







=====================================================================
《机器学习实战》系列博客是博主阅读《机器学习实战》这本书的笔记也包含一些其他python实现的机器学习算法
github 源码同步:https://github.com/Thinkgamer/Machine-Learning-With-Python
算法实现均采用Python 如需转载请注明出处,谢谢
=====================================================================
2:AdaBoost算法的理解和代码实现
3:分类性能度量指标
一些基本概念
元算法(meta-algorithm,又称为集成方法(ensemblemethod)
):是对其他一些算法进行组合的一种方式(当下最流行的元算法是AdaBoost算法),使用集成方法时会有多种形式,可以是不同的算法的集成,也可以是同一种算法在不同设置下的集成,还可以是数据集不同部分分给不同分类器之后的集成
自举汇聚法(bootstrap aggregating),也称为bagging方法,是在从原始数据集选择S次后得到S个新数据集的一种技术,不同的分类器是通过串行训练而获得的,每个新分类器都根据已经训练出的分类器来进行训练
boosting:是一种与bagging很类似的技术,通过集中关注被已有分类器错分的那些数据来获得新的分类器
bagging和boosting算法的不同之处:
(1):获得新分类器的方法不同
(2):分类器权重不同,bagging中分类器的权重是相等的,而boosting中的分类器权重并不相等
AdaBoost算法的原理理解
1:AdaBoost算法的一般流程
(1):收集数据,可以使用任意方法
(2):准备数据,依赖于所使用的弱分类器类型,本章使用的是单层决策树,这种分类器可以处理任何类型的数据,当然也可以使用任意分类器作为弱分类器,作为弱分类器,简单的分类器效果更好
(3):分析数据,可以使用任意方法
(4):训练算法,AdaBoost的大部分时间都用在训练上,分类器将多次在同一数据集上训练弱分类器
(5):测试算法,计算分类的错误率
(6):使用算法,同SVM一样,AdaBoost预测两个类别中的一个,如果想把他应用到多个类别的场合,那么就要象多类SVM中的做法一样对AdaBoos进行修改
2:训练算法,基于错误提升分类器的性能
AdaBoost是adaptive boosting(自适应boosts)的缩写,其运行过程如下:
训练数据中的每
个样本,并赋予其一个权重,这些权重构成了向量D。一开始,这些权重都初始化成相等值。首
先在训练数据上训练出一个弱分类器并计算该分类器的错误率,然后在同一数据集上再次训练弱
分类器。在分类器的第二次训练当中,将会重新调整每个样本的权重,其中第一次分对的样本的
权重将会降低,而第一次分错的样本的权重将会提高。为了从所有弱分类器中得到最终的分类结
果,AdaBoost为每个分类器都分配了一个权重值alpha,这些alpha值是基于每个弱分类器的错误
率进行计算的。其中,错误率£的定义为:

而alpha的计算公式如下:
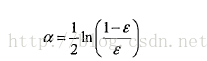
AdaBoost算法的流程如下:
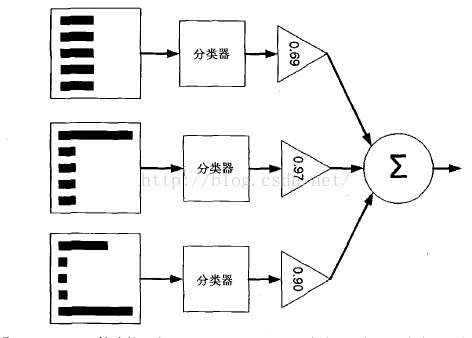
AdaBoost算
法的示意图。左边是数据集,其中直方图的不同宽度表示每个样例
上的不同权重。
在经过一个分类器之后,加权的预测结果会通过三角形中的alpha
进行加权。
每个三角形中输出的加权结果在圆形中求和,从而得到最终
的输出结果
计算出
alpha值之后,可以对权重向量D进行更新,以使得那些正确分类的样本的权重降低而
错分样本的权重升高。D的计算方法如下。
如果某个样本被正确分类,那么该样本的权重更改为:
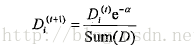
而如果某个样本被错分,那么该样本的
权重更改为:
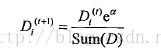
在计算出alpha之后,Adaboost又开始进入下一轮迭代。AdaBoost算法会不断地重复训练和调整
权重的过程,直到训练错误率为0或者弱分类器的数目达到用户的指定值为止。
接下来,我们将建立完整的Adaboost算法。在这之前,我们首先必须通过一些代码来建立弱
分类器及保存数据集的权重。
3:基于单层决策树构建弱分类器
单层决策树(decision stump , 也称决策树桩)是一种简单的决策树。前面我们已经介绍了决
策树的工作原理,接下来将构建一个单层决策树,而它仅基于单个特征来彳故决策。由于这棵树只
有一次分裂过程,因此它实际上就是一个树桩。
在构造AdaBoost的代码时,我们将首先通过一个简单数据集来确保在算法实现上一切就绪。
然后,建立一个叫adaboost.py的新文件并加入如下代码:
#加载数据集
def loadSimData():
datMat = matrix([[1.0 , 2.1],
[2. , 1.1],
[1.3 , 1. ],
[1. , 1. ],
[2. , 1. ]])
classLabels = [1.0, 1.0, -1.0, -1.0, 1.0]
return datMat,classLabels
#main函数
if __name__=="__main__":
#加载数据集
datMat,classLabels = loadSimData()
print "datMat:",datMat
print "classLabels:",classLabels
输出为:

单层决策树的伪代码看起来更像:
将最小错误率1^旭1^01设为+00
对数据集中的每一个特征(第一层循环):
对每个步长(第二层循环):
对每个不等号(第三层循环):
建立一棵单层决策树并利用加权数据集对它进行测试
如果错误率低于m in Err0r,则将当前单层决策树设为最佳单层决策树
返回最佳单雇决策树
#单层决策树生成函数
def stumpClassify(dataMatrix, dimen,threshVal, threshInsq):
retArray = ones((shape(dataMatrix)[0],1))
if threshInsq == 'lt':
retArray[dataMatrix[:,dimen] <= threshVal] = -1.0
else:
retArray[dataMatrix[:,dimen] > threshVal] = -1.0
return retArray
def buildStump(dataArr,classLabels,D):
dataMatrix = mat(dataArr)
#matrix必须是二维的,numpy可以是多维的
labelMat = mat(classLabels).T #.T表示转置矩阵
m,n = shape(dataMatrix) #给定数据集的行列数
numSteps = 10.0 #变用于在特征的所有可能值上进行遍历
bestStump = {} #字典用于存储给定权重向量0时所得到的最佳单层决策树的相关信息
bestClassEnt = mat(zeros((m,1)))
minError = inf #首先将minError初始化为正无穷大
for i in range(n):
rangeMin = dataMatrix[:,i].min()
rangeMax = dataMatrix[:,i].max()
stepSize = (rangeMax-rangeMin)/numSteps
for j in range(-1,int(numSteps)+1):
#lt :小于,lte,le:小于等于
#gt:大于,,gte,ge:大于等于
#eq:等于 ne,neq:不等于
for inequal in ['lt','gt']:
threshVal = (rangeMin + float(j) * stepSize)
predictedVals = stumpClassify(dataMatrix,i,threshVal, inequal)
errArr = mat(ones((m,1)))
errArr[predictedVals==labelMat]=0
weightedError = D.T * errArr #计算加权错误概率
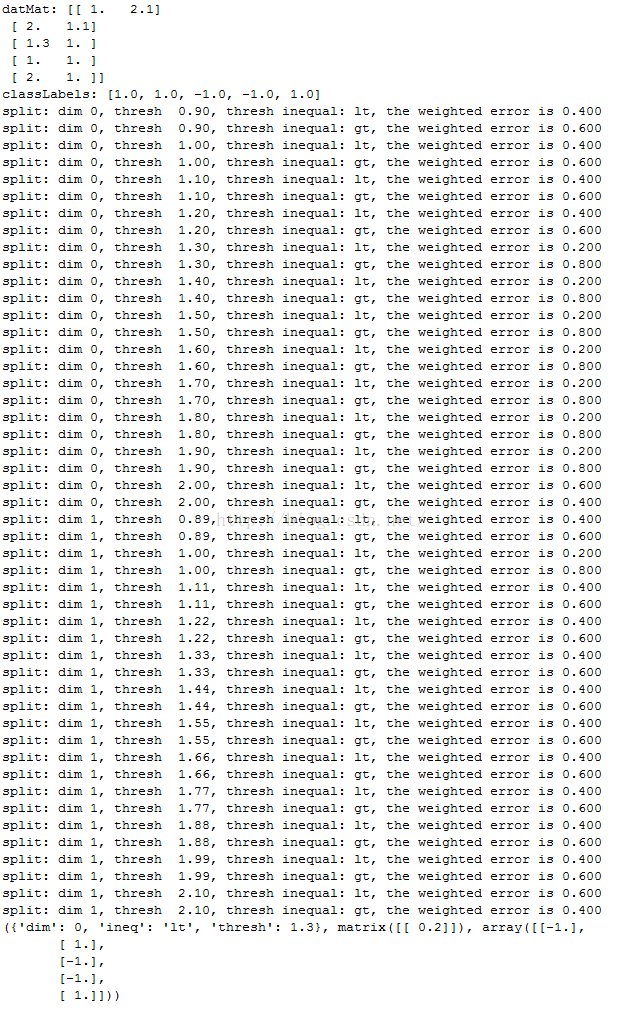
print "split: dim %d, thresh % .2f, thresh inequal: %s, the weighted error is %.3f" % (i, threshVal,inequal,weightedError)
#更新bestStump中保存的最佳单层决策树的相关信息
if weightedError < minError:
minError = weightedError
bestClassEnt = predictedVals.copy()
bestStump['dim'] = i
bestStump['thresh'] = threshVal
bestStump['ineq'] = inequal
return bestStump,minError,bestClassEnt
main函数中添加:
#单层决策树生成函数
D = mat(ones((5,1))/5)
print buildStump(datMat, classLabels, D)
测试输出为:
4:完整AdaBoost算法的实现
伪代码如下:
对每次迭代:
利用^^11(53匕1:0即()函数找到最佳的单层决策树
将最佳单层决策树加入到单层决策树数组
计算alpha
计算新的权重向量D
更新累计类别估计值
如果错误率等于0.0,则退出循环
在adaboost.py中加入以下代码:
#基于单层决策树的AdaBoost训练过程
#numIt:迭代次数,默认为40
def adaBoostTrainDS(dataArr,classLabels,numIt=40):
weakClassArr = []
m= shape(dataArr)[0]
D = mat(ones((m,1))/m)
aggClassEst = mat(zeros((m,1)))
#迭代
for i in range(numIt):
#调用单层决策树
bestStump,error,classEst = buildStump(dataArr, classLabels, D)
print "D:",D.T #打印D的转置矩阵
alpha = float(0.5 * log((1.0 - error) / max(error,1e-16)))
bestStump['alpha'] = alpha
weakClassArr.append(bestStump)
print "classEst:",classEst.T
#为下一次迭代计算D
expon = multiply(-1 * alpha * mat(classLabels).T,classEst)
D = D /D.sum()
#错误率累加计算
aggClassEst += alpha* classEst
print "aggClassEst:",aggClassEst.T
aggErrors = multiply(sign(aggClassEst) != mat(classLabels).T, ones((m,1)))
errorRate = aggErrors.sum()/m
print "total error:",errorRate
#如果不发生错误,返回
if errorRate == 0.0:
break
return weakClassArr
在main函数加入
#基于单层决策树的Adaboost训练过程
classifierArray = adaBoostTrainDS(datMat, classLabels, 9)
print classifierArray
代码运行的输出结果是:

5:测试算法,基于AdaBoost的分类
#AdaBoost分类函数
#输入参数为待分类样例datToClass和多个弱分类器classifierArr
def adaClassify(datToClass,classifierArr):
dataMatrix = mat(datToClass)
m = shape(dataMatrix)[0]
aggClassEst = mat(zeros((m,1)))
for i in range(len(classifierArr)):
classEst = stumpClassify(dataMatrix,classifierArr[i]['dim'],\
classifierArr[i]['thresh'],\
classifierArr[i]['ineq'])
aggClassEst+= classifierArr[i]['alpha'] * classEst
print aggClassEst
return sign(aggClassEst)
main函数中加入:
#测试AdaBoost分类函数
print "[0,0]:\n",adaClassify([0,0], classifierArray)
print "\n\n[[5,5],[0,0]]:\n",adaClassify([[5,5],[0,0]], classifierArray)
输出结果为:

我们可以发现随着迭代次数的增加,数据集的分类效果会越来越强
分类性能度量指标
错误率:
错误率指的是在所有测
试样例中错分的样例比例
针对二类问题的混淆矩阵:

在这个二类问题中,如果把一个正例类判定为正例,
那么就可以认为产生了一个
真正例(TmePositive, TP ,也称真阳);如果对一个反例正确地判为反例,则认为产生了一个
反例(TrueNegative, TN ,也称真阴)。相应地,另外两种情况贝彳分别称为伪反例(FalseNegative,
FN ,也称假阴)和伪正例(FalsePositive, FP ,也称假阳)
正确率(Precision)=TP/(TP + FP) ,
给出的是预测为正例的
样本中的真正正例的比例。
召回率(Recall)=TP/(TP+FN),
给出的是预测为正
例的真实正例占所有真实正例的比例。
我们可以很容易构造一个高正确率或高召回率的分类器,但是很难同时保证两者成立。如果
将任何样本都判为正例,那么召回率达到百分之百而此时正确率很低。构建一个同时使正确率和
召回率最大的分类器是具有挑战性的。
另一个用于度量分类中的非均衡性的工具是ROC 曲线(R O C curve ),ROC 代表接收者操作特
征(receiver operating characteristic)
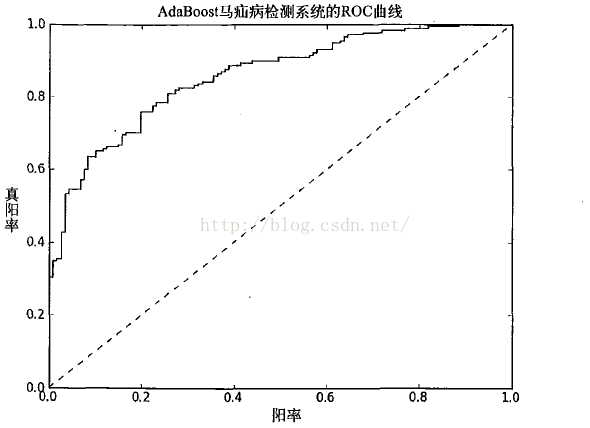
在上图的ROC曲线中,给出了两条线,一条虚线一条实线。图中的横轴是伪正例的比例(假
阳率=FP/(FP+TN)),而纵轴是真正例的比例(真阳率=
FP/(FP+TN)
)。ROC
曲线给出的是当阈值
变化时假阳率和真阳率的变化情况。左下角的点所对应的是将所有样例判为反例的情况,而右上
角的点对应的则是将所有样例判为正例的情况。虚线给出的是随机猜测的结果曲线。
ROC
曲线不但可以用于比较分类器,还可以基于成本效益(cost-versus-benefit) 分析来做出
决策。由于在不同的阈值下,不同的分类器的表现情况可能各不相同,因此以某种方式将它们组
合起来或许会更有意义。如果只是简单地观察分类器的错误率,那么我们就难以得到这种更深人
的洞察效果了。
在理想的情况下,最佳的分类器应该尽可能地处手左上角,这就意味着分类器在假阳率很低
的同时获得了很高的真阳率。例如在垃圾邮件的过滤中,这就相当于球滤了所有的垃圾邮件,但
没有将任何合法邮件误识为垃圾邮件而放入垃圾邮件的文件夹中。
对不同的ROC
曲线进行比较的一个指标是曲线下的面积(AreaUnsertheCurve, A U C )。A U C
给出的是分类器的平均性能值,当然它并不能完全代替对整条曲线的观察。一个完美分类器的
A U C ^ / 1 . 0 ,而随机猜测的AUC则为0.5。

















 11万+
11万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









