







- 实验目的
1、编程实现Adaboost,对所提供数据进行分类
2、训练集和测试集分别在train.txt和test.txt,数据形式为[x1, x2, y],其中x1,x2为样本属性,y为对应类别
- 实验内容:
1、数据中含有“[”,“]”python读入时不能自己处理,所以使用f.readlines将内容读为字符串,遍历每一行,去除行末回车和左右中括号,数据转为float类型,并且将属性和标签分开,分别放到data和lable中返回。
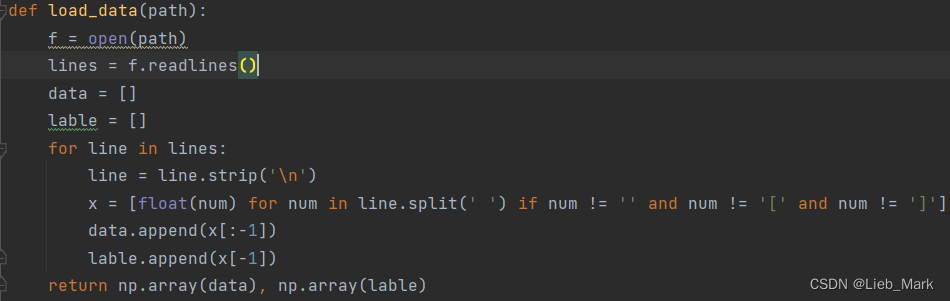
2、函数G是求当前分类器的预测结果以及错误率。传入的数据是数据集中取出单个属性的值、标签、阈值v、规则(大于等于阈值为1,还是小于阈值为1)和权值D。功能是遍历data,参考规则,将属性值和阈值进行比较,得出预测值,如果分类错误,则将其权重加入e。
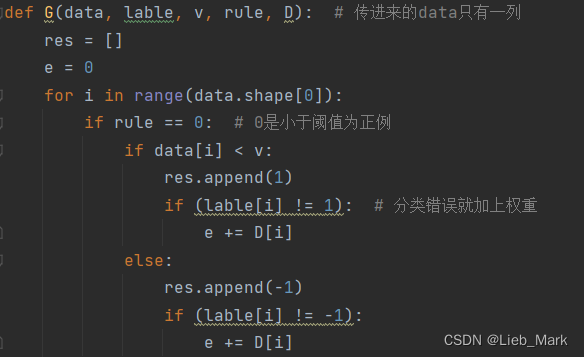

3、单个分类器的构建,思路是枚举x的所有属性,每种属性挑选一个阈值和判定规则,使用G函数计算误差,选择误差最小的组合,存入字典并返回。
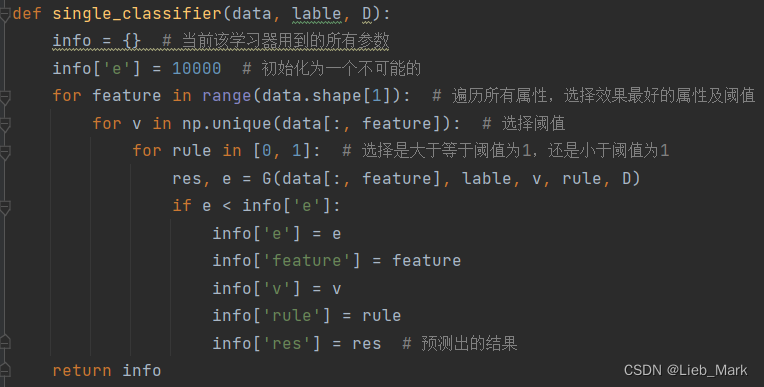
4、使用adaboost算法进行集成学习,权重D的每一项初始化为1/n,n是数据个数。参数num设为10,经过测试10次就可以达到很好的效果。循环num次,每次使用函数single_classifier生成一个基学习器,并且测试正确率,根据西瓜书上写的,如果当前基学习器的效果还不如随机分类(正确率小于0.5)就退出。
学习器权重alpha可由![]() 求出,D也需要进行更新,公式为
求出,D也需要进行更新,公式为![]() ,
,![]() ,当标签和预测值相等时,y*G同号,权重减小,否则权重增大,这样下次就会重点关注这些数据。
,当标签和预测值相等时,y*G同号,权重减小,否则权重增大,这样下次就会重点关注这些数据。
5、对分类结果进行测试和可视化,将每个数据通过所有分类器进行投票确定结果,将每个分类器的结果乘以每个分类器的权重,再进行求和,大于0则为1,否则为-1。同时进行正确率计算,并根据分类结果对数据使用plt画出。
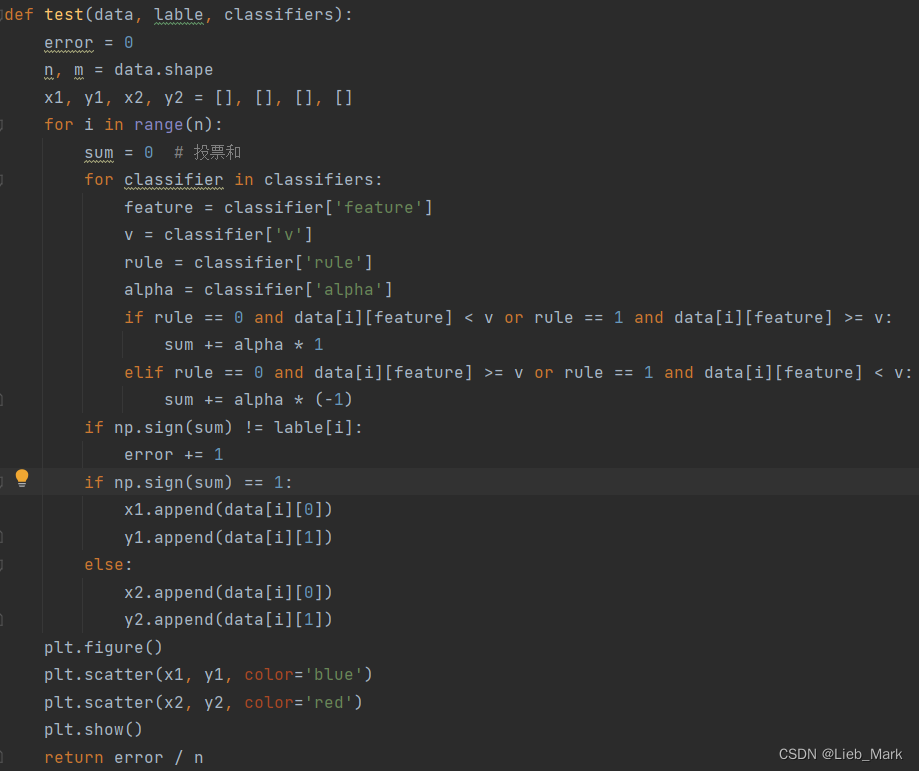
实验结果:
测试集的正确率为100%,每个分类器的信息如下:

对测试集的分类情况:
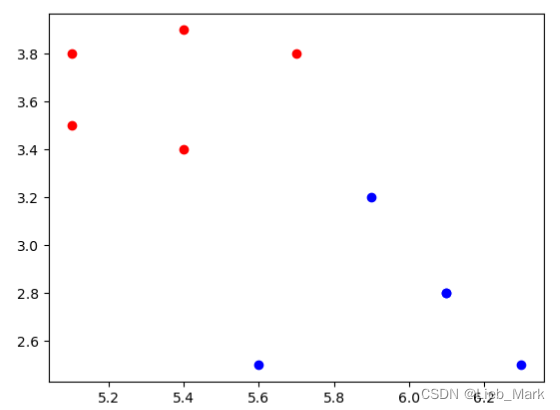
训练集的分类正确率也是100%
- 实验原理:





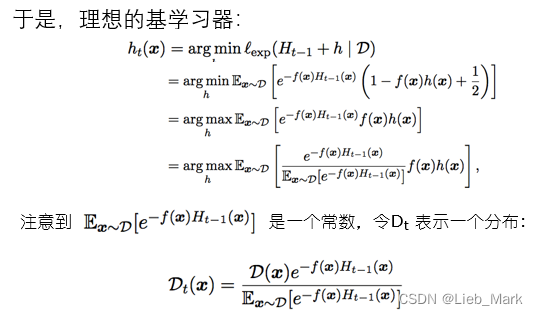
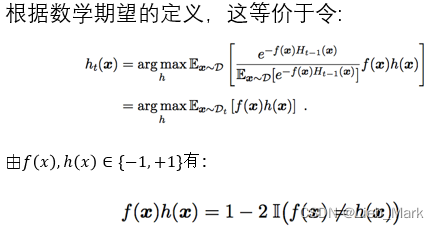

- 心得体会:
遇到的问题及解决:
- 使用readlines读出的数据集是字符串,而且每行都带有回车,刚开始处理的时候总是显示’’和\n不能转为float型。应当使用strip(‘\n’)去除回车,将中间的数据分开也比较麻烦,但是经过观察发现,各项之间是由空格分隔,使用spilt(‘ ’)即可。
- 书上没有提及基分类器如何选择,看到了西瓜书P177的图,上面的分类器是多个平行于x和y轴的线。经过思考,每个分类器并不需要效果很好,只要正确率超过50%即可,每个分类器只需要确定一条平行于x或y轴的线,多个分类器的线结合到一起就可以得出一个效果不错的非直线超平面,有点类似与用很多直线画出一个圆。
- 对于如何更新参数,书上说的不清晰,在知乎上找到了一个很清晰的文章,学习了集成学习的步骤和参数更新的公式:手把手教你AdaBoost - 知乎 (zhihu.com)
- 对于分类并不是只选出阈值,还要决定在阈值的上方是正例还是在下方是正例,否则情况覆盖不全面,分类效果不理想。
心得体会:
集成学习提供了很巧妙的思路,通过某种策略将多个模型集成起来,通过群体决策来提高决策准确率,这与以前优化单个分类器的思路很不一样。如线性分类器只能划分线性可分的数据,如果两个数据混合到一起,就要使用SVM在高维找到一个分类平面。但是集成学习可以使用多条直线,达到曲线分类平面的效果。
同时权重D的设置也十分巧妙,根据每次分类结果进行调整,错误数据权重增加,正确数据减小,这样在下个分类器中会对此重点关注。很好地利用了信息,使得分类器之间有相互联系,而不是每个都单独工作最后投票。
这次实验给我提供了机器学习解决分类问题的新思路,巩固所学知识,为以后的学习打下基础。
import numpy as np
import matplotlib.pyplot as plt
def load_data(path):
f = open(path)
lines = f.readlines()
data = []
lable = []
for line in lines:
line = line.strip('\n')
x = [float(num) for num in line.split(' ') if num != '' and num != '[' and num != ']']
data.append(x[:-1])
lable.append(x[-1])
return np.array(data), np.array(lable)
def G(data, lable, v, rule, D): # 传进来的data只有一列
res = []
e = 0
for i in range(data.shape[0]):
if rule == 0: # 0是小于阈值为正例
if data[i] < v:
res.append(1)
if (lable[i] != 1): # 分类错误就加上权重
e += D[i]
else:
res.append(-1)
if (lable[i] != -1):
e += D[i]
else:
if data[i] >= v: # 大于等于阈值为正例
res.append(1)
if (lable[i] != 1):
e += D[i]
else:
res.append(-1)
if (lable[i] != -1):
e += D[i]
return res, e
def single_classifier(data, lable, D):
info = {} # 当前该学习器用到的所有参数
info['e'] = 10000 # 初始化为一个不可能的
for feature in range(data.shape[1]): # 遍历所有属性,选择效果最好的属性及阈值
for v in np.unique(data[:, feature]): # 选择阈值
for rule in [0, 1]: # 选择是大于等于阈值为1,还是小于阈值为1
res, e = G(data[:, feature], lable, v, rule, D)
if e < info['e']:
info['e'] = e
info['feature'] = feature
info['v'] = v
info['rule'] = rule
info['res'] = res # 预测出的结果
return info
def adaboost(data, lable, num=10):
n, m = data.shape
D = [1 / n for i in range(n)] # 权重初始化为1/n,权重的和要为1
classifier = []
for i in range(num):
info = single_classifier(data, lable, D)
print(i, info)
res = info['res']
accuracy = np.sum(np.array([1 if res[j] == lable[j] else 0 for j in range(n)])) / n
if accuracy < 0.5: # 正确率小于0.5就要被抛弃
print("The classifier is not effective")
break
alpha = 1 / 2 * np.log((1 - info['e']) / info['e']) # log是以e为底的对数
info['alpha'] = alpha
D = np.multiply(D, np.exp(-1 * alpha * np.multiply(lable, info['res']))) / sum(D)
classifier.append(info)
return classifier
def test(data, lable, classifiers):
error = 0
n, m = data.shape
x1, y1, x2, y2 = [], [], [], []
for i in range(n):
sum = 0 # 投票和
for classifier in classifiers:
feature = classifier['feature']
v = classifier['v']
rule = classifier['rule']
alpha = classifier['alpha']
if rule == 0 and data[i][feature] < v or rule == 1 and data[i][feature] >= v:
sum += alpha * 1
elif rule == 0 and data[i][feature] >= v or rule == 1 and data[i][feature] < v:
sum += alpha * (-1)
if np.sign(sum) != lable[i]:
error += 1
if np.sign(sum) == 1:
x1.append(data[i][0])
y1.append(data[i][1])
else:
x2.append(data[i][0])
y2.append(data[i][1])
plt.figure()
plt.scatter(x1, y1, color='blue')
plt.scatter(x2, y2, color='red')
plt.show()
return error / n
if '__main__' == __name__:
train_data, train_lable = load_data(r'D:\pythonProject\Machine_learning\test7\train.txt')
test_data, test_lable = load_data(r'D:\pythonProject\Machine_learning\test7\test.txt')
m, n = np.shape(train_data)
classifier = adaboost(train_data, train_lable)
# error = test(train_data, train_lable, classifier)
error = test(test_data, test_lable, classifier)
print(1 - error)
















 2224
2224











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









