







本文转自:
整理–决策树算法:ID3和C4.5;
ID3&C4.5的区别;
ID3和C4.5是决策树算法中最经典的两种算法,下面将对两种算法分别介绍,在对两种方法进行比较。
一、 ID3算法
1.1 ID3基本概念:
- 决策树中每一个非叶结点对应着一个非类别属性,树枝代表这个属性的值。一个叶结点代表从树根到叶结点之间的路径对应的记录所属的类别属性值。
- 每一个非叶结点都将与属性中具有最大信息量的非类别属性相关联。
- 采用信息增益来选择能够最好地将样本分类的属性。
1.2 信息增益
从信息论知识中我们直到,期望信息越小,信息增益越大,从而纯度越高。所以ID3算法的核心思想就是以信息增益度量属性选择,选择分裂后信息增益最大的属性进行分裂。下面先定义几个要用到的概念。
设D为用类别对训练元组进行的划分,则D的熵(entropy)表示为:
其中pi表示第i个类别在整个训练元组中出现的概率,可以用属于此类别元素的数量除以训练元组元素总数量作为估计。熵的实际意义表示是D中元组的类标号所需要的平均信息量。
现在我们假设将训练元组D按属性A进行划分,则A对D划分的期望信息为:
而信息增益即为两者的差值:
1.3 举例说明
ID3算法就是在每次需要分裂时,计算每个属性的增益率,然后选择增益率最大的属性进行分裂。下面我们继续用SNS社区中不真实账号检测的例子说明如何使用ID3算法构造决策树。为了简单起见,我们假设训练集合包含10个元素:
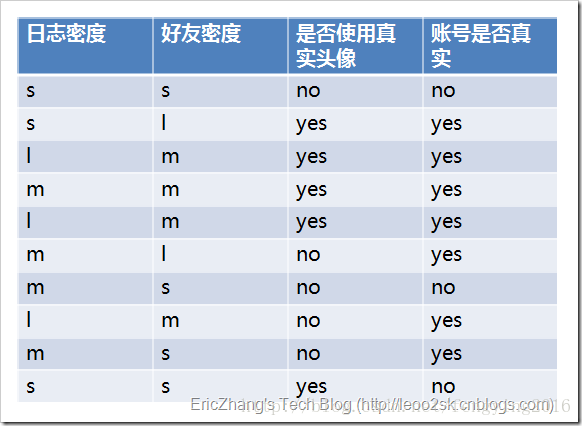
其中s、m和l分别表示小、中和大。
设L、F、H和R表示日志密度、好友密度、是否使用真实头像和账号是否真实,下面计算各属性的信息增益。
info(D)=−0.7log20.7−0.3log20.3=0.7∗0.51+0.3∗1.74=0.879
infoL(D)=0.3∗(−03log203−33log233)+0.4∗(−14log214−34log234)+0.3∗(−13log213−23log223)=0+0.326+0.277=0.603
gain(L)=0.879−0.603=0.276
因此日志密度的信息增益是0.276。用同样方法得到H和F的信息增益分别为0.033和0.553。因为F具有最大的信息增益,所以第一次分裂选择F为分裂属性,分裂后的结果如下图表示:
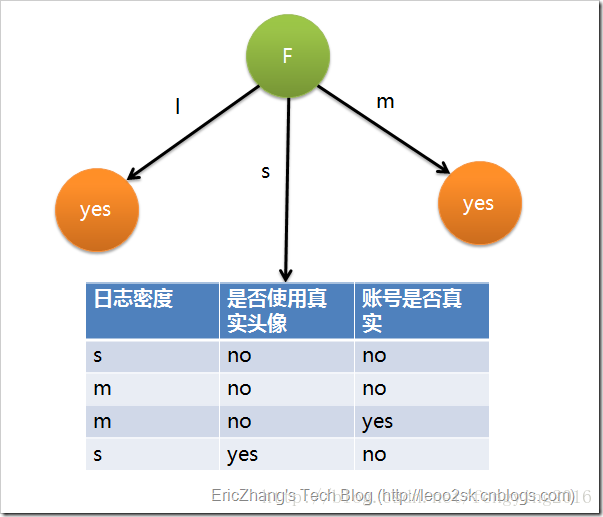
在上图的基础上,再递归使用这个方法计算子节点的分裂属性,最终就可以得到整个决策树。
上面为了简便,将特征属性离散化了,其实日志密度和好友密度都是连续的属性。对于特征属性为连续值,可以如此使用ID3算法:
先将D中元素按照特征属性排序,则每两个相邻元素的中间点可以看做潜在分裂点,从第一个潜在分裂点开始,分裂D并计算两个集合的期望信息,具有最小期望信息的点称为这个属性的最佳分裂点,其信息期望作为此属性的信息期望。
二、C4.5算法
ID3算法存在一个问题,就是偏向于多值属性,例如,如果存在唯一标识属性ID,则ID3会选择它作为分裂属性,这样虽然使得划分充分纯净,但这种划分对分类几乎毫无用处。ID3的后继算法C4.5使用增益率(gain ratio)的信息增益扩充,试图克服这个偏倚。
C4.5算法首先定义了“分裂信息”,其定义可以表示成:
其中各符号意义与ID3算法相同,然后,增益率被定义为:
C4.5选择具有最大增益率的属性作为分裂属性,其具体应用与ID3类似,不再赘述。
三、ID3&C4.5的区别
ID3算法是决策树的一个经典的构造算法,在一段时期内曾是同类研究工作的比较对象,但通过近些年国内外学者的研究,ID3算法也暴露出一些问题,具体如下:
(1)信息增益的计算依赖于特征数目较多的特征,而属性取值最多的属性并不一定最优。
(2)ID3是非递增算法。
(3)ID3是单变量决策树(在分枝节点上只考虑单个属性),许多复杂概念的表达困难,属性相互关系强调不够,容易导致决策树中子树的重复或有些属性在决策树的某一路径上被检验多次。
(4)抗噪性差,训练例子中正例和反例的比例较难控制。
于是Quilan改进了ID3,提出了C4.5算法。C4.5算法现在已经成为最经典的决策树构造算法,排名数据挖掘十大经典算法之首。严格上说C4.5只能是ID3的一个改进算法。C4.5算法继承了ID3算法的优点,并在以下几方面对ID3算法进行了改进:
(1) 用信息增益率来选择属性,克服了用信息增益选择属性时偏向选择取值多的属性的不足;
(2) 在树构造过程中进行剪枝;
(3) 能够完成对连续属性的离散化处理;
(4) 能够对不完整数据进行处理。
C4.5算法有如下优点:产生的分类规则易于理解,准确率较高。其缺点是:在构造树的过程中,需要对数据集进行多次的顺序扫描和排序,因而导致算法的低效。此外,C4.5只适合于能够驻留于内存的数据集,当训练集大得无法在内存容纳时程序无法运行。
另外,无论是ID3还是C4.5最好在小数据集上使用,决策树分类一般只试用于小数据。当属性取值很多时最好选择C4.5算法,ID3得出的效果会非常差。














 2065
2065











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









