







本课程笔记是基于今年斯坦福大学Feifei Li, Andrej Karpathy & Justin Johnson联合开设的Convolutional Neural Networks for Visual Recognition课程的学习笔记。目前课程还在更新中,此学习笔记也会尽量根据课程的进度来更新。
今天的话题是:图像分类和最近邻分类器。
1. Image Classification
1.1 问题概述
图像分类是指输入一张图片,让计算机从给定的众多类别中搜索出它的真实类别。例如,输入下图,输出它属于{猫,狗,帽子,杯子}四个类别中的哪个。
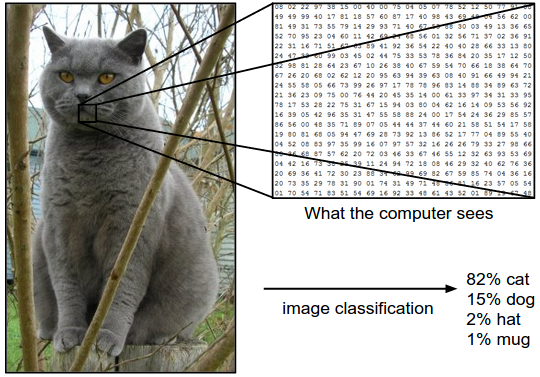
对于计算机而言,它看到的并不是图片,而是(寂寞…)一个三维矩阵。这个例子里,猫这张图片是248 pixel*400 pixel,并包含RGB三个颜色通道,也就是说这张图片的矩阵是248*400*3维的,总共2976000个值,每个值是0(黑)~255(白)之间的整数。我们的任务就是将这300万输入的值转变成一个简单的标签输出,比如我们想要的标签是“猫”。
1.2 面临的问题
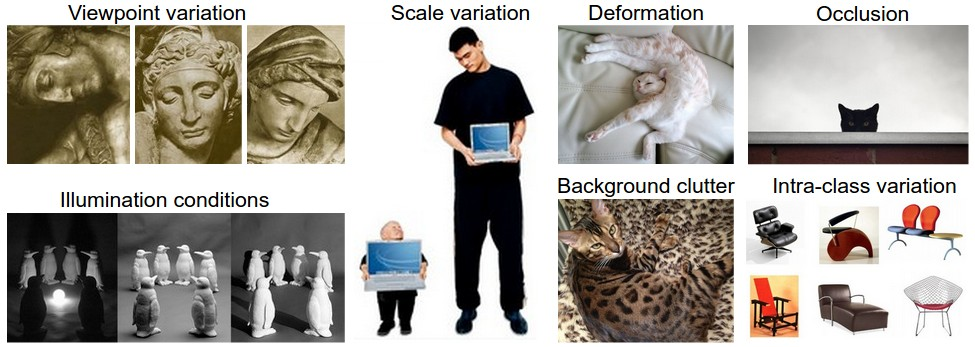
对于人类来说识别物体是一件很容易的事情,然而从计算机的角度来看就不那么简单了,刚刚我们说到计算机看到的并不是一张图片,而是一大堆像素点构成的三维矩阵。另外其他面临的问题还有:
- 视角的差异:摄像机与物体的相对位置不同,拍摄出的图片会发生很大的变化,如下图。
- 尺度差异:同一类别的物体在图像上的表现大小不一。
- 形变:许多我们感兴趣的物体并不是刚体,比如下图那只猫,其柔软程度真是够了。
- 遮挡:物体可能受到其他物体的遮挡导致只有部分可见。
- 光照条件:光照的影响在pixel level的变化是非常显著的。
- 背景杂乱(background clutter):物体和背景过于接近使得它很难被识别出来。
- 同类物体的差异:“类”的概念可以很宽泛,比如椅子这个类,我们就可以给出长相很不同的椅子,这也给分类增加了难度。
1.3 数据驱动方法
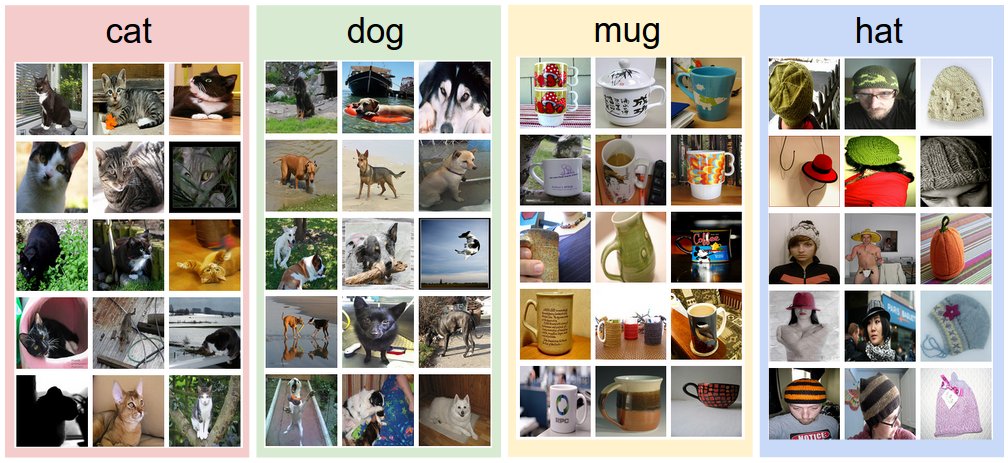
所以我们究竟要怎么做才能对图片进行分类呢?就像一个小孩学习对世界的认知一样,我们首先给计算机提供每个类的很多样例,让它去学习每个类该长什么样子。这种方法称为数据驱动的方法。顾名思义,它需要收集大量的数据用于训练,我们称为训练集(training set)。下图是一个训练集的例子,假设我们有4个类别(现实中类别数目远比4大),我们为每个类别收集一些图片,在训练时我们就告诉计算机这张照片是猫,那张照片是狗,让他去学习不同类别的特点。
1.4 图像分类流程
我们已经知道图像分类是输入一张图片(其实是一个像素构成的矩阵),输出它对应的一个标签。它的整个流程是这样的:
- 训练阶段(learning):我们首先准备包含K个类别共N张图片的一个训练集。在训练阶段,我们利用这个训练集来学习每个类别所具有的特征,这一步我们称为训练分类器或学习模型。
- 评估阶段(evaluation):为了评价所训练的分类器的好坏,我们给它一些从未见过的图片(称为测试集)让它去预测类别。就像小孩子今天学了新的知识,我们要测试一下学习效果。最后我们再拿这些图片真实的标签(称为ground truth)和预测的标签进行对比,我们所希望的是预测的标签基本和ground truth一样,这样就说明我们的分类器效果是好的。
2. Nearest Neighbor Classifier
我们先来学习最简单的最近邻分类器。这种分类器和卷积神经网络没有半毛钱关系,在现实生活中也不常用,但是它会帮助我们理解整个图像分类问题。
2.1 CIFAR-10 dataset
作为例子,我们会使用到的一个图像分类数据集是CIFAR-10 dataset. 这个数据集共包含60000张32*32pixel的小图片,每个图片的标签是以下10类中的1类:{飞机,汽车,鸟,猫,鹿,狗,青蛙,马,船,卡车}。这60000张图片被分成两部分,训练集包含50000张图片,测试集包含10000张图片。下图(左)是这10个类别随机的100张图片。

我们的任务是对测试集中的10000张图片进行分类。最近邻分类器的做法是:让每张测试图片和训练集中的所有图片做对比,然后以最相似的那张训练集图片的标签作为测试图片的标签。上图(右)可以看到为10张测试图片进行最近邻查找的结果,10个例子中只有3个分类正确,其他的都错了,比如第8行一个马头的最近邻是一辆车,这种误分类的原因可能是他们都有相似的黑色背景。
2.2 相似性度量
到现在为止,我们还没有具体说明如何比较两张图片之间的相似度。我们知道,一张图片是32*32*3的矩阵,那么比较两个矩阵,一种最简单的方法是比较每个像素点之间的差异再加起来:两张图片分别表示成两个矩阵 I1,I2 ,其相似度度量可以通过L1距离: d1
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 1919
1919

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









