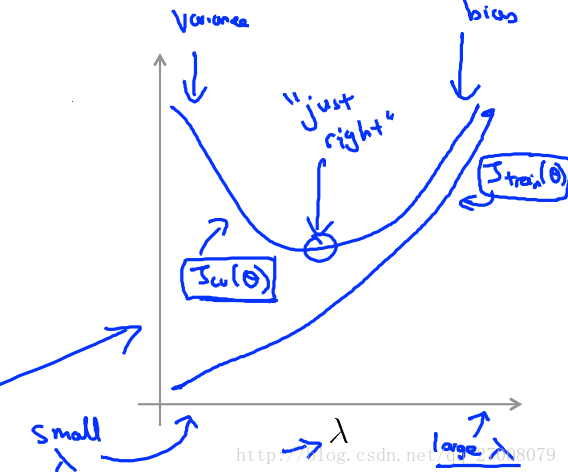
在上图中,我们看到随着λ的增加,我们的拟合变得更加低下。(右边欠拟合)
另一方面,当λ接近0时,我们倾向于过度拟合数据。(左边过拟合)
那么我们如何选择我们的参数λ来使其“恰到好处”呢?
不断调整超参数
λ
1-2-3 学习曲线 Learning curves
使用学习曲线 来判断某一个学习算法 是否处于偏差 方差问题 或是二者皆有
在少数几个数据点(如1,2或3)上训练一个算法将很容易产生0个错误,因为我们总是可以找到一个接近这些点数的二次曲线。因此:
- 随着训练集变大,二次函数的误差增加。
- 经过一定的m或训练集大小后,误差值将平稳。
根据样本的大小与误差的关系我们可以画出一般的学习曲线模样

增大样本的方法对高偏差的模型并不能起到一定作用
而模型处于高方差的情况下,增大样本可能会起到效果。
1-2-4 决定保留谁
对开头提出的各种措施,我们看看他们适合于什么样的模型
- 获取更多培训示例:高度差异
- 尝试更小的功能集:高差异
- 增加特征:高偏见
- 添加多项式特征:高偏差
- 降低λ:高偏差
- 增加λ:高方差
诊断神经网络:
- 一个参数较少的神经网络容易出现underfitting。这也是计算待价更低。
- 具有更多参数的大型神经网络容易过度拟合overfitting。这在计算上也是昂贵的。在这种情况下,您可以使用正则化(增加λ)来解决过度拟合问题。
使用单个隐藏层是一个很好的默认开始。您可以使用交叉验证集在许多隐藏层上训练您的神经网络。然后您可以选择性能最好的一个。
二 机器学习系统设计
给定一个电子邮件数据集,我们可以为每个电子邮件构建一个向量。这个向量中的每个条目代表一个单词(词袋模型)。该矢量通常包含10,000到50,000个条目,通过查找我们数据集中最常用的单词来收集。如果在电子邮件中找到一个单词,我们将分配它的相应条目1,否则如果没有找到,条目将是0.一旦我们已经准备好了所有的x向量,我们将训练我们的算法,最后,我们可以用它来分类电子邮件是否是垃圾邮件。
那么你怎么能花时间来提高这个分类器的准确度呢?
- Step1.使用快速但不完美的算法实现;
- Step2.画出学习曲线,分析偏差、方差,判断是否需要更多的数据、增加特征量….;
- Step3.误差分析:人工检测错误、发现系统短处,来增加特征量以改进系统。
那么你怎么能花时间来提高这个分类器的准确度呢?
- 收集大量的数据(例如“蜜罐”项目,但并不总是有效)
- 开发复杂的功能(例如:在垃圾电子邮件中使用电子邮件标题数据)
- 开发算法以不同的方式处理您的输入(识别垃圾邮件中的拼写错误)。
2-1 误差分析
一般我们提升模型的步骤为:
- Step1.使用快速但不完美的算法实现;
- Step2.画出学习曲线,分析偏差、方差,判断是否需要更多的数据、增加特征量….;
- Step3.误差分析:人工检测错误、发现系统短处,来增加特征量以改进系统。
因此,我们应该尝试新的东西,为我们的错误率得到一个数值,并根据我们的结果决定是否要保留新的特征。(使用误差度量值 来判断是否添加新的特征)
2-2 处理 “倾斜” 数据
有些时候,一些数据很不平衡,比如正向的占99%、负向的占1%(倾斜数据shewed data)。这样只用准确度这个指标就不能很好的衡量算法的好坏,所以我们引入了信度precision和召回率recall。举个例子:
判断癌症的分类器,建立逻辑回归模型hθ(x),y=1表示有癌症,y=0则没有。假设你的算法在测试集上只有1%的错误,可实际上,测试集中只有0.5%的病人患有癌症,因此我们可以通过下面的方法来提高正确率。

这个“算法”很搞笑:不管是谁来看病,统统判断为没有癌症。这样准确度就提高了,但是病人一时开心,以后会耽误治疗。
从上面的例子我们可以知道正确率不足以表现一个算法的优劣(在某些正例或反例及其少的数据集中),因此我们引入了Precision/Recall。 构造方法:
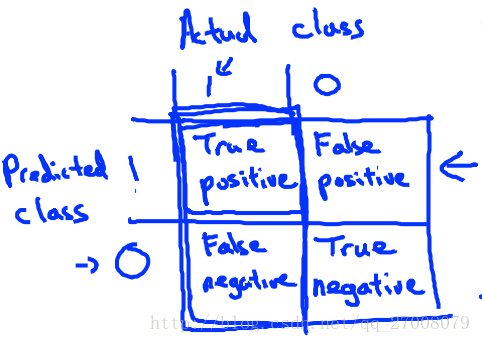

在大多数的时候我们想找到两个评价指标的平衡。比如:
假设考虑到一个正常人如果误判为癌症,将会承受不必要的心理和生理压力,所以我们要有很大把握才预测一个病人患癌症(y=1)。那么一种方式就是提高阙值(threshold),不妨设我们将阙值提高到0.7,即:
Predict 1 if: hθ(x)≥0.7
Predict 0 if: hθ(x)<0.7在这种情况下,我们将会有较高的precision,但是recall将会变低。
假设考虑到一个已经患癌症的病人如果误判为没有患癌症,那么病人可能将因不能及时治疗而失去宝贵生命,所以我们想要避免错过癌症患者的一种方式就是降低阙值,假设降低到0.3, 即
Predict 1 if: hθ(x)≥0.3
Predict 0 if: hθ(x)<0.3在这种情况下,将得到较高的recall,但是precision将会下降。
为了将precision和Recal转变为一个单一数值,我们引入了F1值: F=2PRP+R
总结:
衡量一个算法应该用一下值综合考虑:
- Accuracy = (true positives + true negatives) / (total examples)
- Precision = (true positives) / (true positives + false positives)
- Recall = (true positives) / (true positives + false negatives)
- F 1 score = (2 * precision * recall) / (precision + recall)
2-3使用大的数据集
事实证明 在一定条件下 , 得到大量的数据并在 某种类型的学习算法中进行训练。 可以是一种 获得 一个具有良好性能的学习算法 有效的方法。
像这样的结果 引起了一种 在机器学习中 的普遍共识: “取得成功的人不是拥有最好算法的人 而是拥有最多数据的人”
那么这种说法 在什么时候是真 什么时候是假呢?
- 特征x包含足够的信息来准确地预测y。 (例如,验证这种情况的一种方式是,如果只有在给定x的情况下,领域上的专家才能自信地预测y)。
- 我们训练一个具有大量参数(能够学习/表示相当复杂的函数)的学习算法。















 4370
4370

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









