







 本文介绍了如何使用Flume从Kafka消费数据,经过处理后存储到HDFS,再通过Hive外部表进行查询。过程中详细讲解了自定义Source、配置文件设置、启动脚本、打包部署以及Hive外部表创建的步骤。
本文介绍了如何使用Flume从Kafka消费数据,经过处理后存储到HDFS,再通过Hive外部表进行查询。过程中详细讲解了自定义Source、配置文件设置、启动脚本、打包部署以及Hive外部表创建的步骤。
摘要:本文要实现的是一个使用Flume来处理Kafka的数据,并将其存储到HDFS中去,然后通过Hive外部表关联查询出来存储的数据。
所以在建立一个maven工程,整个工程最终的目录如下:
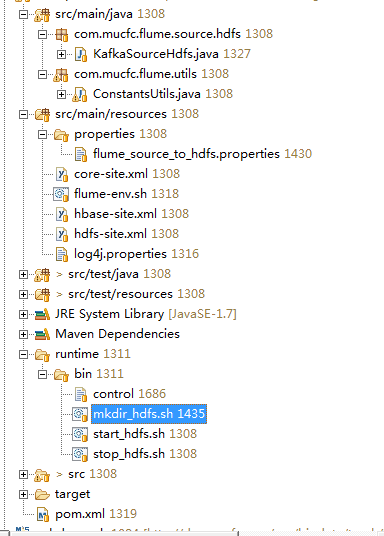
下面开始一步一步讲解
1、定义自己的source
之所以不用源生的,是因为要对得到的消息要一定的处理后再保存到hdfs中去,这里主要就是将每一条消息解析并组装成以“|”做分隔的一条记录

在这个类中定义Start方法来初始化连接kafka:

在这个类中定义处理消费的方法:
其实就是将消息处理成一条以“|”符号隔开的一条数据并放入到channel中:
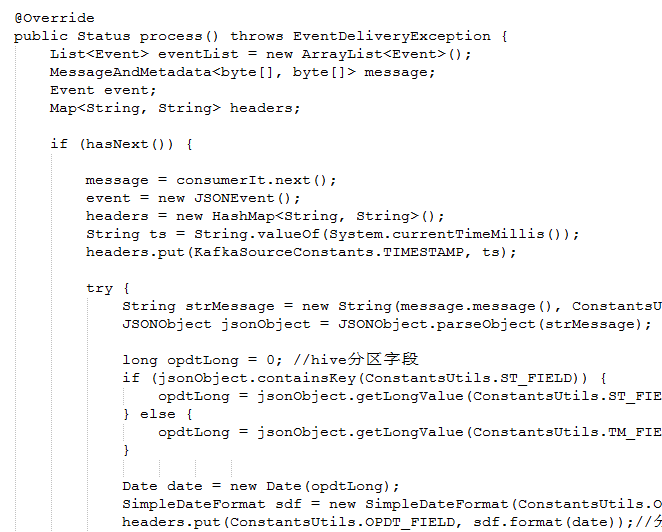
中间还有一部分处理:
笔者都一而过了,这是放到event,下一步就是放在channel中了。

上面的process方法会调用到这:
其实就是将消息解析,并组装成一条以“|”隔开的数据
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 3626
3626

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









