







本文纯属记录今天的心情,一点技术的内容也没有,所以。。。。。大家懂的。。。。。
今天测试机调试完了之后,没问题了,三遍确定没问题了之后,parner跟我说放上正式环境试试,其实内心是有点拒绝的,正式环境啊,万一弄挂了岂不是罪恶滔天,但是又有点蠢蠢欲试,所以说干就干。怕死不当程序员,哈哈,放上去之后果然不出所料,挂了,挂了,挂了。然后用万能的(其实是只有一种方法)yarn logs -applicationId xxy来查看问题,然后我懵了,尼玛出现的问题我居然看不懂,看不懂,看不懂 ,然后火急火燎的去找管理员,然后他说他也不懂。当时那个心情真的是。。。。只有死马当活马医了,自己动手,老老实实的去看问题,人如果有依赖,很快就会放弃自己的潜力。终于看出一点端倪,原来是提交的时候参数设置有问题,结果导致一直说什么standby和vertual cores <0 的问题。嗯恩,改完之后,程序果然老老实实的报些看得懂的错误了,然后发现程序没有记录日志,然后急急忙忙的修改了一版放上去,最后看到程序一直running 的日志,心情真的那个舒畅。。。。。。
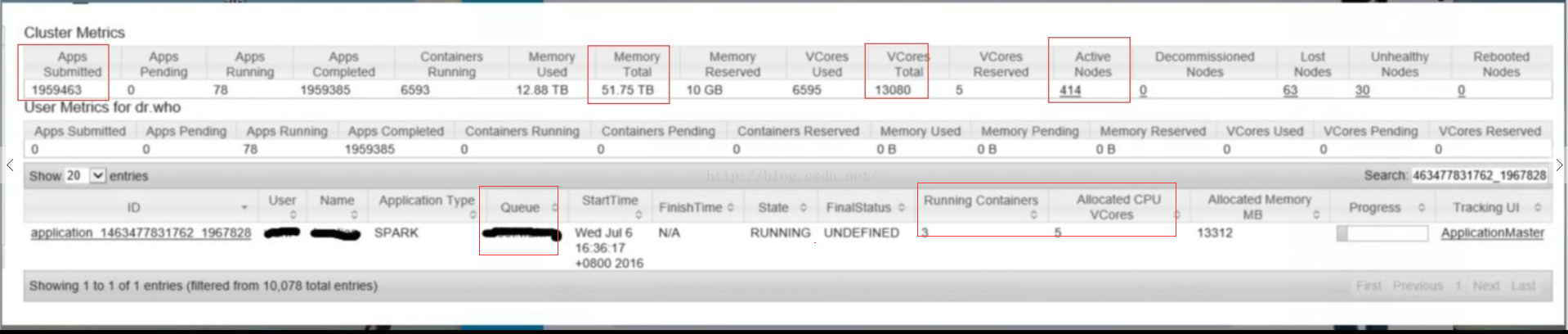
第一次见识到那么大的集群,说实在的,心里有点小激动。但是一看到分配给自己的资源,立马就蔫了,才3个container,5个core,以下是一些日志打印情况:
16/07/06 16:18:59 DEBUG ipc.ProtobufRpcEngine: Call: getListing took 65ms
16/07/06 16:18:59 INFO losuti.LosutiInfoService: [开始从Hdfs中读取数据,读取数据路径为:/data/xxyy/20160706/15]
16/07/06 16:18:59 ERROR losuti.LosutiInfoService: [从/data/xxxx/yyyy/20160706/15获取数据出错,出错信息为:]
java.lang.IllegalStateException: Cannot call methods on a stopped SparkContext
at org.apache.spark.SparkContext.org$apache$spark$SparkContext$$assertNotStopped(SparkContext.scala:104)
at org.apache.spark.SparkContext.defaultParallelism(SparkContext.scala:2061)
at org.apache.spark.SparkContext.defaultMinPartitions(SparkContext.scala:2074)
at org.apache.spark.SparkContext.textFile$default$2(SparkContext.scala:825)
at org.apache.spark.api.java.JavaSparkContext.textFile(JavaSparkContext.scala:184)
at com.telecom.losuti.LosutiInfoService.getCallRdd(LosutiInfoService.java:195)
at com.telecom.losuti.LosutiInfoService.main(LosutiInfoService.java:84)
at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method)
at sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:57)
at sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43)
at java.lang.reflect.Method.invoke(Method.java:606)
at org.apache.spark.deploy.yarn.ApplisutiMaster$$anon$2.run(ApplisutiMaster.scala:525)
16/07/06 16:18:59 DEBUG ipc.Client: IPC Client (1554752953) connection to NM-304-RH5885V3-BIGDATA-002/10.142.113.2:54310 from wzfw sending #40
16/07/06 16:18:59 DEBUG ipc.Client: IPC Client (1554752953) connection to NM-304-RH5885V3-BIGDATA-002/10.142.113.2:54310 from wzfw got value #40
16/07/06 16:18:59 DEBUG ipc.ProtobufRpcEngine: Call: getFileInfo took 35ms
16/07/06 16:18:59 DEBUG ipc.Client: IPC Client (1554752953) connection to NM-304-RH5885V3-BIGDATA-002/10.142.113.2:54310 from wzfw sending #41
16/07/06 16:18:59 DEBUG ipc.Client: IPC Client (1554752953) connection to NM-304-RH5885V3-BIGDATA-002/10.142.113.2:54310 from wzfw got value #41
16/07/06 16:18:59 DEBUG ipc.ProtobufRpcEngine: Call: getListing took 39ms
16/07/06 16:18:59 INFO losuti.LosutiInfoService: [开始从Hdfs中读取数据,读取数据路径为:/data/xxyy/20160706/15]
16/07/06 16:18:59 ERROR losuti.LosutiInfoService: [从/data/data/xxyy/20160706/15获取数据出错,出错信息为:]
java.lang.IllegalStateException: Cannot call methods on a stopped SparkContext
at org.apache.spark.SparkContext.org$apache$spark$SparkContext$$assertNotStopped(SparkContext.scala:104)
at org.apache.spark.SparkContext.defaultParallelism(SparkContext.scala:2061)
at org.apache.spark.SparkContext.defaultMinPartitions(SparkContext.scala:2074)
at org.apache.spark.SparkContext.textFile$default$2(SparkContext.scala:825)
at org.apache.spark.api.java.JavaSparkContext.textFile(JavaSparkContext.scala:184)
at com.telecom.losuti.LosutiInfoService.getCallRdd(LosutiInfoService.java:195)
at com.telecom.losuti.LosutiInfoService.main(LosutiInfoService.java:84)
at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method)
at sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:57)
at sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43)
at java.lang.reflect.Method.invoke(Method.java:606)
at org.apache.spark.deploy.yarn.ApplisutiMaster$$anon$2.run(ApplisutiMaster.scala:525)
16/07/06 16:18:59 DEBUG ipc.Client: IPC Client (1554752953) connection to NM-304-RH5885V3-BIGDATA-002/10.142.113.2:54310 from wzfw sending #42
16/07/06 16:18:59 DEBUG ipc.Client: IPC Client (1554752953) connection to NM-304-RH5885V3-BIGDATA-002/10.142.113.2:54310 from wzfw got value #42
16/07/06 16:18:59 DEBUG ipc.ProtobufRpcEngine: Call: getFileInfo took 55ms
16/07/06 16:18:59 DEBUG ipc.Client: IPC Client (1554752953) connection to NM-304-RH5885V3-BIGDATA-002/10.142.113.2:54310 from wzfw sending #43
16/07/06 16:18:59 DEBUG ipc.Client: IPC Client (1554752953) connection to NM-304-RH5885V3-BIGDATA-002/10.142.113.2:54310 from wzfw got value #43
16/07/06 16:18:59 DEBUG ipc.ProtobufRpcEngine: Call: getFileInfo took 40ms
16/07/06 16:18:59 DEBUG ipc.Client: IPC Client (1554752953) connection to NM-304-RH5885V3-BIGDATA-002/10.142.113.2:54310 from wzfw sending #44
16/07/06 16:18:59 DEBUG ipc.Client: IPC Client (1554752953) connection to NM-304-RH5885V3-BIGDATA-002/10.142.113.2:54310 from wzfw got value #44
16/07/06 16:18:59 DEBUG ipc.ProtobufRpcEngine: Call: getListing took 35ms
16/07/06 16:18:59 INFO losuti.LosutiInfoService: [开始从Hdfs中读取数据,读取数据路径为:/data/xxyy/20160706/15]
16/07/06 16:18:59 ERROR losuti.LosutiInfoService: [从/data/xxyy/20160706/15获取数据出错,出错信息为:]
java.lang.IllegalStateException: Cannot call methods on a stopped SparkContext
at org.apache.spark.SparkContext.org$apache$spark$SparkContext$$assertNotStopped(SparkContext.scala:104)
at org.apache.spark.SparkContext.defaultParallelism(SparkContext.scala:2061)
at org.apache.spark.SparkContext.defaultMinPartitions(SparkContext.scala:2074)
at org.apache.spark.SparkContext.textFile$default$2(SparkContext.scala:825)
at org.apache.spark.api.java.JavaSparkContext.textFile(JavaSparkContext.scala:184)
at com.telecom.losuti.LosutiInfoService.getCallRdd(LosutiInfoService.java:195)
at com.telecom.losuti.LosutiInfoService.main(LosutiInfoService.java:84)
at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method)
at sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:57)
at sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43)
at java.lang.reflect.Method.invoke(Method.java:606)
at org.apache.spark.deploy.yarn.ApplisutiMaster$$anon$2.run(ApplisutiMaster.scala:525)
虽然是跑通了,但是一个应用跑下来半个小时妥妥的,半个小时啊,这个mr有什么区别,今天过来的时候发现居然相同的任务要2个小时,没错,绝对没看错,超过了两个小时。这是绝对不能接受的,因此大家开始了优化代码的讨论了,讨论来讨论去,结果代码没有什么需要修改的。其实我一直有个疑问,为什么会给我分配那么少的资源呢,后来才知道其实是分配了好多的资源,只是分配给应用的很少。所以我尝试着修改了一下参数如下:
/home/wzfw/spark-1.5.1/bin/spark-submit --name loc--master yarn-cluster --driver-memory 8g --executor-memory 8g --executor-cores 4 --num-executors 1600 --class com.tel.loc.LocService /home/fw/jars/loc-0.0.1-SNAPSHOT.jar $1 $2 10
--driver-memory 8g --executor-memory 8g --executor-cores 4 --num-executors 1600主要修改了这几个参数,其中--num-executors 1600是最为关键的。1600个并发。
然后神奇的只用了2分钟不到。我去,果断关机回家














 5302
5302











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









