







本文来自:曹胜欢博客专栏。转载请注明出处:http://blog.csdn.NET/csh624366188
一:事务
首先看一下什么是事务:
通俗的理解,事务是一组原子操作单元,从数据库角度说,就是一组SQL指令,要么全部执行成功,若因为某个原因其中一条指令执行有错误,则撤销先前执行过的所有指令。更简答的说就是:要么全部执行成功,要么撤销不执行。
然后看一下事务要遵循的ISO/IEC所制定的ACID原则:
ACID是原子性(atomicity)、一致性(consistency)、隔离性(isolation)和持久性(durability)的缩写。
1.事务的原子性表示事务执行过程中的任何失败都将导致事务所做的任何修改失效。
2.一致性表示当事务执行失败时,所有被该事务影响的数据都应该恢复到事务执行前的状态。
3.隔离性表示在事务执行过程中对数据的修改,在事务提交之前对其他事务不可见。
4.持久性表示已提交的数据在事务执行失败时,数据的状态都应该正确。
看一下一些准备知识:
1.T-SQL使用下列语句来管理事务:
开始事务:BEGIN TRANSACTION
提交事务:COMMIT TRANSACTION
回滚(撤销)事务:ROLLBACK TRANSACTION
一旦事务提交或回滚,则事务结束。
2.判断某条语句执行是否出错:
使用全局变量@@ERROR
@@ERROR只能判断当前一条T-SQL语句执行是否有错,为了判断事务中所有T-SQL语句是否有错,我们需要对错误进行累计
如: SET @errorSum=@errorSum+@@error
了解一下事务的分类:
显示事务:用BEGIN TRANSACTION明确指定事务的开始,这是最常用的事务类型
隐性事务:通过设置SET IMPLICIT_TRANSACTIONS ON 语句,将隐性事务模式设置为打开,下一个语句自动启动一个新事务。当该事务完成时,再下一个 T-SQL 语句又将启动一个新事务
自动提交事务:这是 SQL Server 的默认模式,它将每条单独的 T-SQL 语句视为一个事务,如果成功执行,则自动提交;如果错误,则自动回滚
使用事务解决经典银行转账事务问题
T-SQL语句:
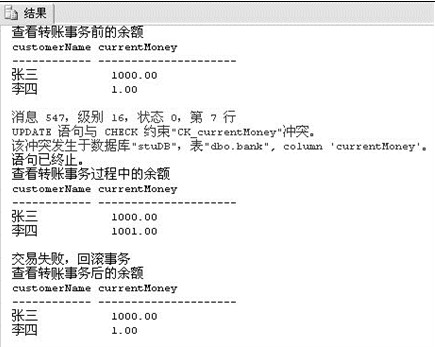
Javaj调用数据库事务方法在ava程序员从笨鸟到菜鸟之(七)一—java数据库操作
已经提到过了。在此就不在陈述了
二:索引
首先看一下什么事索引(以sqlserver为例):
SQL Server中的数据也是按页( 4KB )存放
索引:是SQL Server编排数据的内部方法。它为SQL Server提供一种方法来编排查询数据
索引页:数据库中存储索引的数据页;索引页类似于汉语字(词)典中按拼音或笔画排序的目录页
索引的作用:通过使用索引,可以大大提高数据库的检索速度,改善数据库性能
然后看一下索引的类型:
1.唯一索引:唯一索引不允许两行具有相同的索引值
2.主键索引:为表定义一个主键将自动创建主键索引,主键索引是唯一索引的特殊类型。主键索引要求主键中的每个值是唯一的,并且不能为空
3.聚集索引(Clustered):表中各行的物理顺序与键值的逻辑(索引)顺序相同,每个表只能有一个
4.非聚集索引(Non-clustered):非聚集索引指定表的逻辑顺序。数据存储在一个位置,索引存储在另一个位置,索引中包含指向数据存储位置的指针。可以有多个,小于249个
示例:利用企业管理器创建索引
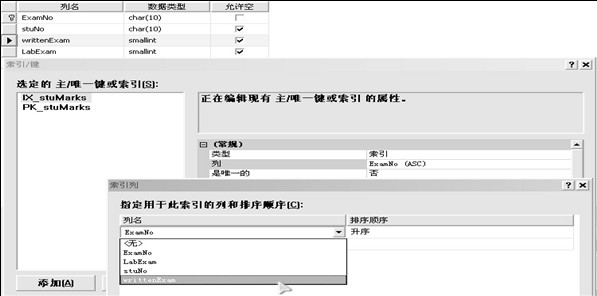
使用T-SQL语句创建索引的语法:
CREATE [UNIQUE] [CLUSTERED|NONCLUSTERED]
INDEX index_name
ON table_name (column_name…)
[WITH FILLFACTOR=x]
注:UNIQUE表示唯一索引,可选
CLUSTERED、NONCLUSTERED表示聚集索引还是非聚集索 引,可选
FILLFACTOR表示填充因子,指定一个0到100之间的值,
该值指示索引页填满的空间所占的百分比
创建索引示例:
索引的优缺点:
优点:1.加快访问速度2.加强行的唯一性
缺点:1.带索引的表在数据库中需要更多的存储空间
2.操纵数据的命令需要更长的处理时间,因为它们需要对索引进行更新
三:视图
首先还是先看一下什么事视图:
视图是一张虚拟表,它表示一张表的部分数据或多张表的综合数据,其结构和数据是建立在对表的查询基础上。视图中并不存放数据,而是存放在视图所引用的原始表(基表)中同一张原始表,根据不同用户的不同需求,可以创建不同的视图
使用企业管理器创建视图:
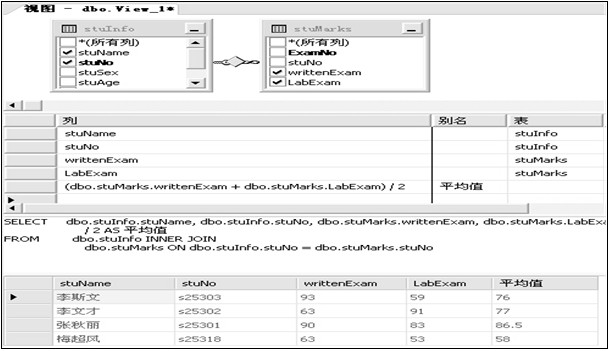
使用T-SQL语句创建视图的语法:
CREATE VIEW view_name
AS
<select语句>
示例:创建方便教员查看成绩的视图
四:存储过程:
首先还是来看一下什么事存储过程:
存储过程(Stored Procedure)是在大型数据库系统中,一组为了完成特定功能的SQL 语句集,经编译后存储在数据库中,用户通过指定存储过程的名字并给出参数(如果该存储过程带有参数)来执行它。
存储过程(procedure)类似于Java语言中的方法
用来执行管理任务或应用复杂的业务规则
存储过程可以带参数,也可以返回结果
存储过程的有点:
执行速度更快
允许模块化程序设计
提高系统安全性
减少网络流通量
存储过程分类:
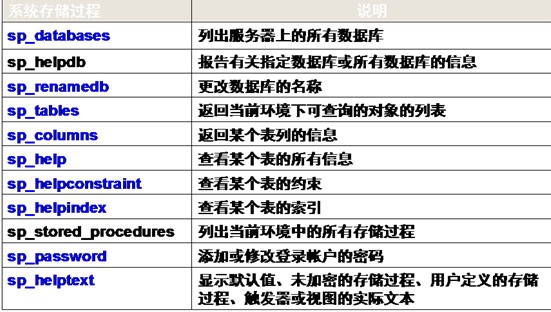
1.系统存储过程
由系统定义,存放在master数据库中,类似Java语言类库中的方法。
系统存储过程的名称都以“sp_”开头或“xp_”开头
2.用户自定义存储过程
由用户在自己的数据库中创建的存储过程,类似Java语言中用户自定义的方法
常用的系统存储过程
定义存储过程的语法
CREATE PROC[EDURE] 存储过程名
@参数1 数据类型 = 默认值 OUTPUT,
…… ,
@参数n 数据类型 = 默认值 OUTPUT
AS
SQL语句
和Java语言的方法一样,参数可选
参数分为输入参数、输出参数
输入参数允许有默认值
先给出一个不带输入参数的存储过程的例子:
执行存储过程的语法:
调用的语法
EXEC 过程名 [参数]
存储过程的参数分两种:1.输入参数2.输出参数
输入参数:用于向存储过程传入值,类似Java带参方法
输出参数:用于在调用存储过程后,返回结果
带输入参数的存储过程:
修改上例子:由于每次考试的难易程度不一样,每次笔试和机试的及格线可能随时变化(不再是60分),这导致考试的评判结果也相应变化
调用上面的存储过程:
EXEC proc_stu 60,55
--或这样调用:
EXEC proc_stu @labPass=55,@writtenPass=60
扩展:设置输入的默认值:
--或这样调用:
EXEC proc_stu
@labPass=55,
@writtenPass=60
CREATE PROCEDURE proc_stu
@writtenPass int=60,
@labPass int=60
AS
。。。。。。
调用带参数默认值的存储过程
EXEC proc_stu --都采用默认值
EXEC proc_stu 64 --机试采用默认值
EXEC proc_stu 60,55 --都不采用默认值
--错误的调用方式:希望笔试采用默认值,机试及格线55分
EXEC proc_stu ,55
--正确的调用方式:
EXEC proc_stu @labPass=55
如果希望调用存储过程后,返回一个或多个值,这时就需要使用输出(OUTPUT)参数了
调用带输出参数的存储过程
本文来自:曹胜欢博客专栏。转载请注明出处:http://blog.csdn.Net/csh624366188














 154
154











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









