








最近被逼看了点自然语言处理(NLP)的论文,好吧我看不懂,本来我就不是搞这个方向的,说的我迷迷糊糊的,哎,隔行如隔山啊
不过在过程中倒也是收获到了一些东西,比如今天的这篇博客,怎样自动的去产生图片的语句描述???
就是:
我给你张图,你给我自动生成描述这张图片的文字
具体如下:

这个理论说起来实际很高端,涉及到神经网络,自然语言处理等方方面面的知识,推荐几篇论文有兴趣的可以看看:
- Deep Visual-Semantic Alignments for Generating Image Descriptions
- how and Tell: A Neural Image Caption Generator
- Learning the Visual Interpretation of Sentences
- BringSemantics Into Focus Using Visual Abstraction
- Every Picture Tells a Story: Generating Sentences from Images
这里就不说具体是怎么实现的了,好吧,其实是我也看不懂。。。。。。。
NeuralTalk2
现在有开源的实现,具体理论来源于上面的论文1和2
NeuralTalk2是其开源的实现,大家可以看下它的安装要求,依赖还是很多的,由于使用了VGG16的网络,所以你需要一块GPU,什么???没有GPU????送你三个字:买买买
重要的事情要强调:CPU无法运行,必须上GPU
我的实验环境是:
CPU:Intel Xeon(4*3.3GHZ)
GPU:Titan X(12GB)
Memory:32GB(DDR4)
原始版本,NeuralTalk,是使用python编写,相比NeuralTalk,NeuralTalk2的不同点是:
Compared to the original NeuralTalk this implementation is batched, uses Torch, runs on a GPU, and supports CNN finetuning. All of these together result in quite a large increase in training speed for the Language Model (~100x), but overall not as much because we also have to forward a VGGNet. However, overall very good models can be trained in 2-3 days, and they show a much better performance.
安装依赖
依赖有一堆,我安装的时候就卡在了其中的某一个环节,好在最终还是解决了,这也是我写这篇博客的动力,希望有这个需求的人不要连安装都像我一样走了很多弯路,甚至都搞不定
主要就是按照README所说的去一步步安装:
安装Torch
$ curl -s https://raw.githubusercontent.com/torch/ezinstall/master/install-deps | bash
$ git clone https://github.com/torch/distro.git ~/torch --recursive
$ cd ~/torch;
$ ./install.sh # and enter "yes" at the end to modify your bashrc
$ source ~/.bashrc这个没什么说的,搞定以后,你会在你的额bashrc文件下看到类似这样的一行:
. /home/work-station/torch/install/bin/torch-activate
安装其它依赖
$ luarocks install nn
$ luarocks install nngraph
$ luarocks install image 安装CJson
cjson下载连接,先将它下载下来lua-cjson-2.1.0.tar.gz,之后解压,进入目录,安装即可
$ tar -xzvf lua-cjson-2.1.0.tar.gz
$ cd lua-cjson-2.1.0
$ luarocks make安装CUDA
CUDA下载地址,下载之后安装就可以,deb包很容易的,大家可以参照这个博客安装,几部就搞定了
安装CUDNN
我当时就是在这个位置出问题的,我的机子之前安装caffe的时候安装过cuda和cudnn,我把所有的都安装完,开始跑示例的时候,这个时候出错了:
These bindings are for version 4005 or above, while the loaded CuDNN is version: 4004
Are you using an older version of CuDNN?
意思很明显,就是cudnn版本低了
好吧,开始版本升级中,中间参照了这个帖子,但是依然没解决我的问题,最后终于让我搞定了,特此记录
Step 1:删除/usr/local/lib/下的所有以libcudnn开头的so文件和链接文件,比如libcudnn.so.7.0.58
Step 2:下载最新版本的cudnn,下载地址最后给出,首先要注册,过几天Nvidia才会给你下载权限
Step 3:假设你已经下载了最新版本的cudnn,假设是* cudnn-7.0-linux-x64-v4.0-prod.tgz*,不说了解压,进入cuda目录,执行:$ sudo cp include/* /usr/local/cuda/include/
$sudo cp lib64/* /usr/local/cuda/lib64/
搞定
安装loadcaffe
$ sudo apt-get install libprotobuf-dev protobuf-compiler
$ luarocks install loadcaffe安装h5py
$ sudo pip install h5py下载模型预测图片
模型下载地址,下载解压就可以
准备好你的图片,之后执行:
th eval.lua -model /path/to/model -image_folder /path/to/image/directory -num_images 10 写上你的model文件的路径和图片文件夹的路径,如果你想预测所有的图片将:
-num_images 10 改为-num_images -1
启动httpServer
预测之后会在你的vis文件夹下生成vis.json文件在imgs中会有你预测的图片:

启动server:
$ cd vis
$ python -m SimpleHTTPServer浏览器访问:
localhost:8000,就可以看见了
我的结果
我随机从百度上下了6个图片,预测结果是这样的:
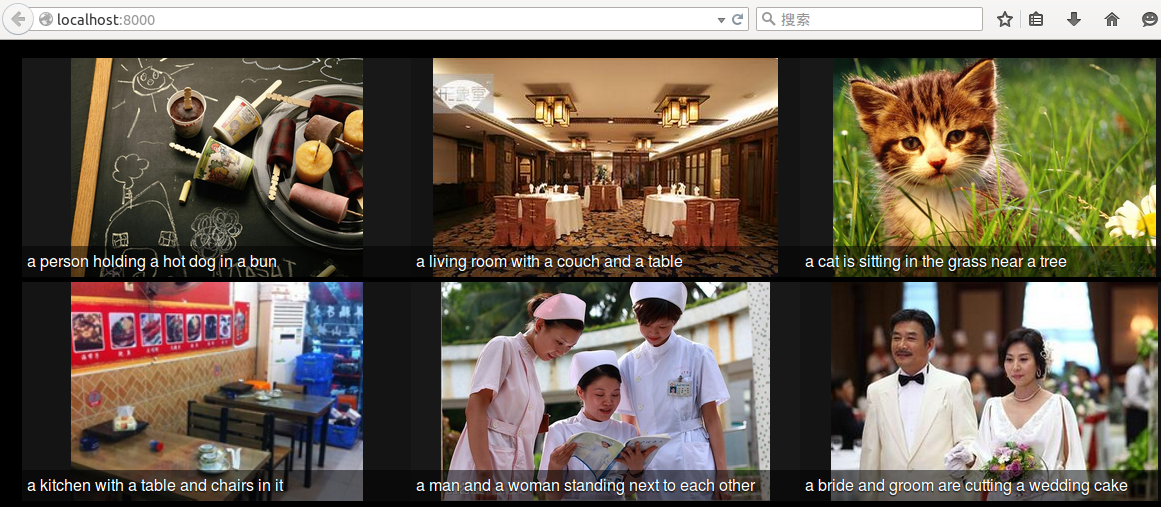
看的出来,结果还是很准的














 1536
1536











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









