







 本文详细介绍了在Windows上安装和运行Kafka的步骤,包括JDK的安装、Zookeeper的配置,以及Kafka的下载、配置和启动。通过一系列的命令行操作,创建主题、生产者和消费者,实现Kafka的基本功能。
本文详细介绍了在Windows上安装和运行Kafka的步骤,包括JDK的安装、Zookeeper的配置,以及Kafka的下载、配置和启动。通过一系列的命令行操作,创建主题、生产者和消费者,实现Kafka的基本功能。
摘要:本文主要说明了如何在Windows安装运行Kafka
一、安装JDK
过程比较简单,这里不做说明。
最后打开cmd输入如下内容,表示安装成功
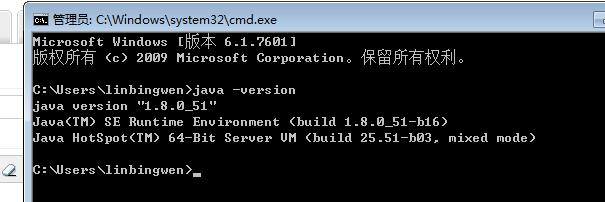
二、安装zooeleeper
下载安装包:http://zookeeper.apache.org/releases.html#download
下载后解压到一个目录:
1.进入Zookeeper设置目录,笔者D:\Java\Tool\zookeeper-3.4.6\conf
2. 将“zoo_sample.cfg”重命名为“zoo.cfg”
3. 在任意文本编辑器(如notepad)中打开zoo.cfg
4. 找到并编辑dataDir=D:\\Java\\Tool\\zookeeper-3.4.6\\tmp
5. 与Java中的做法类似,我们在系统环境变量中添加:
a. 在系统变量中添加ZOOKEEPER_HOME = D:\Java\Tool\zookeeper-3.4.6
b. 编辑path系统变量,添加为路径%ZOOKEEPER_HOME%\bin;
6. 在zoo.cfg文件中修改默认的Zookeeper端口(默认端口2181)
这是笔者最终的文件内容:
# The number of milliseconds of each tick
tickTime=2000
# The number of ticks that the initial
# synchronization phase can take
initLimit=10
# The number of ticks that can pass between
# sending a request and getting an acknowledgement
syncLimit=5
# the directory where the snapshot is stored.
# do not use /tmp for storage, /tmp here is just
# example sakes.
dataDir=D:\\Java\\Tool\\zookeeper-3.4.6\\tmp
# the port at which the clients will connect
clientPort=2181
# the maximum number of client connections.
# increase this if you need to handle more clients
#maxClientCnxns=60
#
# Be sure to read the maintenance section of the
# administrator guide before turning on autopurge.
#
# http://zookeeper.apache.org/doc/current/zookeeperAdmin.html#sc_maintenance
#
# The number of snapshots to retain in dataDir
#autopurge.snapRetainCount=3
# Purge task interval in hours
# Set to "0" to disable auto purge feature
#autopurge.purgeInterval=1
7. 打开新的cmd,输入zkServer,运行Zookeeper。
8. 命令行提示如下:说明本地Zookeeper启动成功
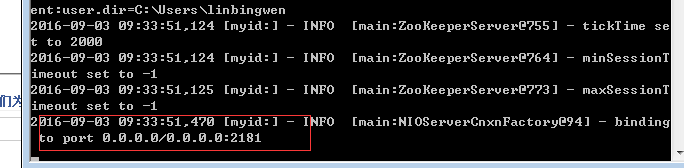
三、安装与运行Kafka
下载
http://kafka.apache.org/downloads.html。注意要下载二进制版本的
下载后解压到任意一个目录,笔者的是D:\Java\Tool\kafka_2.11-0.10.0.1
1. 进入Kafka配置目录,D:\Java\Tool\kafka_2.11-0.10.0.1
2. 编辑文件“server.properties”
3. 找到并编辑log.dirs=D:\Java\Tool\kafka_2.11-0.10.0.1\kafka-log,这里的目录自己修改成自己喜欢的
4. 找到并编辑zookeeper.connect=localhost:2181。表示本地运行
5. Kafka会按照默认,在9092端口上运行,并连接zookeeper的默认端口:2181。
运行:
重要:请确保在启动Kafka服务器前,Zookeeper实例已经准备好并开始运行。
1.进入Kafka安装目录D:\Java\Tool\kafka_2.11-0.10.0.1
2.按下Shift+右键,选择“打开命令窗口”选项,打开命令行。
3.现在输入
.\bin\windows\kafka-server-start.bat .\config\server.properties 并回车。
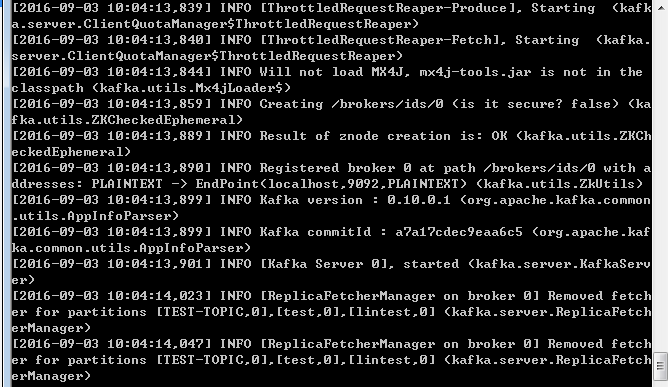
四、测试
上面的Zookeeper和kafka一直打开
(1)、创建主题
1.进入Kafka安装目录D:\Java\Tool\kafka_2.11-0.10.0.1
2.按下Shift+右键,选择“打开命令窗口”选项,打开命令行。
3.现在输入
.\bin\windows\kafka-topics.bat --create --zookeeper localhost:2181 --replication-factor 1 --partitions 1 --topic linlin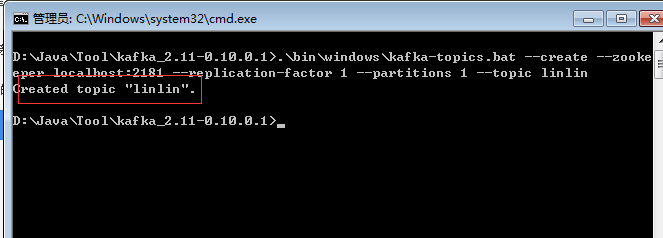
注意不要关了这个窗口!
(2)创建生产者
1.进入Kafka安装目录D:\Java\Tool\kafka_2.11-0.10.0.1
2.按下Shift+右键,选择“打开命令窗口”选项,打开命令行。
3.现在输入
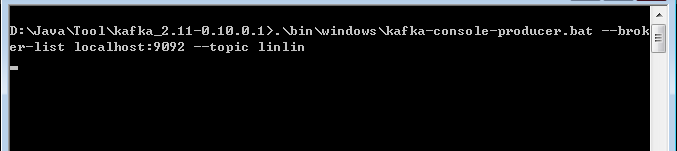
注意不要关了这个窗口!
(3)创建消费者
1.进入Kafka安装目录D:\Java\Tool\kafka_2.11-0.10.0.1
2.按下Shift+右键,选择“打开命令窗口”选项,打开命令行。
3.现在输入

注意不要关了这个窗口!
然后在第2个窗口中输入内容,最后记得回车
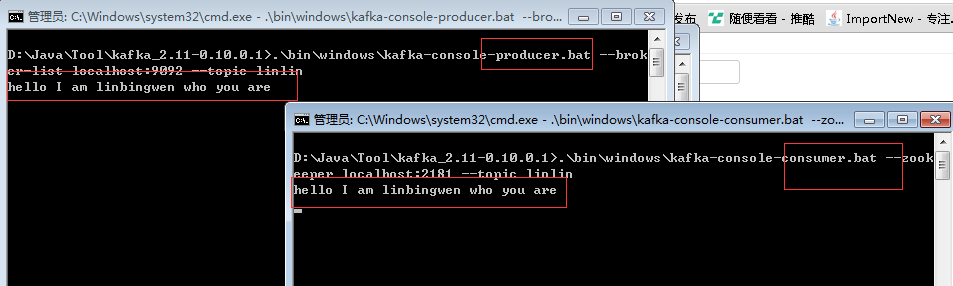
大功告成!
使用Java编写的kafka使用实例如下:

















 290
290

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









