







 本文介绍了Spark SQL中DataFrame的加载和保存数据流程,重点讨论了DataFrameReader的load方法和DataFrameWriter的save方法,以及Parquet文件格式在Spark SQL中的应用和最佳实践。通过源码分析,揭示了Spark SQL默认使用Parquet的原因,并探讨了大数据分析技术栈的发展趋势。
本文介绍了Spark SQL中DataFrame的加载和保存数据流程,重点讨论了DataFrameReader的load方法和DataFrameWriter的save方法,以及Parquet文件格式在Spark SQL中的应用和最佳实践。通过源码分析,揭示了Spark SQL默认使用Parquet的原因,并探讨了大数据分析技术栈的发展趋势。
概要:Spark SQL对数据的操作涉及到对数据的输入、输出,其实主要就是操作DataFrame。通过DataFrameReader的load方法可以创建DataFrame,通过DataFrameWriter的save方法可以把DataFrame中的数据保存到具体文件。我们可以通过设置具体的格式参数来指出读取的文件是什么类型,以及通过设置具体的格式参数来指出输出的文件是什么类型。
1, Spark SQL 加载数据流程
SQLContext中有load方法,实际上也就是使用了DataFrameReader的load方法。目前的Spark 1.6.0中,虽然SQLContext还有load方法,但已被设置为@deprecated。也就是说在Spark 2.0中SQLContext可能不再使用load方法。
DataFrameReader用来从外部存储系统(比如:文件系统,键值存储库,等等)读取数据,并返回DataFrame对象。
DataFrameReader有format方法,用来设置输入数据源的格式。
DataFrameReader用load方法,把外部数据加载进来,变成一个DataFrame。各种load方法,最终实际是使用以下load方法:
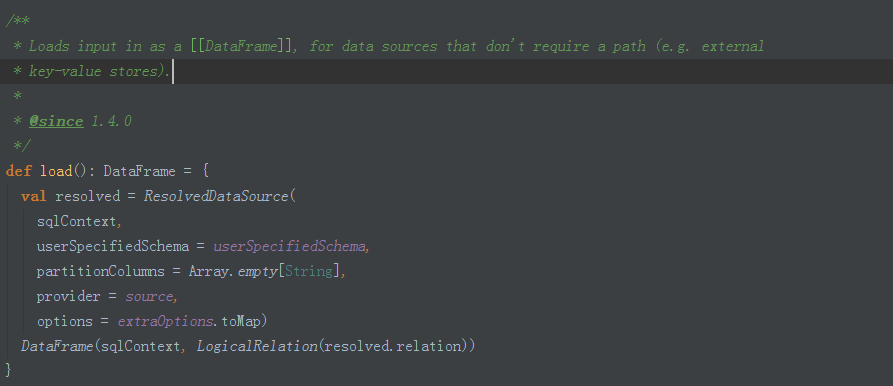
DataFrameReader的load方法是生成ResolvedDataSource对象,再使用该对象生成并返回一个DataFrame对象。
查看ResolvedDataSource的apply方法,可以发现其中是通过模式匹配来对各种类型的数据源分别进行处理,生成ResolvedDataSource对象。
查看ResolvedDataSource的backwardCompatibilityMap,可以知道,Spark SQL可以用来处理jdbc访问的数据库、json文件、parquet等多种来源的数据。
查看ResolvedDataSource的lookupDataSource方法,可以知道,Spark SQL可以处理Avro、Hive的ORC、访问Hadoop的文件系统等各种文件。
理论上讲,Spark SQL可以支持所有格式数据源。
DataFrame类中有this、toDF、printSchema、explain、show等常用方法。
2, Spark SQL保存数据
DataFrame中有各种save方法,实际上也就是使用了DataFrameWriter的save方法。
目前的Spark 1.6.0中虽然DataFrame还有save方法,但已被设置为@deprecated。也就是说在Spark 2.0中DataFrame可能不再使用save方法。
用以下程序S
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 810
810

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









