







 本文详述了Lucene的段合并过程,包括合并策略的选择、反向信息的合并,以及段合并的详细步骤,如存储域、词向量、标准化因子、词典和倒排表的合并。分析了LogMergePolicy如何选择合并段,并描述了ConcurrentMergeScheduler如何执行合并任务。
本文详述了Lucene的段合并过程,包括合并策略的选择、反向信息的合并,以及段合并的详细步骤,如存储域、词向量、标准化因子、词典和倒排表的合并。分析了LogMergePolicy如何选择合并段,并描述了ConcurrentMergeScheduler如何执行合并任务。
一、段合并过程总论
IndexWriter中与段合并有关的成员变量有:
- HashSet<SegmentInfo> mergingSegments = new HashSet<SegmentInfo>(); //保存正在合并的段,以防止合并期间再次选中被合并。
- MergePolicy mergePolicy = new LogByteSizeMergePolicy(this);//合并策略,也即选取哪些段来进行合并。
- MergeScheduler mergeScheduler = new ConcurrentMergeScheduler();//段合并器,背后有一个线程负责合并。
- LinkedList<MergePolicy.OneMerge> pendingMerges = new LinkedList<MergePolicy.OneMerge>();//等待被合并的任务
- Set<MergePolicy.OneMerge> runningMerges = new HashSet<MergePolicy.OneMerge>();//正在被合并的任务
和段合并有关的一些参数有:
- mergeFactor:当大小几乎相当的段的数量达到此值的时候,开始合并。
- minMergeSize:所有大小小于此值的段,都被认为是大小几乎相当,一同参与合并。
- maxMergeSize:当一个段的大小大于此值的时候,就不再参与合并。
- maxMergeDocs:当一个段包含的文档数大于此值的时候,就不再参与合并。
段合并一般发生在添加完一篇文档的时候,当一篇文档添加完后,发现内存已经达到用户设定的ramBufferSize,则写入文件系统,形成一个新的段。新段的加入可能造成差不多大小的段的个数达到mergeFactor,从而开始了合并的过程。
合并过程最重要的是两部分:
- 一个是选择哪些段应该参与合并,这一步由MergePolicy来决定。
- 一个是将选择出的段合并成新段的过程,这一步由MergeScheduler来执行。段的合并也主要包括:
- 对正向信息的合并,如存储域,词向量,标准化因子等。
- 对反向信息的合并,如词典,倒排表。
在总论中,我们重点描述合并策略对段的选择以及反向信息的合并。
1.1、合并策略对段的选择
在LogMergePolicy中,选择可以合并的段的基本逻辑是这样的:
- 选择的可以合并的段都是在硬盘上的,不再存在内存中的段,也不是像早期的版本一样每添加一个Document就生成一个段,然后进行内存中的段合并,然后再合并到硬盘中。
- 由于从内存中flush到硬盘上是按照设置的内存大小来DocumentsWriter.ramBufferSize触发的,所以每个刚flush到硬盘上的段大小差不多,当然不排除中途改变内存设置,接下来的算法可以解决这个问题。
- 合并的过程是尽量按照合并几乎相同大小的段这一原则,只有大小相当的mergeFacetor个段出现的时候,才合并成一个新的段。
- 在硬盘上的段基本应该是大段在前,小段在后,因为大段总是由小段合并而成的,当小段凑够mergeFactor个的时候,就合并成一个大段,小段就被删除了,然后新来的一定是新的小段。
- 比如mergeFactor=3,开始来的段大小为10M,当凑够3个10M的时候,0.cfs, 1.cfs, 2.cfs则合并成一个新的段3.cfs,大小为30M,然后再来4.cfs, 5.cfs, 6.cfs,合并成7.cfs,大小为30M,然后再来8.cfs, 9.cfs, a.cfs合并成b.cfs, 大小为30M,这时候又凑够了3个30M的,合并成90M的c.cfs,然后又来d.cfs, e.cfs, f.cfs合并成10.cfs,大小为30M,然后11.cfs大小为10M,这时候硬盘上的段为:c.cfs(90M) 10.cfs(30M),11.cfs(10M)。
所以LogMergePolicy对合并段的选择过程如下:
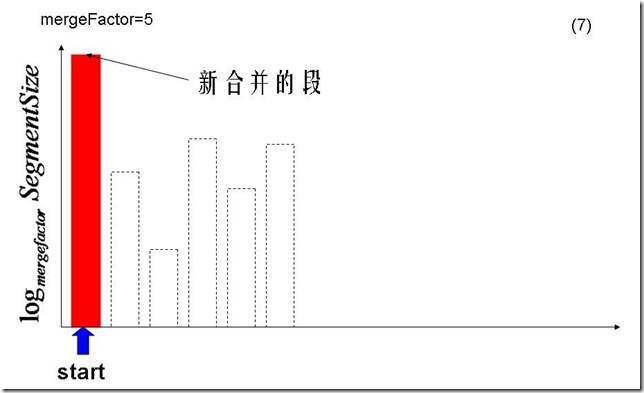
- 将所有的段按照生成的顺序,将段的大小以mergeFactor为底取对数,放入数组中,作为选择的标准。

- 从头开始,选择一个值最大的段,然后将此段的值减去0.75(LEVEL_LOG_SPAN) ,之间的段被认为是大小差不多的段,属于同一阶梯,此处称为第一阶梯。
- 然后从后向前寻找第一个属于第一阶梯的段,从start到此段之间的段都被认为是属于这一阶梯的。也包括之间生成较早但大小较小的段,因为考虑到以下几点:
- 防止较早生成的段由于人工flush或者人工调整ramBufferSize,因而很小,却破坏了基本从大到小的规则。
- 如果运行较长时间后,致使段的大小参差不齐,很难合并相同大小的段。
- 也防止一个段由于较小,而不断的都有大的段生成从而始终不能参与合并。
- 第一阶梯总共4个段,小于mergeFactor因而不合并,接着start=end从而选择下一阶梯。

- 从start开始,选择一个值最大的段,然后将此段的值减去0.75(LEVEL_LOG_SPAN) ,之间的段被认为属于同一阶梯,此处称为第二阶梯。
- 然后从后向前寻找第一个属于第二阶梯的段,从start到此段之间的段都被认为是属于这一阶梯的。
- 第二阶梯总共4个段,小于mergeFactor因而不合并,接着start=end从而选择下一阶梯。

- 从start开始,选择一个值最大的段,然后将此段的值减去0.75(LEVEL_LOG_SPAN) ,之间的段被认为属于同一阶梯,此处称为第三阶梯。
- 由于最大的段减去0.75后为负的,因而从start到此段之间的段都被认为是属于这一阶梯的。
- 第三阶梯总共5个段,等于mergeFactor,因而进行合并。

- 第三阶梯的五个段合并成一个较大的段。
- 然后从头开始,依然先考察第一阶梯,仍然是4个段,不合并。
- 然后是第二阶梯,因为有了新生成的段,并且大小足够属于第二阶梯,从而第二阶梯有5个段,可以合并。

- 第二阶段的五个段合并成一个较大的段。
- 然后从头开始,考察第一阶梯,因为有了新生成的段,并且大小足够属于第一阶梯,从而第一阶梯有5个段,可以合并。

- 第一阶梯的五个段合并成一个大的段。
1.2、反向信息的合并
反向信息的合并包括两部分:
- 对字典的合并,词典中的Term是按照字典顺序排序的,需要对词典中的Term进行重新排序
- 对于相同的Term,对包含此Term的文档号列表进行合并,需要对文档号重新编号。
对词典的合并需要找出两个段中相同的词,Lucene是通过一个称为match的SegmentMergeInfo类型的数组以及称为queue的 SegmentMergeQueue实现的,SegmentMergeQueue是继承于 PriorityQueue<SegmentMergeInfo>,是一个优先级队列,是按照字典顺序排序的。 SegmentMergeInfo保存要合并的段的词典及倒排表信息,在SegmentMergeQueue中用来排序的key是它代表的段中的第一个 Term。
我们来举一个例子来说明合并词典的过程,以便后面解析代码的时候能够很好的理解:
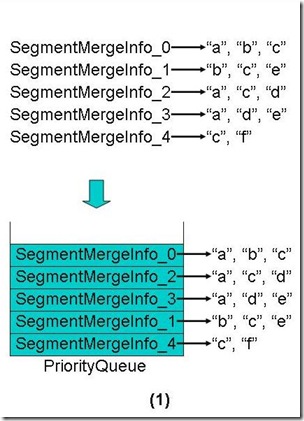
- 假设要合并五个段,每个段包含的Term也是按照字典顺序排序的,如下图所示。
- 首先把五个段全部放入优先级队列中,段在其中也是按照第一个Term的字典顺序排序的,如下图。
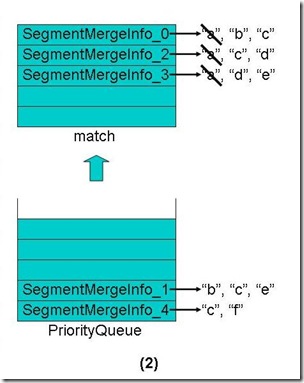
- 从优先级队列中弹出第一个Term("a")相同的段到match数组中,如下图。
- 合并这些段的第一个Term("a")的倒排表,并把此Term和它的倒排表一同加入新生成的段中。
- 对于match数组中的每个段取下一个Term
- 将match数组中还有Term的段重新放入优先级队列中,这些段也是按照第一个Term的字典顺序排序。
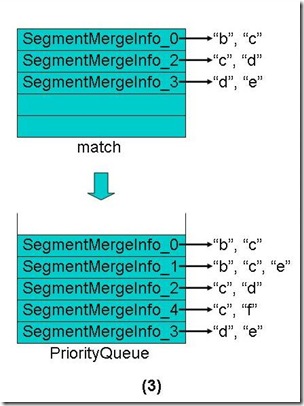
- 从优先级队列中弹出第一个Term("b")相同的段到match数组中。
- 合并这些段的第一个Term("b")的倒排表,并把此Term和它的倒排表一同加入新生成的段中。
- 对于match数组中的每个段取下一个Term
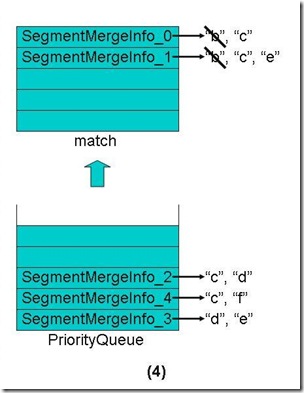
- 将match数组中还有Term的段重新放入优先级队列中,这些段也是按照第一个Term的字典顺序排序。

- 从优先级队列中弹出第一个Term("c")相同的段到match数组中。
- 合并这些段的第一个Term("c")的倒排表,并把此Term和它的倒排表一同加入新生成的段中。
- 对于match数组中的每个段取下一个Term

- 将match数组中还有Term的段重新放入优先级队列中,这些段也是按照第一个Term的字典顺序排序。

- 从优先级队列中弹出第一个Term("d")相同的段到match数组中。
- 合并这些段的第一个Term("d")的倒排表,并把此Term和它的倒排表一同加入新生成的段中。
- 对于match数组中的每个段取下一个Term

- 将match数组中还有Term的段重新放入优先级队列中,这些段也是按照第一个Term的字典顺序排序。
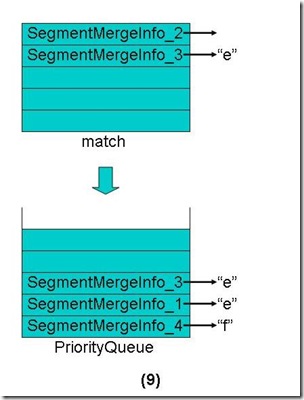
- 从优先级队列中弹出第一个Term("e")相同的段到match数组中。
- 合并这些段的第一个Term("e")的倒排表,并把此Term和它的倒排表一同加入新生成的段中。
- 对于match数组中的每个段取下一个Term

- 将match数组中还有Term的段重新放入优先级队列中,这些段也是按照第一个Term的字典顺序排序。

- 从优先级队列中弹出第一个Term("f")相同的段到match数组中。
- 合并这些段的第一个Term("f")的倒排表,并把此Term和它的倒排表一同加入新生成的段中。
- 对于match数组中的每个段取下一个Term
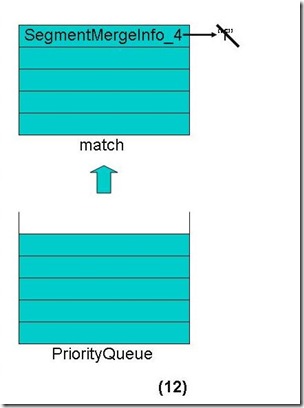
- 合并完毕。
二、段合并的详细过程
2.1、将缓存写入新的段
IndexWri
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 1267
1267

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









