







po主最近在学习数据挖掘方面相关算法,今天就在这里总结一下数据挖掘领域的经典算法,同时提供每个算法的详解链接,就当做在这里温习吧。对于熟悉的算法我会有较多的描述,不熟悉的算法可能描述较少,以免误导,但是会贴出学习的链接。由于本人也是资历尚浅,必然有错误的地方,也希望大家能够指出来,我也会改正的,谢谢大家。
数据挖掘方面的算法,主要可以用作分类,聚类,关联规则,信息检索,决策树,回归分析等。他们的界限并不是特别的明显,常常有交叉,如聚类算法在一定程度上也是一种分类算法。分类算法比较成熟,并且分支也较多。
这里先介绍两个概念:监督学习与非监督学习。通俗一点说,如果我们提前设置一些标签,然后对于每个待分类项根据一定规则分类到某些标签,这就是监督学习。如果我们提前不知道标签,而是通过一定的统计手段将一定量的数据,分成一个个类别,这就是非监督学习,通常用作“聚类”(不绝对)。当然监督学习常用作分类学习,也可用作回归分析等。
1.K-Means算法
K-Means算法是一种常用的非监督学习聚类算法,也常用在图像检索领域,如K-Means+BoF算法。它的作用就是我们可以在不知道有哪些类别的情况下,将数据以K个类心,聚成K个聚类。
通常我们会先确定一个相异度度量方法,常用的相异度有,欧氏距离,曼哈顿距离,马氏距离,余弦距离等。根据两个数据之间的“距离”来确定两个数据之间的相异度。
K-Means算法步骤:
1.所有数据中取K个数据(可随机,也可选定)作为K个聚类的初始类心。
2. 遍历下一个数据,分别计算它到K个类心的“距离”,并将其归类到“距离”最小的那个类心所在聚类中。
3. 重新调整该聚类的类心,一般来说,类心的每维为该聚类中所有数据该维的算术平均。
4. 重复步骤2、3直到所有数据均被聚类
5. 输出结果
K-Means算法中K值的大小甚为关键,当K值较大时,时间消耗会很大,但是聚类结果也较好一点。当K值较小时,聚类结果会比较单调。当然K值大小也依赖于数据量的大小,另外,初始的K个类心的选择对结果也有较大的影响,最好这K个类心之间差异较大。
K-Means学习可以参考下面的链接:
2.Apriori算法
Apriori算法可以说是最为经典的关联规则算法,之后的关联规则算法多数基于该算法。它的作用是依据数据,挖掘各个事务之间的可能关联,我之前感兴趣也实现过一次,所以较为熟悉。
举一个大家较熟悉的栗子:曾经有一个有趣的发现,跟尿布一起购买最多的商品竟是啤酒!经过大量实际调查和分析,揭示了一个隐藏在”尿布与啤酒”背后的美国人的一种行为模式:在美国,一些年轻的父亲下班后经常要到超市去买婴儿尿布,而他们中有30%~40%的人同时也为自己买一些啤酒。产生这一现象的原因是:美国的太太们常叮嘱她们的丈夫下班后为小孩买尿布,而丈夫们在买尿布后又随手带回了他们喜欢的啤酒。这是沃尔玛的真是案例,这一小小发现曾经给沃尔玛带来较为可观的利润,这便利用了关联规则挖掘。这种关联从主观意识上很难想到,但是通过数据就可以。
Apriori算法本身不难,而且很有意思。但是理解这个算法稍微费劲,由于自己以前写过这个算法的详解以及实现代码,所以这里贴上自己以前的链接吧
3.Naive Bayes(朴素贝叶斯)
朴素贝叶斯是很经典的统计分类方法,属于监督学习,它的理论依据是贝叶斯原理。
即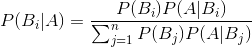
朴素贝叶斯的作用也比较容易理解,举个例子,你在大街上看见一个男生穿着格子衫,那么你觉得他很有可能是理工男(无意黑),这是因为穿格子衫的大部分都是理工男,而这一点,是建立在我们的已知的经验得出的。即,在已知他是穿的格子衫的情况下,他是理工男的可能性最大,这就是条件概率用来分类的应用。
Naive Bayes算法的定义如下
- 假设有一个可由n个独立属性表示的待分类项
其中
为n个独立属性.
- 已知有m个类别
- 求条件概率
- 取上面条件概率的最大值,其对应的类别即为待分类项所在的类别
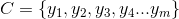
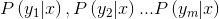
可见,条件概率的计算是算法中的关键与难点,这个时候就需要用到贝叶斯公式了。假设我们有一定量的训练样本,其中是已经分类过的待分类项。下面是条件概率的计算步骤
- 统计计算每个类别的频率,即
- 统计计算每个特征属性在每个类别中的条件概率,即
- 以及贝叶斯公式可得
又因为属性相互独立,可得
另外根据全概率公式可知
根据以上公式,即可求得待分类项对于每个类别的条件概率。
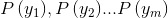
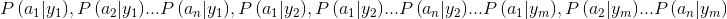
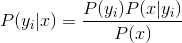
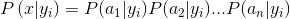
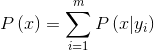
实验上,我们通常用一部分数据作为训练样本,用一部分数据作为测试样本,以避免过度拟合。理论上说,朴素贝叶斯的分类效果应该优于决策树分类的,但是实际生活中朴素贝叶斯的效果却不太理想,因为很难保证各特征属性相互独立。
下面贴上链接
算法杂货铺——分类算法之朴素贝叶斯分类(Naive Bayesian classification)
4.KNN算法(K近邻算法)
KNN算法与K-Means算法有相似之处,但是KNN算法严格来说是一种归类算法,应属于半监督学习(本人臆测。不严谨)。KNN算法算是最简单的归类算法了。
我们通常说,物以类聚,人以群分,你属于的群体很大程度上描述了你是怎么样的人。KNN算法的核心思想也是如此,我们取K个与待分类项最接近的项,统计这些项分别属于哪些类别,最后哪个类别中所占的项最多,即认为是该待分类项所在的类别。
与K-means算法相同,这里面同样涉及到了相异度度量的问题,我们需要设定一个度量想法来确定两个项之间的相异度,如,欧氏距离,余弦距离,曼哈顿距离等。
wikipedia官方解释上有这样一张图片:
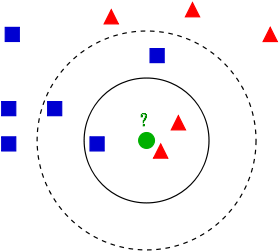
问其中带问号的点属于什么类别,
- 当K==3,那么我们统计得到,离带问号的点最接近的3个点中2个红色三角,1个蓝色正方,那么根据KNN算法,该点与红色三角属于同一类别。
- 当K==5,那么我们统计得到,离带问号的点最接近的3个点中2个红色三角,3个蓝色正方,那么根据KNN算法,该点与蓝色正方属于同一类别。
由此可见,K的取值对于待分类项是一个关键问题
- 如果选择较小的K值,就相当于用较小的领域中的训练实例进行预测,“学习”近似误差会减小,只有与输入实例较近或相似的训练实例才会对预测结果起作用,与此同时带来的问题是“学习”的估计误差会增大,换句话说,K值的减小就意味着整体模型变得复杂,容易发生过拟合;
- 如果选择较大的K值,就相当于用较大领域中的训练实例进行预测,其优点是可以减少学习的估计误差,但缺点是学习的近似误差会增大。这时候,与输入实例较远(不相似的)训练实例也会对预测器作用,使预测发生错误,且K值的增大就意味着整体的模型变得简单。
- K=N,则完全不足取,因为此时无论输入实例是什么,都只是简单的预测它属于在训练实例中最多的累,模型过于简单,忽略了训练实例中大量有用信息。
贴上相关链接
5.SVM算法(支持向量机算法)
支持向量机算法应用领域十分广泛,图像分类,数据分类,统计回归等等,是十分经典的监督式学习算法。
SVM算法的理解就不像之前的算法那么通俗易懂,详细讲解也需要较大篇幅的图解和公式,这里就简单介绍一下。涉及到的图片部分来自后面给的链接,不知道这种行为是否侵权,如有侵权,我会撤回。
最简单的SVM分类就是线性分类,如下图
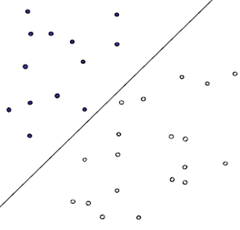
这个图大家应该都不陌生,就是用一个线性方程将所有数据分为两类,当然这也是最简单的情况了,况且就算这样简单的情况下,线性方程也仍然不唯一,如下图

哪种分法最好呢??一般来说,能够与两个类别的界限越明晰,分类越好,怎么理解,如下图
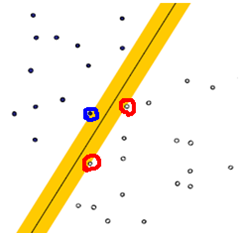
蓝点和红点分别是两个类别中距离分类线最近的点,它们与分类线的距离越大,那么分类效果就越好,这几个点就是支持向量。这个原则也也成为Maximum Marginal(最大间距),是SVM的一个理论基础之一。
当然你一定也想到了,当所有的点并不能用一条线分类的时候怎么办,就如下面的图
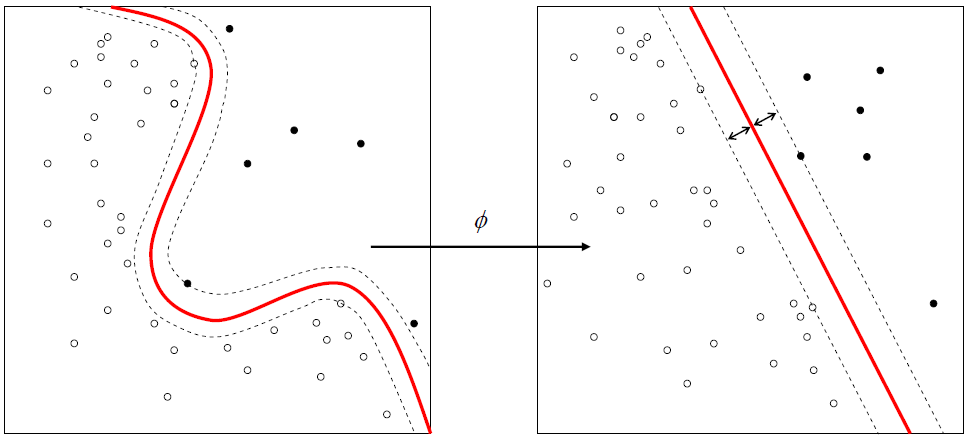
左边的图明显不能用一条直线划分,这个时候,我们有两种选择
- 将数据从原来的线性空间投射到高维的空间里,并在高维的空间里进行超平面划分,如果还是不行,就向更高维空间投射(记得看过一本书说总能在某一个高维空间进行划分,不知道是否严谨),关于投射变换,就跟核函数有关系,核函数有很多种,这个详看链接
- 依旧使用线性划分,但是允许误差,这里面又会引入惩罚函数的概念,详看链接
关于SVM更多的理论基础和数学模型,还是需要大家更多的时间学习,下面贴上参考链接
机器学习中的算法(2)-支持向量机(SVM)基础
支持向量机SVM(一)
6.Decision Tree(决策树算法)
决策树在决策分析与风险评估等领域有十分广泛的应用,属于监督学习,它在一定程度上可以作为趋势探测。而且不同于贝叶斯分类中各特性必须独立的理论要求的严格,决策树更加贴近实际生活,所以也有较多的实际应用。
如下图是预测一个人是否拥有电脑的简单决策树模型:
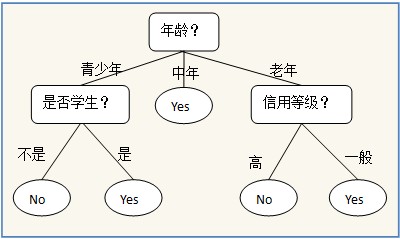
这种图相信大家都一眼能够看懂,在建立这个树的时候,我们假设每个数据项都有属性“年龄”,“是否学生”,“信用等级”等特征属性,那么我们在建立树的时候,就需要考虑每到一个结点应该使用什么属性合适。这里就要引入三个概念,一个是“熵”,一个是“期望熵”,另一个是“信息增益”:
- 熵:熵是接收的每条消息中包含的信息的平均量,信息论中,熵的计算方法是:
,其中
是指第i个类别在整个训练样本中的比例,具体的例子后面附上的链接会有
- 期望熵:我们以属性A对训练样本进行划分,那么期望熵即为
,按照属性A,训练样本可以划分为v个类别。
- 信息增益:两个概率分布相异度的一种度量,非对称的(来之维基百科),其定义
,对于分类来讲,信息增益越大分类效果越好,决策树也就越简洁。就比如两个分类,我们以天气来决策是否出去:1.不下雨就出去,下雨就不出去。2.不下雨可能出去可能不出去,不下雨就不出去。那么分类1就会比分类2的效果好一点,对于天气这个属性来说,分类1的信息增益也会比分类2的信息增益大。
由上面我们可以知道,在每次选择属性作为决策结点时,我们通常选择当前信息增益最大的属性。这也是数据挖掘领域经典的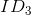
ID3算法的一个缺陷就是偏向于选择取值多的属性。为了解决这个问题,又引入了C4.5算法,其基于ID3算法做了部分改进,其中最主要的一条就是将信息增益换做了增益率来选择属性作为决策结点,这个在后面附上的链接里面也会有所说明。
另外,决策树模型在应用的时候,也常和启发式方法结合,可以达到优化的效果。
算法杂货铺——分类算法之决策树(Decision tree)
7.EM算法(最大期望算法)
这个算法我曾经研究学习过,就详细讲解一下
在统计计算中,最大期望(EM)算法是在概率模型中寻找参数最大似然估计或者最大后验估计的算法,其中概率模型依赖于无法观测的潜变量(Latent Variable),在机器学习领域有很广泛的应用。提到最大期望算法,就不得不提一下最大似然估计(Maximum Likelihood Estimate)。
举一个栗子:假设有两个相同的箱子,甲箱中有99个白球1个黑球,乙箱中有99个黑球1个白球,那么我们随机从一个箱子中随机抽一个球,现在已知这个球是白色的,问这个球是从哪个箱子中取出??
对于这样的问题,人们的第一印象就是:“这个球最像是从甲箱取出”,这符合人们的经验事实。这里面的“最像”就是“最大似然”的意思,这种想法也被称为“最大似然原理”。
那么什么是参数最大似然估计呢?官方的定义较为晦涩,我就以自己的理解描述一遍:
- 假设总体的概率函数为
,其中
一个未知参数或者几个未知参数组成的参数向量,
为参数空间,
为该总体的测试得到的样本。
- 最大似然函数:
,这也是样本的
的联合概率函数(注意:里面的
不是变量,这是已知的样本,这里面写上只是因为它们与函数相关。函数中的变量应当是未知参数
)
- 若存在
满足使得其最大似然函数
值最大,那么
通俗一点说就是,最大似然估计解决的就是这样一个问题:一个随机变量的的概率函数中存在未知参数,但是我们通过实验能够获得该随机变量的实验样本,现在就是根据实验样本估计这些未知参数的值。
我们也知道,根据实验样本我们并不能肯定未知参数的值,但是我们可以估计,估计的标准就是:估计得到的未知参数值可以使得实验样本发生的概率最大。所以原问题就转换成求最大似然函数值最大时的未知参数的值,也就是使得试验样本发生的概率最大。
关于已知函数求参数极值问题,这就是一般数学领域的问题了,常用的方法就是求导数,取极值。最大似然估计可能不存在,也可能不唯一。另外在求函数极值是参数值过程中也有很多技巧,因为我们并不需要求出最大值具体是多少,只需要保证值最大即可,所以对函数取对数等方法在求最大似然估计中特别常用。
MLE是参数估计非常有效的参数估计算法,但是当有多余参数或者数据缺失时,就比如可观察的参数不足,MLE的求取会变得十分繁杂困难,这时就引入了EM算法(最大期望算法)。EM算法就更为晦涩了,我在这里尽量讲清楚。
- 假设我们通过试验样本观测到的相关参数是y,y可能是一个参数或者是参数向量,未知参数仍是 θ ,它是一个未知参数或者一个未知参数向量,我们一样可以求得最大似然函数
,这个时候我们可能会发现
- 这时候我们尝试引入变量z,z可能是一个参数也可能是一个参数向量,它协助参数y使得最大似然函数得以约化。
有的同学可能会问,既然没有观察参数z,那我们设计实验观测参数z不就行了么??这是因为z是不可观测的,是我们人为引入假设的,我们也把它叫做潜变量(latent variable),这也是潜变量有意思的地方。另外,我们也需要推导出潜变量的概率函数(可以含有未知参数),后面能用到。
这时候我们观察到的数据y被称为不完全数据,因为它不能单独产生意义。数据 (y,z
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 1889
1889

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









