










公司简介
Credit Karma是美国一家提供在线个人信用记录免费查询的创业公司。基于美国个人信用体系,Credit Karma 让美国公民免费在线查询个人信用分数,并向他们提供一些衍生服务。公司成立于2007年,截止到2015年4月,Credit Karma会员人数超过3500万,员工数超过250人。
· 2008年2月,Credit Karma网站上线;
· 2008年9月,推出信用卡推荐服务,向用户推荐符合他们信用分数的信用卡品种;
· 2009年2月,用户数达到 25 万;
· 2010年2月,上线“Way to Save”新产品,根据用户信用分数推荐对他们更划算的金融服务(保险、贷款等);
· 2013年1月,上线新的信用分数平台,为用户提供每日的信用分数变化,并监控自己的财务情况,用户数达到1000万;
· 2014年12月,开放Equifax信用分数和完整信用报告免费查询,至此服务覆盖美国三大信用局中的两家,Equifax和TransUnion。
融资及估值
· 2009年11月,A 轮融资250万美元,由 QED Investors 领投,SV Angel、Felicis Ventures和Founders Fund跟投。
· 2013年4月,B 轮融资3000万美元,由Ribbit Capital和Susquehanna Growth Equity共同投资,A轮投资方Felicis Ventures也在本轮追。
· 2014年3月,C 轮融资8500万美元,其中一半由 Google Capital 所投资,Tiger Global Management(老虎环球基金)、B轮投资方Ribbit Capital和Susquehanna Growth Equity跟投剩余部分。此次融资额主要用途为招聘新员工以及开发新产品。
· 2014年9月,C+轮融资7500万美元,为Google Capital、Tiger Global Management和Susquehanna Growth Equity对C轮的追加投资,此时Credit Karma公司估值超过10亿美元。
· 2015年6月, D轮融资1.75亿美元,Tiger Global再次追加投资,另外还增加了新投资人Valinor Management(瓦里诺管理公司)和Viking Global Investors LP(维京全球投资公司)。此次融资额主要用途为扩大Credit Karma的产品及服务,开发新技术来为用户匹配最合适的房贷及助学贷款。
最新一轮融资使得Credit Karma的股权融资总额达到3.685亿美元,估值达到35亿美元。
发展背景
美国是世界上信用经济最为发达的国家,也是个人信用体系最完善的国家。在美国有三大“信用局”掌管2亿人的信用资料,分别为TransUnion(全联)、Equifax(艾贵发)和Experian(益博睿),这些公司记录每个人的姓名、住址、社会保障号码以及贷款、信用卡、法律纠纷、破产和支付记录等等信息,并且利用这里信息建立了一个评分体系——VantageScore。每一个美国人一生几乎所有的信用记录都会被记录在内,开立新账户、安装电话、签发个人支票、申请信用卡、购买汽车和房子等等都需要这个分数。信用分高的人不仅可以轻松获得贷款,还可享受较低的利率。
VantageScore信用分数评估因素

Credit Karma 的创始人是 Kenneth Lin(肯尼斯林),在创办Credit Karma之前他曾在大学生购物返现网站Upromise和线上贷款机构E-Loan担任金融分析师。2008年3月Credit Karma网站上线,当时正值金融危机爆发,信用分数在申请贷款时至关重要,所以查询信用分数的市场需求非常大,而从信用局查询较麻烦并且收费高,而Kenneth认为让用户获取个人信用报告应该是消费者基本的权利,这直接让Kenneth产生了创建一家免费提供基础服务网站的想法。
在Credit Karma出现之前,人们通常有几种途径获得自己的信用分数,以便判断自己是否有资格申请新的信用卡或贷款。1)免费方式,当个人信用记录被某机构查询时,信用局会在30天内为个人寄送一份简易版本,另外,每个人每年可以免费从三大信用局获得一份信用报告,但并不提供分数。2)付费方式,个人可以支付约20美元从三大信用局购买信用报告,随时掌握自己的信用情况。显而易见,这产生了一个巨大的市场。2011年时,三大信用局每年出售的个人信用报告达到6亿份,年收入超过100亿美金。正是这样的背景,催生出了各种信用分数查询和金融服务的创业公司。
商业模式
1、业务介绍
Credit Karma为用户免费提供实时的信用分数查询,并且不需要像信用局那样等待几天后才能拿到报告,用户注册后可以立刻查询报告,以更加便利和灵活的方式查询个人信用分数,确定个人的贷款利率和借贷限额等。Credit Karma与信用局合作,以批发价购买信用报告,这个价格远低于个人消费者直接查询的购买价格。公司建立之初使用TransUnion的信用分数,从2014年12月开始又获得了Equifax的信用分数,三大信用局中已经有两家的信用记录可以通过Credit Karma查询。目前Credit Karma为用户免费提供以下产品:
· 由TransUnion和Equifax提供的VantageScore 3.0的信用分数,每周更新
· TransUnion和Equifax的完整个人信用报告
· 信用监测,跟踪TransUnion的信用报告,追踪每日变化并提供通知
· 账户监测,绑定银行和信用账户后提供完整分析报告,一眼了解个人财务状况
然而仅仅这些不足以让Credit Karma拥有超过35亿美元的估值。其给用户带来的价值已经远超过几十美金的信用报告,而是基于个人信用和财务状况,通过数据挖掘和算法分析,逐渐成为了全面的财务管理工具,为用户提供高附加值的金融服务:
· 介绍信用评分体系,教用户如何改善信用分数
· 根据信用记录推荐合适的信用卡
· 在已有贷款情况下(房贷、车贷等),根据个人情况推荐更加优惠的贷款
· 用卡和贷款的信息指导服务
2. 商业模式分析
Credit Karma并不对信用服务进行收费,其收入来源主要为广告和佣金。由于Credit Karma掌握消费者的实际债务负担,包括债权人和债务利率等信息,系统通过挖掘数据并利用算法使用户看到符合自身需要的广告,也就是对网站用户进行个性化的推荐。佣金收入则来自于成功推荐信用卡、贷款以及其他金融服务。例如,A君一直使用B银行的贷款服务,而A君的信用分数提升了,B银行并不会主动通知A君以降低贷款利率,这时Credit Karma便会推荐更加优惠利率的C银行的贷款服务,而此时C银行则会返回Credit Karma一定数额的佣金作为介绍新用户的推介费。
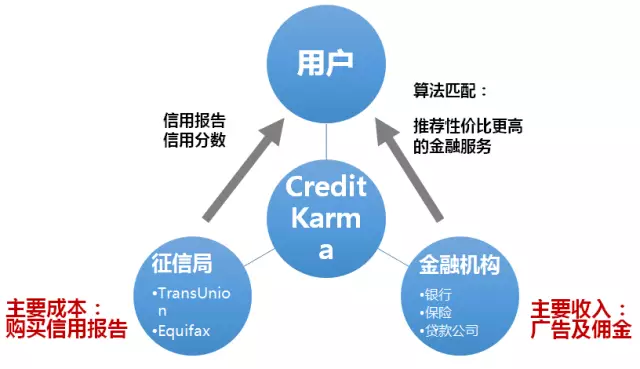
Credit Karma在众多金融机构的服务中解决了信息不对称的问题,为用户带来的价值是让他们以更优惠价格获得对应的金融产品和服务。而Credit Karma的主要成本为从信用局购买个人信用报告的成本,因此,只要为其用户成功推荐金融产品获得的返佣收入能够覆盖其从信用局购买信用报告的成本,Credit Karma就能实现盈利。
竞争对手分析
对应如此大的市场需求,Credit Karma也有不少竞争对手遇,例如:Credit Sesame、Quizzle、Mint.com,这些对手有的是通过提供免费月度信用报告获客,有的通过整合储蓄账户和信用卡账户吸引用户,然后提供理财和信贷产品获利。但通过下表对比,我们发现产品最全面的仍然是Credit Karma,这也是为何Credit Karma有更多用户的原因。
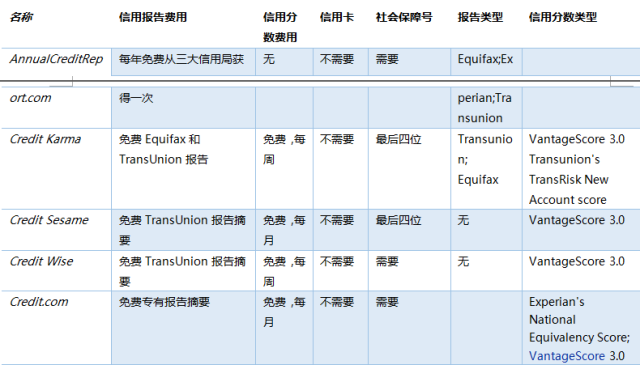
资料来源:Wikipedia
和传统征信的比较
传统征信机构的数据来源渠道多而且复杂,主要包括各种授信机构、保险业、零售商、公用事业公司、雇主、法院、电信等。主要的产品和服务包括信用报告、信用评分、信用监测、防欺诈、风险决策、市场营销和个人身份防盗用等;主要的盈利模式是出售信用产品和服务给授信机构和个人消费者。服务的对象以机构为主。下表为以Experian为例的传统个人征信机构和Credit Karma的比较。
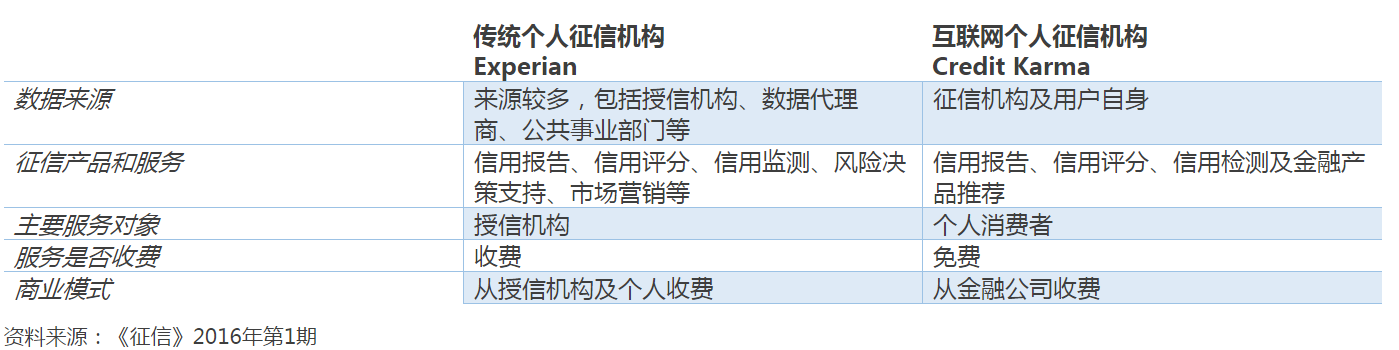
和Experian相比,Credit Karma还不能称之为个人征信机构,目前还未受到美国个人征信机构监管部门的监管,只能称之为征信产业链上的一个创新环节。但另一方面Credit Karma的模式很好的展现出互联网创新以用户为核心的价值观,从用户的角度思考,围绕用户的需求逐步丰富服务及产品,链接服务机构,从后端进行收费,只要抓住了用户,就存在着多种的可能性。未来,Kenneth希望Credit Karma能够提供更多的服务,包括整合助学贷款、比较保险报价、选择适合自己消费习惯的信用卡以及为购车融资,成为互联网的综合个人财富管家。
来源:玖富研究院















 4337
4337

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









