







本课程笔记是基于今年斯坦福大学Feifei Li, Andrej Karpathy & Justin Johnson联合开设的Convolutional Neural Networks for Visual Recognition课程的学习笔记。目前课程还在更新中,此学习笔记也会尽量根据课程的进度来更新。
1. 引子
在这一章中,我们将介绍backpropagation,也就是反向传播算法,理解这一过程对于学习神经网络很重要。
之前的章节中我们定义了一个loss function,它是输入数据x和网络参数W的函数,我们希望通过调节W使得网络的loss最小——这在Optimazation那一节中讲过,通过梯度下降法来更新W。但是神经网络是一个多层的结构,直接用输出对输入求导计算非常复杂,因此我们会用到反向传播算法来进行逐层的梯度传播与更新。
我们先来简单地回顾一下偏导数的计算和链式法则。比如函数f(x,y,z)=(x+y)*z, 为了求得f对三个输入x,y,z的偏导(即梯度),我们可以首先把它看成一个两层的组合函数,分解成q=x+y,f=q*z。这样逐层地计算偏导数就简单了: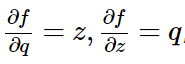
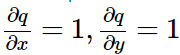
那么根据链式法则,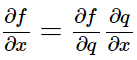
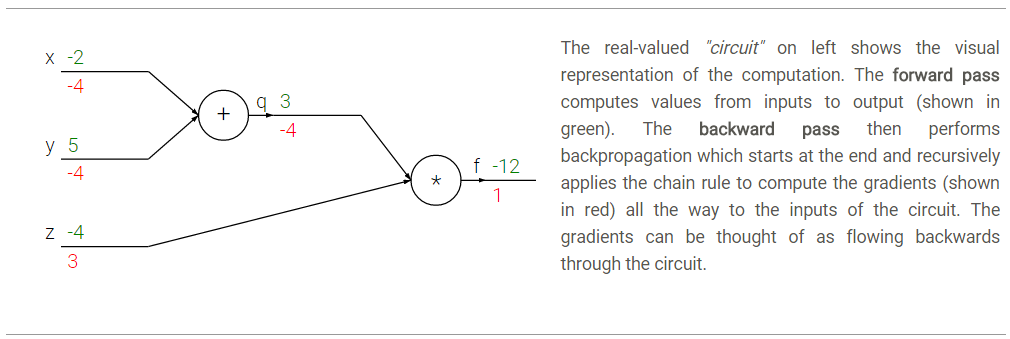
注意每一层的门电路都能够独立地根据局部的输入计算当前门电路的输出以及局部的梯度,而不需要去考虑其他层的操作。
- 比如以“+”门为例,输入为x=-2,y=5,计算得输出为3(前向传播),又由于进行的是加法运算,因此
- 接着进行“
∗
”门的运算,此时输入为上一层的输出q=3,及z=-4,相乘得到最终输出为-12,又由于进行的是乘法运算,
- 那么在反向传播过程中,局部梯度会通过链式法得到最终梯度,即
说了这么多,主要想表达的意思就是 通过链式法则进行逐层的梯度反向传播,你get到了吗?
2. Sigmoid function
任何可微函数都可以看成门运算,并且我们还可以把多个门组合成一个,让我们来看一个常用的函数,叫做sigmoid激活函数:
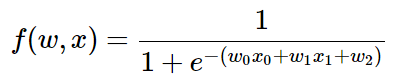
这个表达式包含w和x 2个输入,我们可以把这个复杂的表达式拆分成多层的门电路的组合:
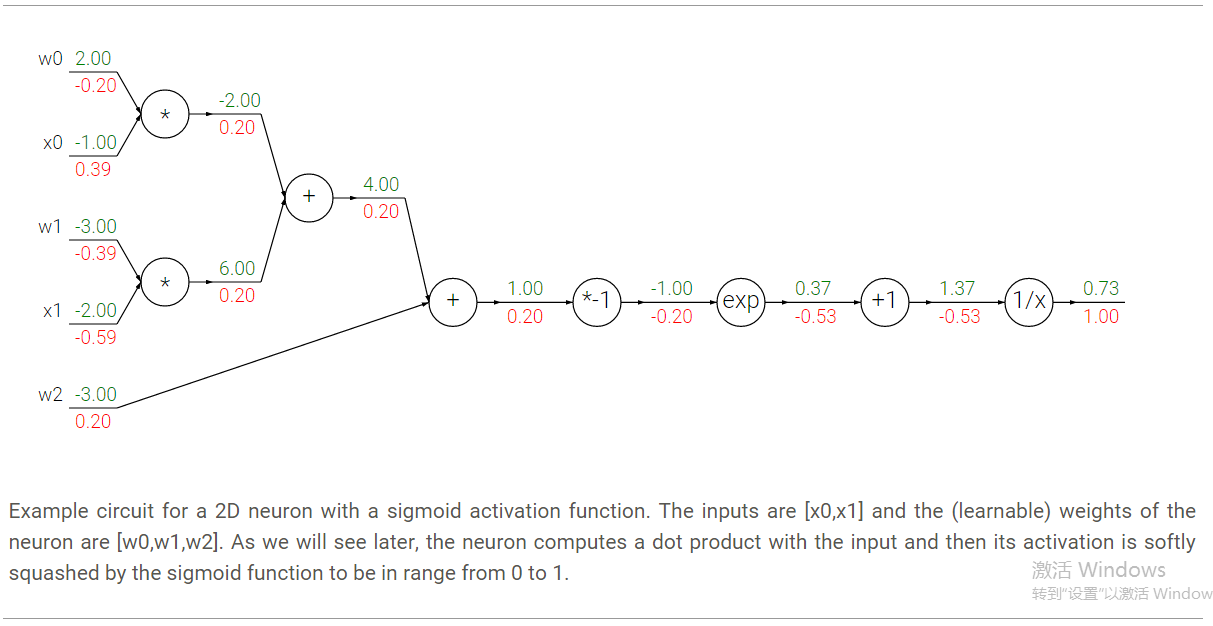
其中不同门的偏导数如下,
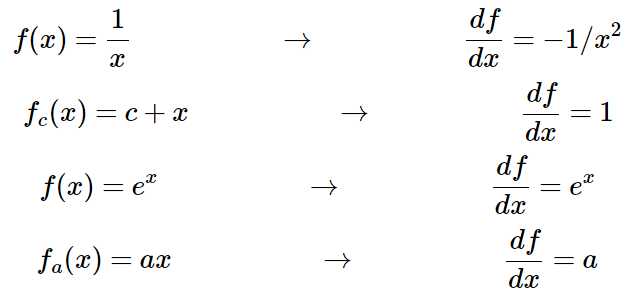
在这个例子中我们看到7层的一个网络,但其实我们可以把其中的部分看成一个整体:
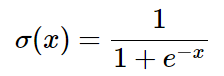
这整个表达式叫做sigmoid function,对它求偏导很简单:

因此我们会把一连串的运算组合成一个sigmoid门,那么反向传播算法是这样的:
w = [2,-3,-3] # assume some random weights and data
x = [-1, -2]
# forward pass
dot = w[0]*x[0] + w[1]*x[1] + w[2]
f = 1.0 / (1 + math.exp(-dot)) # sigmoid function
# backward pass through the neuron (backpropagation)
ddot = (1 - f) * f # gradient on dot variable, using the sigmoid gradient derivation
dx = [w[0] * ddot, w[1] * ddot] # backprop into x
dw = [x[0] * ddot, x[1] * ddot, 1.0 * ddot] # backprop into w
# we're done! we have the gradients on the inputs to the circuit3. 反向传播代码实现
现在我们来举一个例子具体得说明如何进行反向传播的运算。f(x,y)如下式,注意我们并不需要显式地去计算
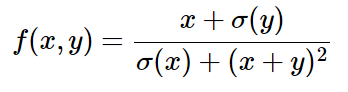
在前向传播中,我们将整个等式进行如下拆分:
x = 3 # example values
y = -4
# forward pass
sigy = 1.0 / (1 + math.exp(-y)) # sigmoid in numerator #(1)
num = x + sigy # numerator #(2)
sigx = 1.0 / (1 + math.exp(-x)) # sigmoid in denominator #(3)
xpy = x + y #(4)
xpysqr = xpy**2 #(5)
den = sigx + xpysqr # denominator #(6)
invden = 1.0 / den #(7)
f = num * invden # done! #(8)那么通过上述代码,我们其实是把整个函数拆分成了多个简单的表达式,每个表达式相当于之前所说的一个门,这些简单的表达式使得我们可以很方便地计算局部梯度。这样在进行反向传播时只需将局部梯度相乘,在下面的代码中每个局部梯度用d…表示:
# backprop f = num * invden
dnum = invden # gradient on numerator #(8)
dinvden = num #(8)
# backprop invden = 1.0 / den
dden = (-1.0 / (den**2)) * dinvden #(7)
# backprop den = sigx + xpysqr
dsigx = (1) * dden #(6)
dxpysqr = (1) * dden #(6)
# backprop xpysqr = xpy**2
dxpy = (2 * xpy) * dxpysqr #(5)
# backprop xpy = x + y
dx = (1) * dxpy #(4)
dy = (1) * dxpy #(4)
# backprop sigx = 1.0 / (1 + math.exp(-x))
dx += ((1 - sigx) * sigx) * dsigx # Notice += !! See notes below #(3)
# backprop num = x + sigy
dx += (1) * dnum #(2)
dsigy = (1) * dnum #(2)
# backprop sigy = 1.0 / (1 + math.exp(-y))
dy += ((1 - sigy) * sigy) * dsigy #(1)
# done! phew这样在最后我们就实现了梯度的反向传播。这里需要注意两点:
1.在进行前向传播的过程中保存好拆分变量是有必要的,这能够帮助我们快速地在反向传播过程中计算梯度。
2.前向传播的过程中涉及多次x,y的使用,因此我们在反向传播计算梯度时特别注意f对x,y的梯度是一个累加的过程(也就是说我们用的是+=,而不是=),这遵循了微分学中多变量的链式法则。
4. 反向传播常用门的直观理解
在反向传播中几个常用的门电路,如+,*,max(),其实包含了一些实际的意义。比如以下图的电路为例:
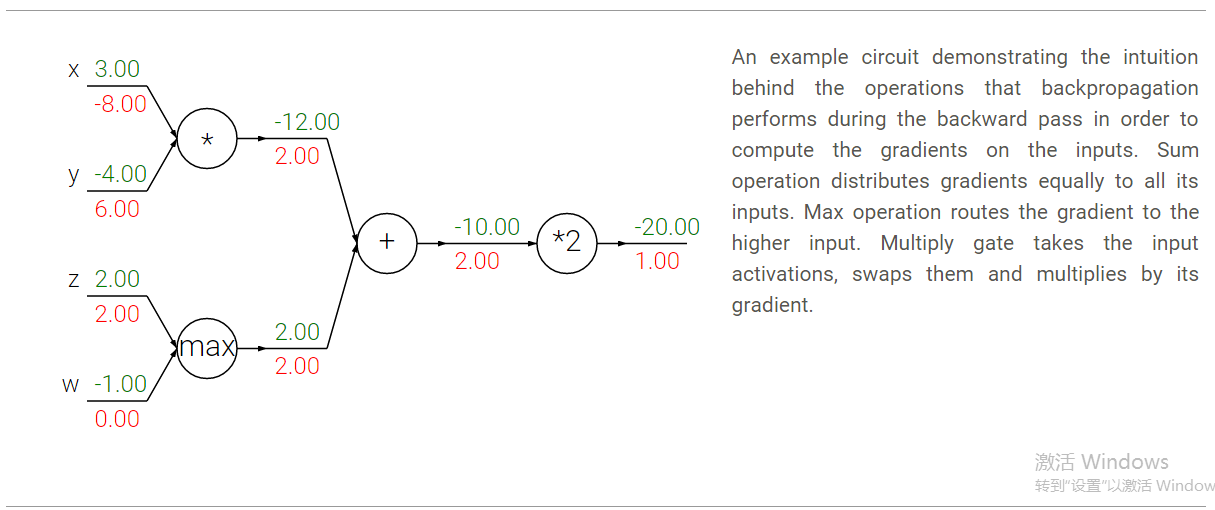
- +门的作用是将其输出处接收到的梯度按原样传递给其所有的输入。这是因为加法的局部梯度是1,所以输入处的梯度=输出的梯度*1,保持不变。在本例中,+门将2这个梯度反向传播给了他的两个输入,使得这两个输入的梯度也同样为2.
- max门的含义是梯度的选择性。和+门的“平等对待”不同,max门选择前向传播过程中值最大的那个输入来传递梯度,其他输入梯度为0。在本例中,max门将2的梯度传递给了z和w中值更大的z,也就是z处的梯度为2,而w处的梯度为0.
-
∗
门则是将输出的梯度乘以输入的值得到输入的梯度(不过乘的是除自己以外其他输入的值)。比如上图中x处的梯度-8,是由输出梯度2,乘以另一个输入值y(-4)得到的。另外对于
∗ 门还需要注意的一点是,如果这个门的一个输入非常小,另一个输入非常大,那么 ∗ 门就会给小的输入一个较大的梯度,而给大的输入一个很小的梯度。在线性分类器中常用的乘门是用于计算点乘wTxi 的,上述情况说明输入x的数值范围其实对于w的梯度的量级是有影响的。比如在预处理过程中给所有的训练数据 xi 都乘以1000,那么w的梯度就会变成现有的1000倍,你就必须减小学习率来抵消这个因素。这就是为什么预处理过程如归一化等非常重要的原因,他会在很细微的地方影响我们的结果。
总结
我们对梯度的反向传播进行了直观的理解,它们是如何经过分层的计算最终得到输出对输入的梯度。这里的重点就是在正向传播的过程中对整个函数进行分层次的拆分,然后在反向传播过程中计算每个门电路的局部梯度。在下一章中,我们将开始介绍神经网络。















 3万+
3万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









