







Hadoop版本:2.6.0
Eclipse版本:luna
一、 Hadoop做的一个计算单词的实例
1、引入jar
<dependencies>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-common</artifactId>
<version>2.2.0</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-hdfs</artifactId>
<version>2.2.0</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-client</artifactId>
<version>2.2.0</version>
</dependency>
<dependency>
<groupId>jdk.tools</groupId>
<artifactId>jdk.tools</artifactId>
<version>1.6</version>
<scope>system</scope>
<systemPath>${JAVA_HOME}/lib/tools.jar</systemPath>
</dependency>
</dependencies>package com.lin.wordcount;
import java.io.IOException;
import java.util.Iterator;
import java.util.StringTokenizer;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapred.FileInputFormat;
import org.apache.hadoop.mapred.FileOutputFormat;
import org.apache.hadoop.mapred.JobClient;
import org.apache.hadoop.mapred.JobConf;
import org.apache.hadoop.mapred.MapReduceBase;
import org.apache.hadoop.mapred.Mapper;
import org.apache.hadoop.mapred.OutputCollector;
import org.apache.hadoop.mapred.Reducer;
import org.apache.hadoop.mapred.Reporter;
import org.apache.hadoop.mapred.TextInputFormat;
import org.apache.hadoop.mapred.TextOutputFormat;
public class WordCount {
public static class WordCountMapper extends MapReduceBase implements Mapper<Object, Text, Text, IntWritable> {
private final static IntWritable one =new IntWritable(1);
private Text word =new Text();
public void map(Object key,Text value,OutputCollector<Text, IntWritable> output, Reporter reporter) throws IOException {
StringTokenizer itr = new StringTokenizer(value.toString());
while(itr.hasMoreTokens()) {
word.set(itr.nextToken());
output.collect(word,one);//字符解析成key-value,然后再发给reducer
}
}
}
public static class WordCountReducer extends MapReduceBase implements Reducer<Text, IntWritable, Text, IntWritable> {
private IntWritable result =new IntWritable();
public void reduce(Text key, Iterator<IntWritable>values, OutputCollector<Text, IntWritable> output, Reporter reporter)throws IOException {
int sum = 0;
while (values.hasNext()){//key相同的map会被发送到同一个reducer,所以通过循环来累加
sum +=values.next().get();
}
result.set(sum);
output.collect(key, result);//结果写到hdfs
}
}
public static void main(String[] args)throws Exception {
//System.setProperty("hadoop.home.dir", "D:\\project\\hadoop-2.7.2"); 如果本地环境变量没有设置hadoop路径可以这么做
String input = "hdfs://hmaster:9000/input/LICENSE.txt";
String output = "hdfs://hmaster:9000/output/";
JobConf conf = new JobConf(WordCount.class);
conf.setJobName("WordCount");
//方法一设置连接参数
conf.addResource("classpath:/hadoop2/core-site.xml");
conf.addResource("classpath:/hadoop2/hdfs-site.xml");
conf.addResource("classpath:/hadoop2/mapred-site.xml");
conf.addResource("classpath:/hadoop2/yarn-site.xml");
//方法二设置连接参数
//conf.set("mapred.job.tracker", "10.75.201.125:9000");
conf.setOutputKeyClass(Text.class);//设置输出key格式
conf.setOutputValueClass(IntWritable.class);//设置输出value格式
conf.setMapperClass(WordCountMapper.class);//设置Map算子
conf.setCombinerClass(WordCountReducer.class);//设置Combine算子
conf.setReducerClass(WordCountReducer.class);//设置reduce算子
conf.setInputFormat(TextInputFormat.class);//设置输入格式
conf.setOutputFormat(TextOutputFormat.class);//设置输出格式
FileInputFormat.setInputPaths(conf,new Path(input));//设置输入路径
FileOutputFormat.setOutputPath(conf,new Path(output));//设置输出路径
JobClient.runJob(conf);
System.exit(0);
}
}3、输出结果:
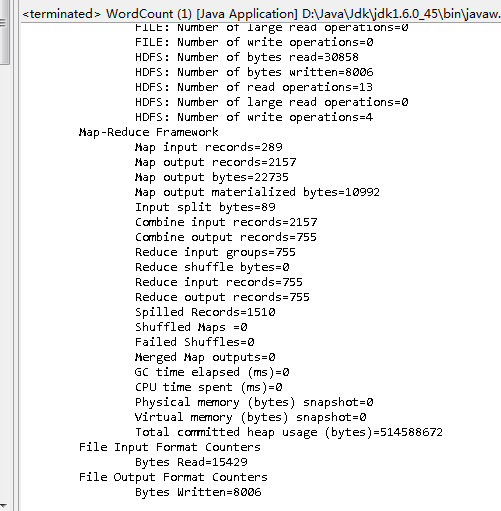
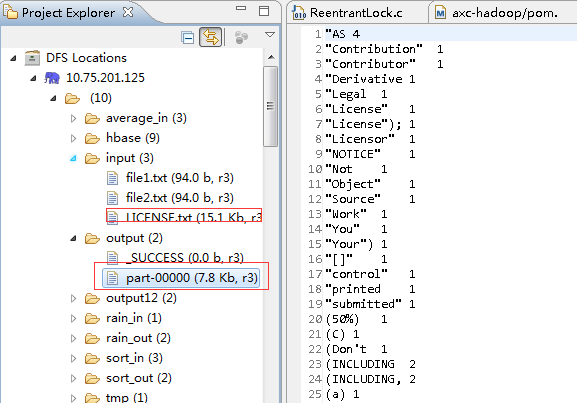
二、Sort排序实例
源码:
package com.lin.sort;
/**
* 功能概要:数据排序
*
* @author linbingwen
* @since 2016年6月30日
*/
import java.io.IOException;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.util.GenericOptionsParser;
public class Sort {
//map将输入中的value化成IntWritable类型,作为输出的key
public static class Map extends Mapper<Object,Text,IntWritable,IntWritable> {
private static IntWritable data=new IntWritable();
//实现map函数
public void map(Object key,Text value,Context context) throws IOException,InterruptedException{
String line=value.toString();
data.set(Integer.parseInt(line));
context.write(data, new IntWritable(1));
}
}
//reduce将输入中的key复制到输出数据的key上,
//然后根据输入的value-list中元素的个数决定key的输出次数
//用全局linenum来代表key的位次
public static class Reduce extends Reducer<IntWritable,IntWritable,IntWritable,IntWritable> {
private static IntWritable linenum = new IntWritable(1);
//实现reduce函数
public void reduce(IntWritable key,Iterable<IntWritable> values,Context context) throws IOException,InterruptedException {
for(IntWritable val:values){
context.write(linenum, key);
linenum = new IntWritable(linenum.get()+1);
}
}
}
public static void main(String[] args) throws Exception{
Configuration conf = new Configuration();
//这句话很关键
// conf.set("mapred.job.tracker", "192.168.1.2:9001");
conf.addResource("classpath:/hadoop2/core-site.xml");
conf.addResource("classpath:/hadoop2/hdfs-site.xml");
conf.addResource("classpath:/hadoop2/mapred-site.xml");
conf.addResource("classpath:/hadoop2/yarn-site.xml");
String[] ioArgs=new String[]{"hdfs://hmaster:9000/sort_in","hdfs://hmaster:9000/sort_out"};
String[] otherArgs = new GenericOptionsParser(conf, ioArgs).getRemainingArgs();
if (otherArgs.length != 2) {
System.err.println("Usage: Data Sort <in> <out>");
System.exit(2);
}
Job job = Job.getInstance(conf, "Data Sort");
job.setJarByClass(Sort.class);
//设置Map和Reduce处理类
job.setMapperClass(Map.class);
job.setReducerClass(Reduce.class);
//设置输出类型
job.setOutputKeyClass(IntWritable.class);
job.setOutputValueClass(IntWritable.class);
//设置输入和输出目录
FileInputFormat.addInputPath(job, new Path(otherArgs[0]));
FileOutputFormat.setOutputPath(job, new Path(otherArgs[1]));
System.exit(job.waitForCompletion(true) ? 0 : 1);
}
}
file1.txt
2
32
654
32
15
756
652235956
22
650
92file3.txt
26
54
6
运行结果:
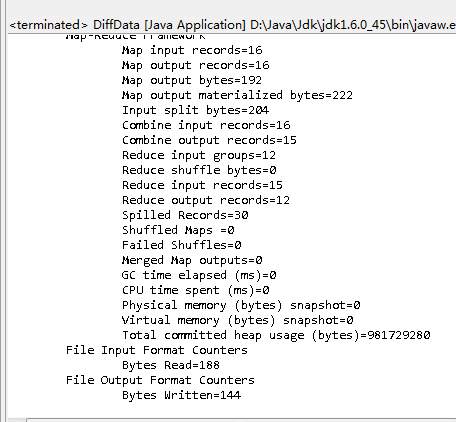
输入输出:
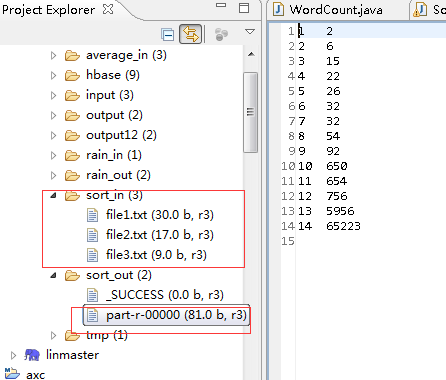
下面是在hadoop的安装机器上看的结果
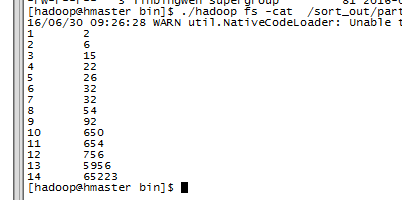
三、去重实例
package com.lin.diffdata;
import java.io.IOException;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapred.JobConf;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.util.GenericOptionsParser;
import com.lin.wordcount.WordCount;
/**
* 功能概要:数据去重复
*
* @author linbingwen
* @since 2016年6月28日
*/
public class DiffData {
// map将输入中的value复制到输出数据的key上,并直接输出
public static class Map extends Mapper<Object, Text, Text, Text> {
private static Text line = new Text();// 每行数据
// 实现map函数
public void map(Object key, Text value, Context context)
throws IOException, InterruptedException {
line = value;
context.write(line, new Text(""));
}
}
// reduce将输入中的key复制到输出数据的key上,并直接输出
public static class Reduce extends Reducer<Text, Text, Text, Text> {
// 实现reduce函数
public void reduce(Text key, Iterable<Text> values, Context context)
throws IOException, InterruptedException {
context.write(key, new Text(""));
}
}
public static void main(String[] args) throws Exception {
JobConf conf = new JobConf(DiffData.class);
conf.setJobName("WordCount");
conf.addResource("classpath:/hadoop2/core-site.xml");
conf.addResource("classpath:/hadoop2/hdfs-site.xml");
conf.addResource("classpath:/hadoop2/mapred-site.xml");
conf.addResource("classpath:/hadoop2/yarn-site.xml");
String[] ioArgs = new String[] { "hdfs://hmaster:9000/input", "hdfs://hmaster:9000/output" };
String[] otherArgs = new GenericOptionsParser(conf, ioArgs).getRemainingArgs();
if (otherArgs.length != 2) {
System.err.println("Usage: Data Deduplication <in> <out>");
System.exit(2);
}
Job job = Job.getInstance(conf, "Data Deduplication");
job.setJarByClass(DiffData.class);
// 设置Map、Combine和Reduce处理类
job.setMapperClass(Map.class);
job.setCombinerClass(Reduce.class);
job.setReducerClass(Reduce.class);
// 设置输出类型
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(Text.class);
// 设置输入和输出目录
FileInputFormat.addInputPath(job, new Path(otherArgs[0]));
FileOutputFormat.setOutputPath(job, new Path(otherArgs[1]));
System.exit(job.waitForCompletion(true) ? 0 : 1);
}
}
运行输出结果:
最终结果:
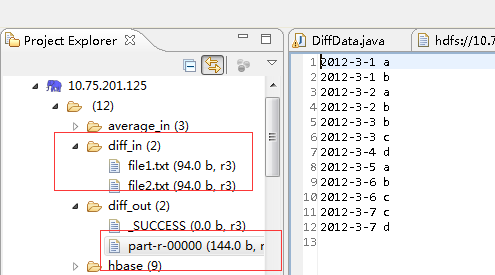
其中输入
file1.txt
2012-3-1 a
2012-3-2 b
2012-3-3 c
2012-3-4 d
2012-3-5 a
2012-3-6 b
2012-3-7 c
2012-3-3 cfile2.txt
2012-3-1 b
2012-3-2 a
2012-3-3 b
2012-3-4 d
2012-3-5 a
2012-3-6 c
2012-3-7 d
2012-3-3 chadoop安装机器上查看结果


四、求平均数
package com.lin.average;
import java.io.IOException;
import java.util.Iterator;
import java.util.StringTokenizer;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.input.TextInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.mapreduce.lib.output.TextOutputFormat;
import org.apache.hadoop.util.GenericOptionsParser;
public class Average {
public static class Map extends Mapper<LongWritable, Text, Text, IntWritable> {
// 实现map函数
public void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
// 将输入的纯文本文件的数据转化成String
String line = value.toString();
// 将输入的数据首先按行进行分割
StringTokenizer tokenizerArticle = new StringTokenizer(line, "\n");
// 分别对每一行进行处理
while (tokenizerArticle.hasMoreElements()) {
// 每行按空格划分
StringTokenizer tokenizerLine = new StringTokenizer(tokenizerArticle.nextToken());
String strName = tokenizerLine.nextToken();// 学生姓名部分
String strScore = tokenizerLine.nextToken();// 成绩部分
Text name = new Text(strName);
int scoreInt = Integer.parseInt(strScore);
// 输出姓名和成绩
context.write(name, new IntWritable(scoreInt));
}
}
}
public static class Reduce extends Reducer<Text, IntWritable, Text, IntWritable> {
// 实现reduce函数
public void reduce(Text key, Iterable<IntWritable> values,Context context) throws IOException, InterruptedException {
int sum = 0;
int count = 0;
Iterator<IntWritable> iterator = values.iterator();
while (iterator.hasNext()) {
sum += iterator.next().get();// 计算总分
count++;// 统计总的科目数
}
int average = (int) sum / count;// 计算平均成绩
context.write(key, new IntWritable(average));
}
}
public static void main(String[] args) throws Exception {
Configuration conf = new Configuration();
//设置hadoop的机器、端口
conf.set("mapred.job.tracker", "10.75.201.125:9000");
//设置输入输出文件目录
String[] ioArgs = new String[] { "hdfs://hmaster:9000/average_in", "hdfs://hmaster:9000/average_out" };
String[] otherArgs = new GenericOptionsParser(conf, ioArgs).getRemainingArgs();
if (otherArgs.length != 2) {
System.err.println("Usage: Score Average <in> <out>");
System.exit(2);
}
//设置一个job
Job job = Job.getInstance(conf, "Score Average");
//去除重复的输出文件夹
// FileSystem fs = FileSystem.get(conf);
// Path out = new Path(otherArgs[1]);
// if (fs.exists(out)){
// fs.delete(out, true);
// }
job.setJarByClass(Average.class);
// 设置Map、Combine和Reduce处理类
job.setMapperClass(Map.class);
job.setCombinerClass(Reduce.class);
job.setReducerClass(Reduce.class);
// 设置输出类型
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
// 将输入的数据集分割成小数据块splites,提供一个RecordReder的实现
job.setInputFormatClass(TextInputFormat.class);
// 提供一个RecordWriter的实现,负责数据输出
job.setOutputFormatClass(TextOutputFormat.class);
// 设置输入和输出目录
FileInputFormat.addInputPath(job, new Path(otherArgs[0]));
FileOutputFormat.setOutputPath(job, new Path(otherArgs[1]));
System.exit(job.waitForCompletion(true) ? 0 : 1);
}
}
运行结果:
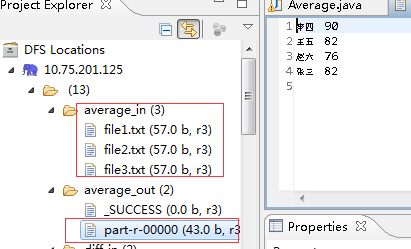
下面输入file1.txt
张三 88
李四 99
王五 66
赵六 77file2.txt
张三 78
李四 89
王五 96
赵六 67file3.txt
张三 80
李四 82
王五 84
赵六 86













 843
843











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









